爬虫Jsoup小结
2016-04-06 16:44
375 查看
首先调一个通用的方法,通过html地址得到Html内容
对象转换:
常用的解析方式:
1、Element node = doc.getElementById("tab1");
样板:<liclass="active"id="tab1">
2、Elements nodes = doc.getElementsByClass("currency-value");
样板:<spanclass='currency-value'>18.00</span>
3、Elements nodes = doc.select("h1 span");
样板:<h1><span>我是标题</span></h1>
Elements nodes = doc.select("h1");
样板:<h1>我是标题</h1>
上面的这两种情况必须要保证整个页面只有单个的H1,如果存在多个的话,可以加上frist(),即doc.select("h1").first()
Elements nodes = doc.select("h1[class=product_name]");
样板:<h1><span class="product_name">我是标题</span></h1>
有的网站把Sku信息藏在json中,这种数据的话,就需要截取:
比如:https://www.me-dusa.com/products/dominik-wallet-green

String start = "var __st=";
String end = ");";
int pos1 = html.indexOf(start) + start.length();
int pos2 = html.indexOf(end, pos1);
String text = html.substring(pos1, pos2);
更有的是通过点击页面上的加载得到sku,这种是最难找的,之前我都不会弄!!
像这个网址:http://www.anthropologie.com/anthro/product/accessories-jewelry/38666012.jsp#/
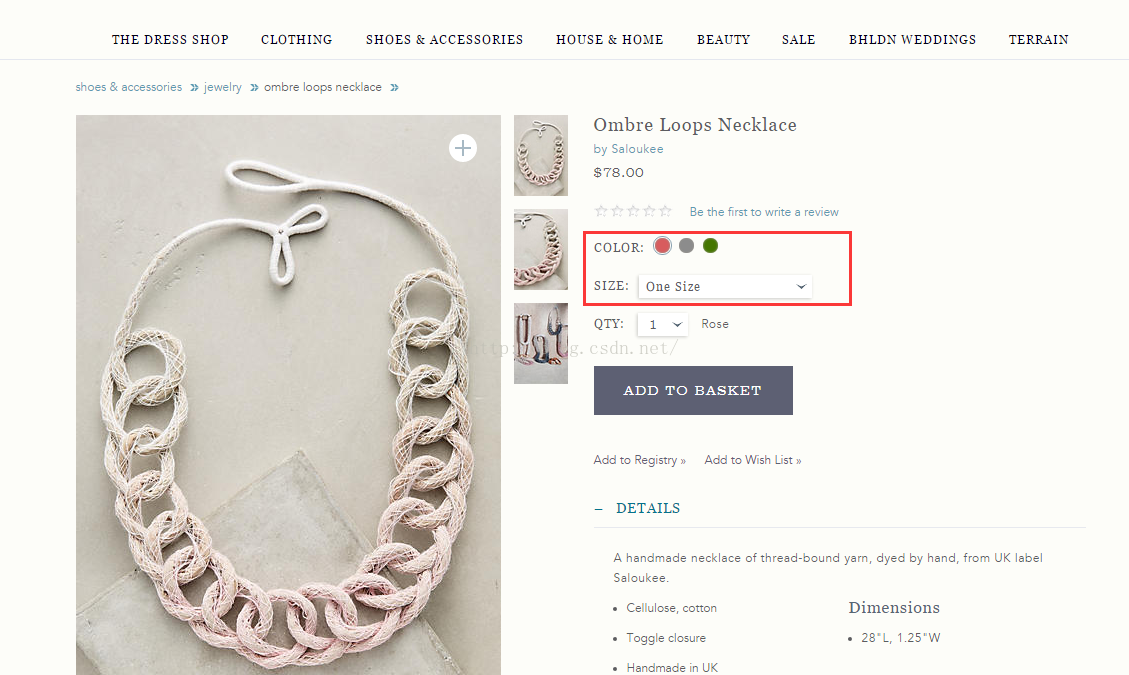
它的颜色,尺码旧藏的比较深:页面上出现了大写的COLOR,然后你查看它的源代码的时候,发现根本就没有!!!!!
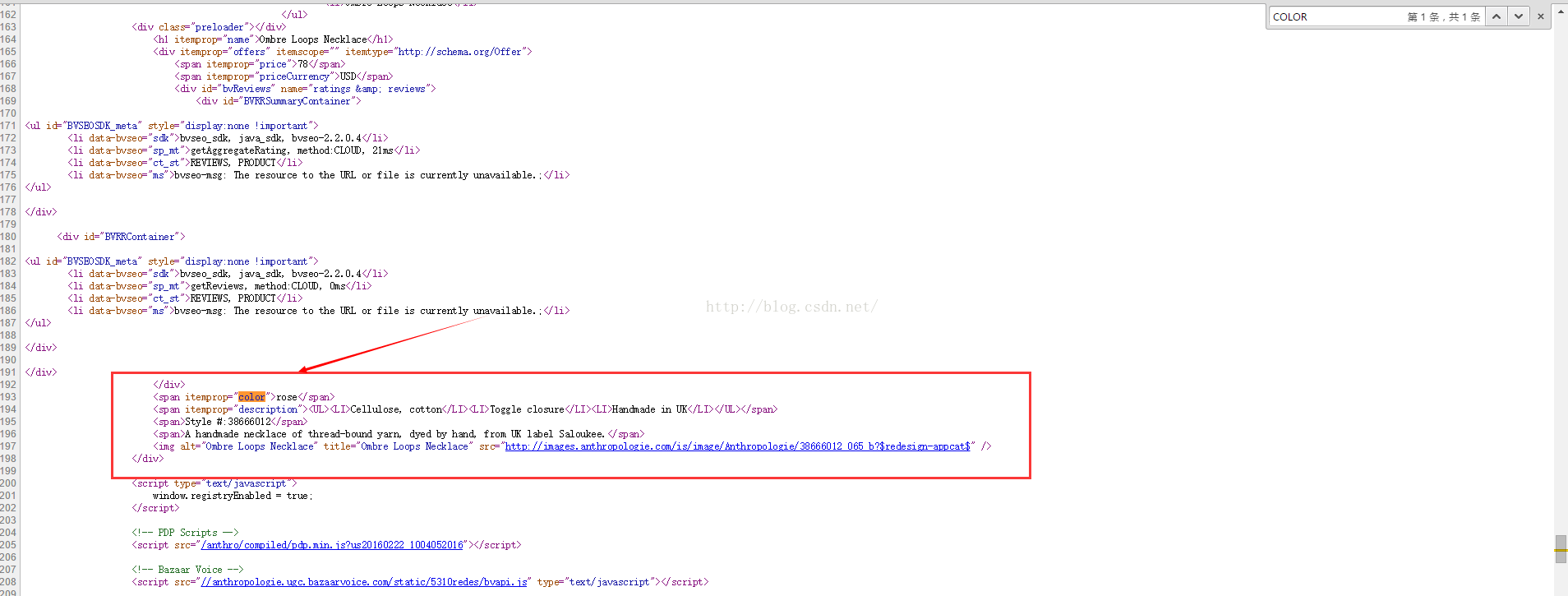
这个时候:F12,在选项卡Network下重新加载页面,然后就会有很多的图片,样式,js等等,一个个点看,办法有点蠢,但是这样有效果了
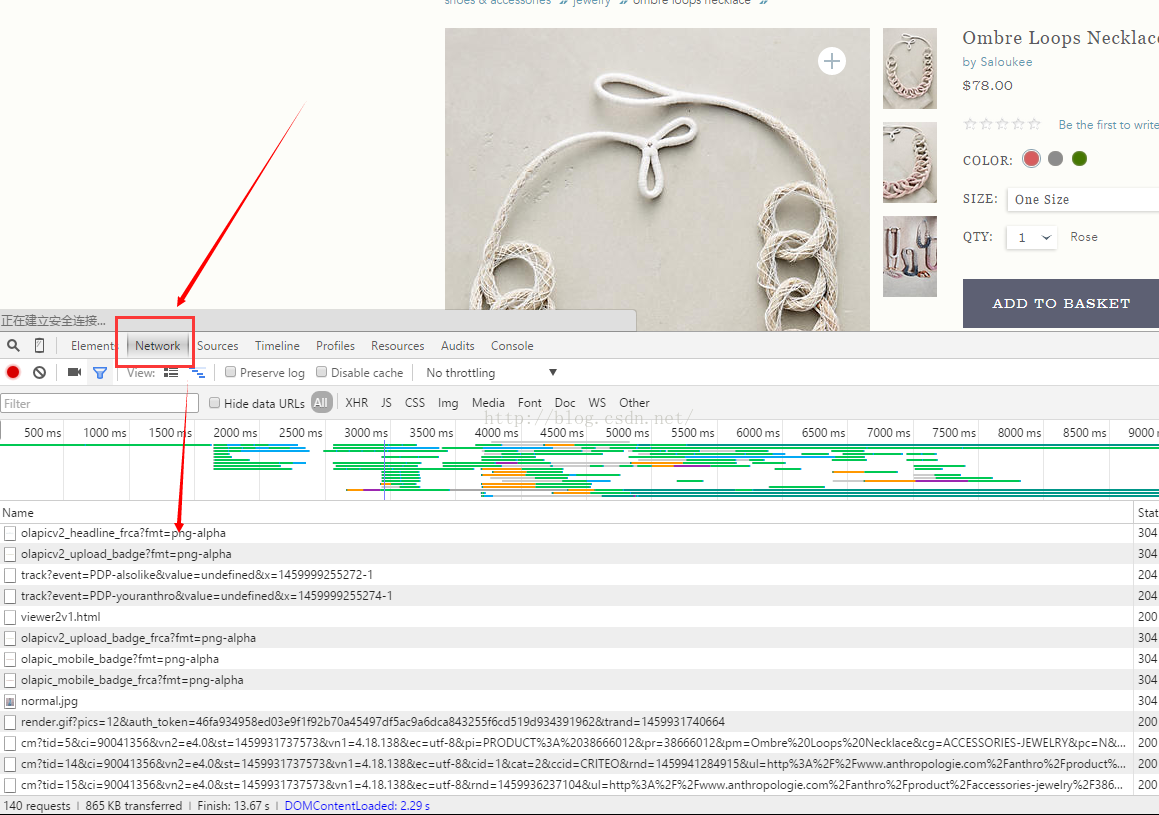
然后我们发现这个网站他们其实是调接口了:http://www.anthropologie.com/api/v1/anthro/product/37800489
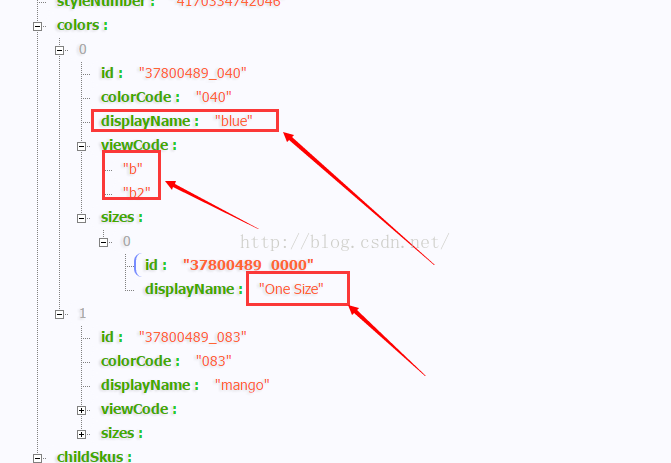
那么知道了这个规律接下来就是解析json,这个是我最擅长的,哈哈~高兴死我了!!!
这样对爬虫也算有了一个大大的帮助,懂了这个规律,N多的问题也就能迎刃而解了~~
String html = "";
try{
//优先执行
html = HttpPageDownload.loadHtml(url);
}catch(Exception ex){
//再来用原始方法获取网页内容
html = HttpPageDownload.getContnet(url);
}对象转换:
Document doc = Jsoup.parse(html);
常用的解析方式:
1、Element node = doc.getElementById("tab1");
样板:<liclass="active"id="tab1">
2、Elements nodes = doc.getElementsByClass("currency-value");
样板:<spanclass='currency-value'>18.00</span>
3、Elements nodes = doc.select("h1 span");
样板:<h1><span>我是标题</span></h1>
Elements nodes = doc.select("h1");
样板:<h1>我是标题</h1>
上面的这两种情况必须要保证整个页面只有单个的H1,如果存在多个的话,可以加上frist(),即doc.select("h1").first()
Elements nodes = doc.select("h1[class=product_name]");
样板:<h1><span class="product_name">我是标题</span></h1>
有的网站把Sku信息藏在json中,这种数据的话,就需要截取:
比如:https://www.me-dusa.com/products/dominik-wallet-green
String start = "var __st=";
String end = ");";
int pos1 = html.indexOf(start) + start.length();
int pos2 = html.indexOf(end, pos1);
String text = html.substring(pos1, pos2);
{
"a": 6238733,
"offset": 10800,
"reqid": "1dfccb66-5370-4f8c-a177-a18a5182ff1c",
"pageurl": "www.me-dusa.com/collections/shoulder-bags/products/felissya-shoulder-bag-black",
"u": "3373614c12cc",
"p": "product",
"rtyp": "product",
"rid": 363247743
}更有的是通过点击页面上的加载得到sku,这种是最难找的,之前我都不会弄!!
像这个网址:http://www.anthropologie.com/anthro/product/accessories-jewelry/38666012.jsp#/
它的颜色,尺码旧藏的比较深:页面上出现了大写的COLOR,然后你查看它的源代码的时候,发现根本就没有!!!!!
这个时候:F12,在选项卡Network下重新加载页面,然后就会有很多的图片,样式,js等等,一个个点看,办法有点蠢,但是这样有效果了
然后我们发现这个网站他们其实是调接口了:http://www.anthropologie.com/api/v1/anthro/product/37800489
那么知道了这个规律接下来就是解析json,这个是我最擅长的,哈哈~高兴死我了!!!
private static JSONObject getDataJosn(String productId){
String apiUrl = "http://www.anthropologie.com/api/v1/anthro/product/"+productId;
try {
String result = JsonLoadUtils.loadJson(apiUrl);
if(!StringUtils.isEmpty(result)){
JSONObject jsonObject = JSONObject.fromObject(result);
return jsonObject;
}
}catch(Exception e){
e.printStackTrace();
}
return null;
}
/**
* 获取图片categoryId
* URL:http://www.anthropologie.com/api/v1/anthro/product/${productId}
* skuInfo中有个stockLevel,如果此值为0,就爬取color中下一个colorId
*
* 对应的URL说明:http://www.anthropologie.com/anthro/product/shopsale-jewelry/37800489.jsp#/
*
* 推测:如果url中没有带color,说明,①该件商品仅剩下单个sku,排除stockLevel=0,剩下的唯一就是本次需要返回的值
* ②直接取第一个color(默认的即可)
*
* **如果URL中带有color,以自带的color为准**
* @param productId
* @return
*/
private static String getColorCode(JSONObject jsonObject){
String colorCode = "";
try {
if(jsonObject!=null&&jsonObject.containsKey("product")){
jsonObject = jsonObject.getJSONObject("product");
JSONArray arraySkuInfo = jsonObject.getJSONArray("skusInfo");
if(arraySkuInfo!=null&&arraySkuInfo.size()>0){
for (int i = arraySkuInfo.size()-1; i >= 0 ; i--) {
jsonObject = arraySkuInfo.getJSONObject(i);
if(jsonObject!=null&&jsonObject.containsKey("stockLevel")&&jsonObject.getInt("stockLevel")>0){
colorCode = jsonObject.getString("colorId");
break;
}
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
return colorCode;
}
/**
* 准确下载出图片
* @param jsonObject
* @return
*/
private static String getImgList(String productId,String colorCode,JSONObject jsonObject){
String imgStr = "";
try {
if(jsonObject!=null&&jsonObject.containsKey("product")&&!StringUtils.isEmpty(colorCode)){
jsonObject = jsonObject.getJSONObject("product");
JSONArray arrayColor = jsonObject.getJSONArray("colors");
if(arrayColor!=null&&arrayColor.size()>0){
List<String> viewCodeStr = null;
for (int i = 0; i < arrayColor.size(); i++) {
jsonObject = arrayColor.getJSONObject(i);
if(colorCode.equals(jsonObject.getString("colorCode"))){
String temp = jsonObject.getString("viewCode");
viewCodeStr = JSON.parseArray(temp, String.class);
break;
}
}
if(viewCodeStr!=null&&viewCodeStr.size()>0){
String imgSrc = "";
String fileName = "";
String filePath = "";
String imgPrefix = "http://images.anthropologie.com/is/image/Anthropologie";
//http://images.anthropologie.com/is/image/Anthropologie/37800489_083_b?$pdp-detail-shot$
for (int i = 0; i < viewCodeStr.size(); i++) {
//第一张图片是
//System.out.println("图片是:"+src.select("img").attr("data-large"));
//图片网络地址 http://images.anthropologie.com/is/image/Anthropologie/37579299_070_b3?$pdp-detail-shot$ imgSrc = imgPrefix + "/"+productId+"_"+colorCode+"_"+viewCodeStr.get(i)+"?$pdp-detail-shot$";//第一张
//System.out.println("图片是:"+imgSrc);
//文件夹路径
filePath = spiderDirPath + CommonUtil.formatDate(new Date(), "yyyyMMdd");
//文件名称
fileName = CommonUtil.formatDateyyyymmddhhmmssSSS(new Date()) + i + ".png";
imgStr += ImageDownloadUtils.downloadImgByNet(imgSrc, filePath, fileName) + ",";
}
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
return imgStr;
}这样对爬虫也算有了一个大大的帮助,懂了这个规律,N多的问题也就能迎刃而解了~~

相关文章推荐
- BOOST JSON 数组解析
- 通过JS简单实现图片缩放
- jsp入门(一个菜鸟的搬砖历程
- JS两种方案解决跨域问题
- Device and Viewport Size In JavaScript
- JS 数组去重
- EL表达式获取地址栏地址以及jsp如何获取服务器信息
- EL表达式获取地址栏地址以及jsp如何获取服务器信息
- JavaScript中的slice函数
- JS中0跟""比较
- js的for..in语句的用法详解
- js图片滚动
- JS中六种数据类型(一)――undefined
- js事件冒泡和捕获
- js时间 字符串相互转化
- jsp与servlet
- VS 2008 jsoncpp的配置及使用实例
- js将类数组转成数组
- Javascript写入txt和读取txt文件示例
- JSON详解