hadoop启动后,长久不用,无法关闭
2016-04-05 20:14
309 查看
上次配好了hadoop的环境,已经大概过去一周了,查看hadoop的运行情况:
上次配好了hadoop的环境,已经大概过去一周了,查看hadoop的运行情况: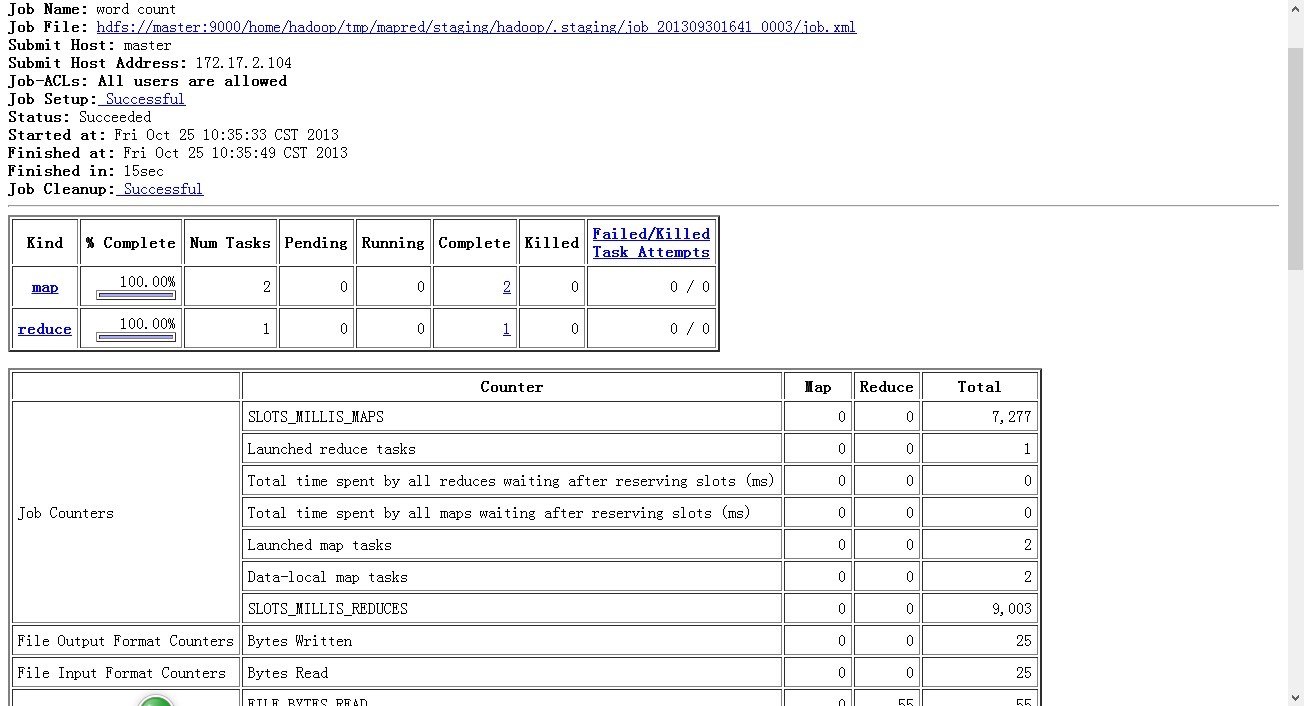 在master节点上查看jps状态: 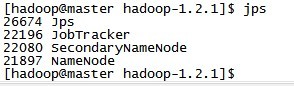 执行停止命令的时候发现下面情况: 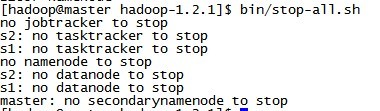 在网上查了一些资料觉得下面的解释比较靠谱: 出现这个问题的最常见原因是hadoop在stop的时候依据的是datanode上的mapred和dfs进程号。而默认的进程号保存在/tmp下,linux默认会每隔一段时间(一般是一个月或者7天左右)去删除这个目录下的文件。因此删掉hadoop-hadoop-jobtracker.pid和hadoop-hadoop-namenode.pid两个文件后,namenode自然就找不到datanode上的这两个进程了。 另外还有两个原因可能引起这个问题: 1:环境变量 $HADOOP_PID_DIR 在你启动hadoop后改变了 2:用另外的用户身份执行stop-all 解决方法: 1:永久解决方法,修改$HADOOP_HOME/conf/hadoop-env.sh里边,去掉export HADOOP_PID_DIR=/var/hadoop/pids的#号,创建/var/hadoop/pids或者你自己指定目录 发现问题后的解决方法: 1:这个时候通过脚本已经无法停止进程了,不过我们可以手工停止,方法是到各mfs master和各datanode执行ps -ef | grep java | grep hadoop找到进程号强制杀掉,然后在master执行start-all脚本重新启动,就能正常启动和关闭了。 |

相关文章推荐
- 同步和互斥
- Linux内存布局
- Nginx的负载均衡 - 加权轮询 (Weighted Round Robin) 下篇
- Docker安装(在Ubuntu中安装Docker)
- Nginx的负载均衡 - 加权轮询 (Weighted Round Robin) 上篇
- centos 7 安装nginx
- 一个简单的Linux驱动示例
- Linux内核分析 读书笔记 (第三章)
- Nginx的负载均衡 - 最少连接 (least_conn)
- Nginx的负载均衡 - 保持会话 (ip_hash)
- Opencv学习笔记——release和debug两个模式的运行问题
- Linux内核启动过程
- Opencv学习笔记——release和debug两个模式的运行问题
- Linux替换文本字符串(Vim编辑器中使用)
- 微服务实战(一):微服务架构的优势与不足
- Nginx的负载均衡 - 一致性哈希 (Consistent Hash)
- 【Data Algorithms_Recipes for Scaling up with Hadoop and Spark】Chapter 12. K-Means Clustering
- Odoo8.0不能创建客户问题的解决 Document type: res.partner, Operation: read
- [原创] hadoop学习笔记:重新格式化HDFS文件系统
- Linux系统的命令源代码的获取方法