使用eclipse+python编写爬虫获取python百科的1000条词条
2016-03-29 21:33
756 查看
爬虫的机构
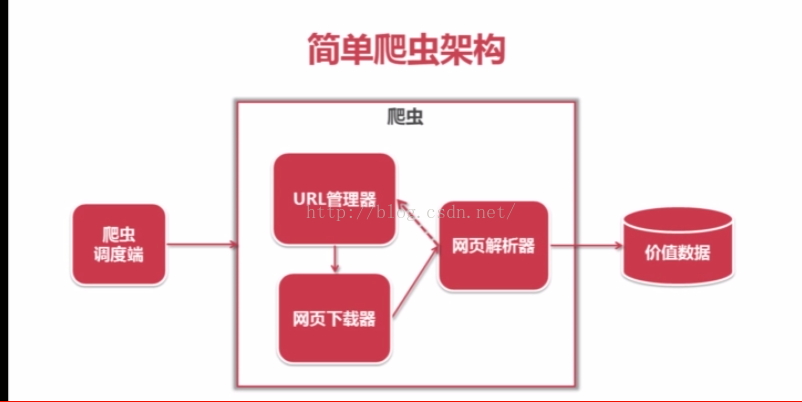
1. 爬虫的调度端
作用是实现爬虫的启动,停止和监视爬虫的运行情况
包括URL管理器:包含待爬取的URL和已经爬取的URL
把待爬取的URL送到网页下载器,下载器会将URL指定的网页下载下来存储成一个字符串,这个字符串会传送给玩野解释器解析,一方面解释出有价值的数据,和一些指向其他网页的URL,这些URL会补充到URL管理器,这三个模块形成一个循环,有相关的URL就会一直运行下去。
2.
实例爬虫的步骤
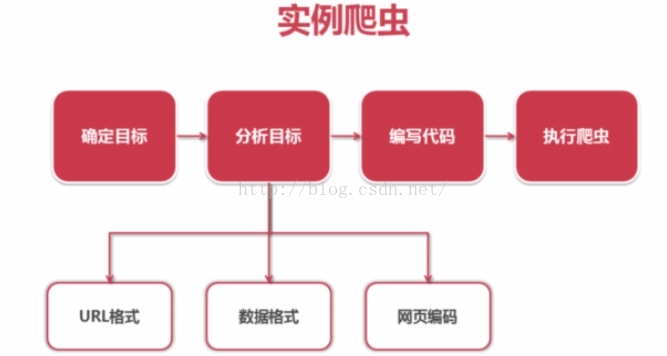
1. 确定目标:百度百科Python词条相关词条网页-标题和简介
2. 分析目标
1) URL格式
入口页:
http://baike.baidu.com/view/125370.htm
词条页面URL格式:/view/125370.htm"
2)页面编码 UTF-8
3)数据格式
标题格式<ddclass="lemmaWgt-lemmaTitle-title"></dd>
简介格式“<divclass="lemma-summary" label-module="lemmaSummary">
3. 编写爬虫
#coding:utf8
# from:http://www.imooc.com/learn/563
# By:muqingcai
from bs4import BeautifulSoup
import re
importurlparse
importurllib2
import os
#URL管理器
classUrlManager(object):
def __init__(self):
self.new_urls = set()
self.old_urls = set()
def add_new_url(self,url):
if url is None:
raise Exception # 为None抛出异常
if url not in self.new_urls and url notin self.old_urls:
self.new_urls.add(url)
def add_new_urls(self,urls):
if urls is None or len(urls) == 0:
raise Exception # 为None抛出异常
for url in urls:
self.add_new_url(url)
def has_new_url(self):
return len(self.new_urls) != 0
def get_new_url(self):
new_url = self.new_urls.pop()
self.old_urls.add(new_url)
return new_url
#HTML下载器
classHtmlDownloader(object):
def download(self, url):
if url is None:
return None
response = urllib2.urlopen(url)
if response.getcode() != 200:
return None
return response.read()
# HTML解析器
classHtmlParser(object):
def _get_new_urls(self,page_url,soup):
new_urls = [] ###########
# /view/123.htm: 得到所有词条URL
links = soup.find_all("a",href=re.compile(r"/view/\d+\.htm"))
for link in links:
new_url = link["href"]
#把new_url按照page_url的格式拼接成完整的URL格式
new_full_url =urlparse.urljoin(page_url,new_url)
new_urls.append(new_full_url)
return new_urls
def _get_new_data(self,page_url,soup):
res_data = {}
#url
res_data["url"] = page_url
#<ddclass="lemmaWgt-lemmaTitle-title"><h1>Python</h1>
title_node =soup.find("dd",class_="lemmaWgt-lemmaTitle-title").find("h1")
res_data["title"] =title_node.get_text()
#<divclass="lemma-summary" label-module="lemmaSummary">
summery_node =soup.find("div",class_="lemma-summary")
res_data["summary"] =summery_node.get_text()
return res_data
def parse(self,page_url,html_cont):
if page_url is None or html_cont isNone:
return
soup = BeautifulSoup(html_cont,"html.parser", from_encoding="utf-8")
new_urls = self._get_new_urls(page_url,soup)
new_data = self._get_new_data(page_url,soup)
return new_urls, new_data
# HTML输出器
classHtmlOutputer(object):
def __init__(self):
self.datas = []
def collect_data(self, data):
if data is None:
return
self.datas.append(data)
def output_html(self):
fout =open("baike_spider_output.html", "w")
fout.write("<html>")
fout.write("<head>")
fout.write('<metacharset="utf-8"></meta>')
fout.write("<title>百度百科Python页面爬取相关数据</title>")
fout.write("</head>")
fout.write("<body>")
fout.write('<h1style="text-align:center">在百度百科中爬取相关数据展示</h1>')
fout.write("<table>")
for data in self.datas:
fout.write("<tr>")
fout.write("<td>%s</td>" % data["url"])
fout.write("<td><ahref='%s'>%s</a></td>" %(data["url"].encode("utf-8"),data["title"].encode("utf-8")))
fout.write("<td>%s</td>" %data["summary"].encode("utf-8"))
fout.write("</tr>")
fout.write("</table>")
fout.write("</body>")
fout.write("</html>")
classSpiderMain():
def craw(self, root_url, page_counts):
count = 1 #记录爬取的是第几个URL
UrlManager.add_new_url(root_url)
while UrlManager.has_new_url(): # 如果有待爬取的URL
try:
# 把新URL取出来
new_url =UrlManager.get_new_url()
# 记录爬取的URL数量
print "\ncrawed %d :%s" % (count, new_url)
# 下载该URL的页面
html_cont =HtmlDownloader.download(new_url)
# 进行页面解析,得到新的URL和数据
new_urls, new_data =HtmlParser.parse(new_url, html_cont)
# 新URL补充进URL管理器
UrlManager.add_new_urls(new_urls)
# 进行数据的收集
HtmlOutputer.collect_data(new_data)
# 爬取到第counts个链接停止
if count == page_counts:
break
count = count + 1
except:
print "craw failed"
#输出收集好的数据
HtmlOutputer.output_html()
if__name__=="__main__":
print "\nWelcome to use baike_spider:)"
UrlManager = UrlManager()
HtmlDownloader = HtmlDownloader()
HtmlParser = HtmlParser()
HtmlOutputer = HtmlOutputer()
root = raw_input("Enter you want tocraw which baike url: http://baike.baidu.com/view/")
root_url ="http://baike.baidu.com/view/%s" % (root) #爬虫入口URL
page_counts = input("Enter you want tocraw how many pages:" ) #想要爬取的数量
SpiderMain = SpiderMain()
SpiderMain.craw(root_url,page_counts) #启动爬虫
print"\nCraw is done, please go to"+os.path.dirname(os.path.abspath('__file__')) + " to see the resultin baike_spider_output.html"
4. 执行爬虫
直接python run即可,执行结果
如下:

..................................

……………………..
在package包下按F5即可刷新得到

点开可以看到


相关文章推荐
- Python动态类型的学习---引用的理解
- Python3写爬虫(四)多线程实现数据爬取
- 垃圾邮件过滤器 python简单实现
- 下载并遍历 names.txt 文件,输出长度最长的回文人名。
- install and upgrade scrapy
- Scrapy的架构介绍
- Centos6 编译安装Python
- 使用Python生成Excel格式的图片
- 让Python文件也可以当bat文件运行
- [Python]推算数独
- 爬虫笔记
- Python中zip()函数用法举例
- Python中map()函数浅析
- Python将excel导入到mysql中
- Python在CAM软件Genesis2000中的应用
- 使用Shiboken为C++和Qt库创建Python绑定
- Python的可视化工具概述