spark解决方案系列--------1.spark-streaming实时Join存储在HDFS大量数据的解决方案
2016-03-30 10:05
603 查看
spark-streaming实时接收数据并处理。一个非常广泛的需求是spark-streaming实时接收的数据需要跟保存在HDFS上的大量数据进行Join。要实现这个需求保证实时性需要解决以下几个问题:
1.spark-streaming的数据接收间隔往往很小,比如只有几秒钟。HDFS上的数据往往很大,不能每个batch都从HDFS读取数据,避免频繁大量磁盘I/O。HDFS的数据也可能会改变,只是改变后数据加载周期比spark-streaming的batch时间要长。
2.Cache到内存的数据,不能在streaming的一个batch处理结束之后被回收。
3.HDFS大量数据在跟Kafka等实时接收的数据进行Join的时候不能shuffle。如果发生shuffle,由于HDFS中数据非常大,势必会影响实时性。
4.HDFS加载到内存中的数据,不能频繁Checkpoint到磁盘。
一个Spark-streaming application可以创建多个InputDStream,但是所有的InputDStream的数据接收时间间隔必须相同,因为数据接收间隔设置在了StreamingContext上。因此为了解决上面提到的第一个问题,需要实现一个自定义InputDStream。这个InputDStream需要将从HDFS上读取的数据Cache到内存,并且将Cache到内存的数据从前一个DStream传递到下一个DStream。
Spark-streaming在每个batch创建了RDD之后,如果DStream的StorageLevel不为None会设置DStream的RDD的StorageLevel,源码如下:
因此设置自定义InputDStream的StorageLevel为MEMORY_ONLY或者MEMORY_ONLY_SER可以解决HDFS数据cache到内存的问题。相关源码为:
一个Spark-streaming batch处理结束之后,会发送ClearMetadata事件来清除这个batch的数据,具体源码如下:
从上面的代码可知,当一个batch处理结束之后,会将remeberDuration时间间隔之前的RDD删除,并且将这个RDD在BlockManager中占用的内存块释放。所以通过设置自定义InputDStream的remeberDuration来防止一个batch产生的RDD马上被释放。
Spark-streaming每个batch都会产生RDD,为了避免每个Batch都从HDFS加载文件产生RDD,需要将HDFS中大文件产生的RDD在前后的DStream进行传递,因此在自定义InputDStream中定义一个成员变量,记录已经生成的RDD,并且这个成员变量只有在rememberDuration时间间隔才会发生改变。自定义InputDStream的compute方法定义为:
在上面的方法中,从HDFS读取数据生成的RDD的周期为durationToRemember,并且从HDFS读取数据生成的RDD保存在了自定义InputDStream的remeberRDDs成员。如果时间还没有达到durationToRemember则将remeberRDDs中保存的RDD作为这个batch产生的HadoopRDD,这样达到了RDD在前后DStream的传递,避免了频繁的读取HDFS数据。另外这个自定义DStream是仿照FileInputDStream类写的,它借鉴了FileInputDStream.compute方法对目录文件的监控,在一个[b]durationToRemember周期加载一次监控目录的所有文件产生RDD。[/b]
最终的实现效果如下图所示:
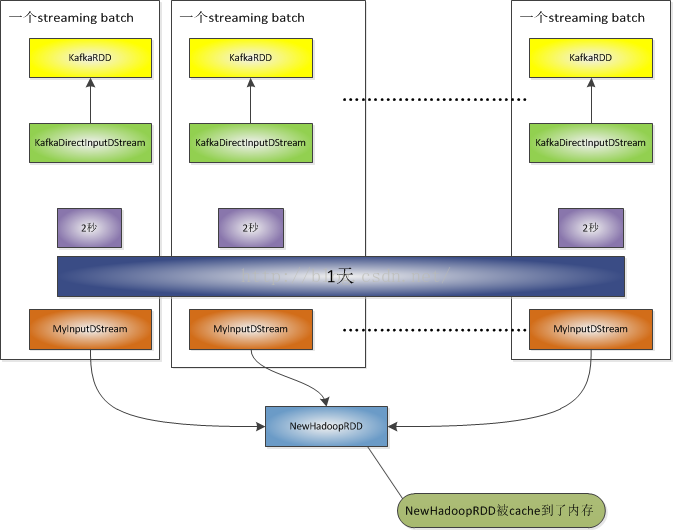
在上图中,spark-streaming DStream的产生batch是2秒,但是NewHadoopRDD 1天才生成一次,并且Cache到了内存。在1天的remeberDuration时间间隔内不同的MyInputDSteam使用相同的NewHadoopRDD.
为了避免进行join的时候发生shuffle,将Kafka DStream每个batch的数据broadcast,进行join。测试代码如下:
自定义InputDStream的filesToRDD 方法将所有文件转化成RDD,源码如下:
因为NewHadoopRDD每个元素都占用了同一块内存,所以必须复制每个元素的k、v才能将这个RDD cache到内存
从上面的方法知道,filesToRDD返回的RDD并不是根RDD(根据NewHadoopRDD创建了UnionRDD),这个RDD也是自定义InputDStream的compute方法返回的RDD。
spark-streaming的DSteam.getOrCompute方法将compute返回的RDD checkpoint到HDFS,源码如下:
如果设置了checkpoint,则将DStream的compute方法产生的RDD checkpoint到HDFS。
这个UnionRDD cache到了内存,但是如果发生checkpoint,会把这个UnionRDD写到磁盘,这样也会引起大量的磁盘I/O,为了解决这个问题,这个解决方案不能设置checkpoint。如果需要checkpoint,需要将KafkaDirectDStream每个Kafka分区的偏移量同步到zookeeper,每次程序重启的时候从zookeeper获取KafkaDirectDStream上一次读取到的位置。
1.spark-streaming的数据接收间隔往往很小,比如只有几秒钟。HDFS上的数据往往很大,不能每个batch都从HDFS读取数据,避免频繁大量磁盘I/O。HDFS的数据也可能会改变,只是改变后数据加载周期比spark-streaming的batch时间要长。
2.Cache到内存的数据,不能在streaming的一个batch处理结束之后被回收。
3.HDFS大量数据在跟Kafka等实时接收的数据进行Join的时候不能shuffle。如果发生shuffle,由于HDFS中数据非常大,势必会影响实时性。
4.HDFS加载到内存中的数据,不能频繁Checkpoint到磁盘。
一个Spark-streaming application可以创建多个InputDStream,但是所有的InputDStream的数据接收时间间隔必须相同,因为数据接收间隔设置在了StreamingContext上。因此为了解决上面提到的第一个问题,需要实现一个自定义InputDStream。这个InputDStream需要将从HDFS上读取的数据Cache到内存,并且将Cache到内存的数据从前一个DStream传递到下一个DStream。
Spark-streaming在每个batch创建了RDD之后,如果DStream的StorageLevel不为None会设置DStream的RDD的StorageLevel,源码如下:
private[streaming] final def getOrCompute(time: Time): Option[RDD[T]] = {
// If RDD was already generated, then retrieve it from HashMap,
// or else compute the RDD
generatedRDDs.get(time).orElse {
// Compute the RDD if time is valid (e.g. correct time in a sliding window)
// of RDD generation, else generate nothing.
if (isTimeValid(time)) {
val rddOption = createRDDWithLocalProperties(time, displayInnerRDDOps = false) {
// Disable checks for existing output directories in jobs launched by the streaming
// scheduler, since we may need to write output to an existing directory during checkpoint
// recovery; see SPARK-4835 for more details. We need to have this call here because
// compute() might cause Spark jobs to be launched.
PairRDDFunctions.disableOutputSpecValidation.withValue(true) {
compute(time)
}
}
rddOption.foreach { case newRDD =>
// Register the generated RDD for caching and checkpointing
if (storageLevel != StorageLevel.NONE) {//设置DStream对应RDD的存储级别
newRDD.persist(storageLevel)
logDebug(s"Persisting RDD ${newRDD.id} for time $time to $storageLevel")
}
if (checkpointDuration != null && (time - zeroTime).isMultipleOf(checkpointDuration)) {
newRDD.checkpoint()
logInfo(s"Marking RDD ${newRDD.id} for time $time for checkpointing")
}
generatedRDDs.put(time, newRDD)
}
rddOption
} else {
None
}
}
}因此设置自定义InputDStream的StorageLevel为MEMORY_ONLY或者MEMORY_ONLY_SER可以解决HDFS数据cache到内存的问题。相关源码为:
storageLevel = StorageLevel.MEMORY_ONLY
一个Spark-streaming batch处理结束之后,会发送ClearMetadata事件来清除这个batch的数据,具体源码如下:
private[streaming] def clearMetadata(time: Time) {
val unpersistData = ssc.conf.getBoolean("spark.streaming.unpersist", true)
val oldRDDs = generatedRDDs.filter(_._1 <= (time - rememberDuration))//清除remeberDuration时间间隔之前的RDD
logDebug("Clearing references to old RDDs: [" +
oldRDDs.map(x => s"${x._1} -> ${x._2.id}").mkString(", ") + "]")
generatedRDDs --= oldRDDs.keys
if (unpersistData) {
logDebug("Unpersisting old RDDs: " + oldRDDs.values.map(_.id).mkString(", "))
oldRDDs.values.foreach { rdd =>
rdd.unpersist(false)
// Explicitly remove blocks of BlockRDD
rdd match {
case b: BlockRDD[_] =>
logInfo("Removing blocks of RDD " + b + " of time " + time)
b.removeBlocks()//将RDD占用的内存块从BlockManager释放
case _ =>
}
}
}
logDebug("Cleared " + oldRDDs.size + " RDDs that were older than " +
(time - rememberDuration) + ": " + oldRDDs.keys.mkString(", "))
dependencies.foreach(_.clearMetadata(time))
}从上面的代码可知,当一个batch处理结束之后,会将remeberDuration时间间隔之前的RDD删除,并且将这个RDD在BlockManager中占用的内存块释放。所以通过设置自定义InputDStream的remeberDuration来防止一个batch产生的RDD马上被释放。
Spark-streaming每个batch都会产生RDD,为了避免每个Batch都从HDFS加载文件产生RDD,需要将HDFS中大文件产生的RDD在前后的DStream进行传递,因此在自定义InputDStream中定义一个成员变量,记录已经生成的RDD,并且这个成员变量只有在rememberDuration时间间隔才会发生改变。自定义InputDStream的compute方法定义为:
override def compute(validTime: Time): Option[RDD[(K, V)]] = {
// Find new files
if (rddGenerateTime == 0 || Duration(validTime.milliseconds - rddGenerateTime) >= durationToRemember){//从HDFS读取数据生成的RDD的周期为durationToRemember
val newFiles = findNewFiles(validTime.milliseconds)//这个方法会加载目录里面的所有文件
logInfo("New files at time " + validTime + ":\n" + newFiles.mkString("\n"))
val rdds = Some(filesToRDD(newFiles))
rddGenerateTime = validTime.milliseconds//记录从HDFS读取数据的时间
val metadata = Map(
"files" -> newFiles.toList,
StreamInputInfo.METADATA_KEY_DESCRIPTION -> newFiles.mkString("\n"))
val inputInfo = StreamInputInfo(id, 0, metadata)
ssc.scheduler.inputInfoTracker.reportInfo(validTime, inputInfo)
rememberRDDs = rdds//记录从HDFS读取数据生成的RDD
rdds
}else {
/*
这样在DStream.getOrCompute方法里面会把这个RDD重复的放入generateRDDs这个HashMap里面.不过没有关系,因为generateRDDs里面的RDD
在超过rememberDuration之后会将RDD从generateRDDs里面删除,并且将RDD所占用的内存块也删除。在实际执行的时候不会发生重复删除内存块,因为删除内存块之前会先检查内存块是否存在
第一次删除之后,
以后再删除的时候发现内存块已经不存在了,会直接返回,不会重复删除
*/
//useRememberRDDTime = validTime.milliseconds
rememberRDDs
}
}在上面的方法中,从HDFS读取数据生成的RDD的周期为durationToRemember,并且从HDFS读取数据生成的RDD保存在了自定义InputDStream的remeberRDDs成员。如果时间还没有达到durationToRemember则将remeberRDDs中保存的RDD作为这个batch产生的HadoopRDD,这样达到了RDD在前后DStream的传递,避免了频繁的读取HDFS数据。另外这个自定义DStream是仿照FileInputDStream类写的,它借鉴了FileInputDStream.compute方法对目录文件的监控,在一个[b]durationToRemember周期加载一次监控目录的所有文件产生RDD。[/b]
最终的实现效果如下图所示:
在上图中,spark-streaming DStream的产生batch是2秒,但是NewHadoopRDD 1天才生成一次,并且Cache到了内存。在1天的remeberDuration时间间隔内不同的MyInputDSteam使用相同的NewHadoopRDD.
为了避免进行join的时候发生shuffle,将Kafka DStream每个batch的数据broadcast,进行join。测试代码如下:
kafkaMessages.transformWith[(String, String), (String, String, String)](hadoopMessages, (kafkaRDD:RDD[(String, String)], fileRDD:RDD[(String, String)]) =>{
val sqlContext = SQLContextSingleton.getInstance(kafkaRDD.sparkContext)
import sqlContext.implicits._
val kafkaDf = kafkaRDD.map{case (ip, str) =>KafkaObj(ip, str)}.toDF
//kafkaDf.registerTempTable("kafkatable")
val fileDf = fileRDD.map{case (ip, str) =>FileObj(ip, str)}.toDF
fileDf.join(broadcast(kafkaDf), "ip").rdd.map(row =>{
(row.get(0).toString, row.get(1).toString, row.get(2).toString)
})
})自定义InputDStream的filesToRDD 方法将所有文件转化成RDD,源码如下:
private def filesToRDD(files: Seq[String]): RDD[(K, V)] = {
val fileRDDs = files.map { file =>
val rdd = serializableConfOpt.map(_.value) match {
case Some(config) => {
context.sparkContext.newAPIHadoopFile(
file,
fm.runtimeClass.asInstanceOf[Class[F]],
km.runtimeClass.asInstanceOf[Class[K]],
vm.runtimeClass.asInstanceOf[Class[V]],
config)
.map { case (k, v) =>
val newKey = new LongWritable(k.asInstanceOf[LongWritable].get).asInstanceOf[K]
val newText = new Text(v.asInstanceOf[Text].toString).asInstanceOf[V]
(newKey, newText)//因为NewHadoopRDD每个元素都占用了同一块内存,所以必须复制每个元素的k、v才能将这个RDD cache到内存
}
}
case None => {
context.sparkContext.newAPIHadoopFile[K, V, F](file)
.map{case (k, v) =>
val newKey =new LongWritable(k.asInstanceOf[LongWritable].get).asInstanceOf[K]
val newText = new Text(v.asInstanceOf[Text].toString).asInstanceOf[V]
(newKey, newText)<span style="font-family: Arial, Helvetica, sans-serif;">//因为NewHadoopRDD每个元素都占用了同一块内存,所以必须复制每个元素的k、v才能将这个RDD cache到内存</span>
}
}
}
if (rdd.partitions.size == 0) {
logError("File " + file + " has no data in it. Spark Streaming can only ingest " +
"files that have been \"moved\" to the directory assigned to the file stream. " +
"Refer to the streaming programming guide for more details.")
}
rdd
}
new UnionRDD(context.sparkContext, fileRDDs)
}因为NewHadoopRDD每个元素都占用了同一块内存,所以必须复制每个元素的k、v才能将这个RDD cache到内存
从上面的方法知道,filesToRDD返回的RDD并不是根RDD(根据NewHadoopRDD创建了UnionRDD),这个RDD也是自定义InputDStream的compute方法返回的RDD。
spark-streaming的DSteam.getOrCompute方法将compute返回的RDD checkpoint到HDFS,源码如下:
private[streaming] final def getOrCompute(time: Time): Option[RDD[T]] = {
// If RDD was already generated, then retrieve it from HashMap,
// or else compute the RDD
generatedRDDs.get(time).orElse {
// Compute the RDD if time is valid (e.g. correct time in a sliding window)
// of RDD generation, else generate nothing.
if (isTimeValid(time)) {
val rddOption = createRDDWithLocalProperties(time, displayInnerRDDOps = false) {
// Disable checks for existing output directories in jobs launched by the streaming
// scheduler, since we may need to write output to an existing directory during checkpoint
// recovery; see SPARK-4835 for more details. We need to have this call here because
// compute() might cause Spark jobs to be launched.
PairRDDFunctions.disableOutputSpecValidation.withValue(true) {
compute(time)
}
}
rddOption.foreach { case newRDD =>
// Register the generated RDD for caching and checkpointing
if (storageLevel != StorageLevel.NONE) {
newRDD.persist(storageLevel)
logDebug(s"Persisting RDD ${newRDD.id} for time $time to $storageLevel")
}
if (checkpointDuration != null && (time - zeroTime).isMultipleOf(checkpointDuration)) {
newRDD.checkpoint()//将DStream的compute方法产生的RDD checkpoint到HDFS
logInfo(s"Marking RDD ${newRDD.id} for time $time for checkpointing")
}
generatedRDDs.put(time, newRDD)
}
rddOption
} else {
None
}
}
}如果设置了checkpoint,则将DStream的compute方法产生的RDD checkpoint到HDFS。
这个UnionRDD cache到了内存,但是如果发生checkpoint,会把这个UnionRDD写到磁盘,这样也会引起大量的磁盘I/O,为了解决这个问题,这个解决方案不能设置checkpoint。如果需要checkpoint,需要将KafkaDirectDStream每个Kafka分区的偏移量同步到zookeeper,每次程序重启的时候从zookeeper获取KafkaDirectDStream上一次读取到的位置。

相关文章推荐
- 是否要用Hadoop
- HDFS块检查命令Fsck机理的分析
- hdfs文件的操作常用命令
- HDFS集群系统的状况查看命令的返回情况
- hadoop上传文件功能实例代码
- hdfs 常用命令
- 第三章 第二节 HDFS概念
- hadoop集群环境的搭建
- 对HDFS的底层实现原理认识
- 向HDFS中追加内容
- eclipse+hadoop 配置过程中遇到的问题
- Hive over HBase和Hive over HDFS性能比较分析
- hadoop2安装脚本
- hadoop2安装脚本
- HDFS镜像文件的解析与反解析
- HDFS客户端的权限错误:Permission denied
- HDFS读文件过程分析:读取文件的Block数据
- 通过webhdfs put文件到hdfs
- 关于HDFS NFS3的配置
- spark streaming 写入db,hdfs