文本语言模型的参数估计-最大似然估计、MAP及贝叶斯估计
2016-03-29 19:21
232 查看
以PLSA和LDA为代表的文本语言模型是当今统计自然语言处理研究的热点问题。这类语言模型一般都是对文本的生成过程提出自己的概率图模型,然后利用观察到的语料数据对模型参数做估计。有了语言模型和相应的模型参数,我们可以有很多重要的应用,比如文本特征降维、文本主题分析等等。本文主要介绍文本分析的三类参数估计方法-最大似然估计MLE、最大后验概率估计MAP及贝叶斯估计。
1、最大似然估计MLE
首先回顾一下贝叶斯公式
%20=%20%5Cfrac%7Bp(X%7C%5Ctheta)%20%5Ccdot%20p(%5Ctheta)%7D%7Bp(X)%7D)
这个公式也称为逆概率公式,可以将后验概率转化为基于似然函数和先验概率的计算表达式,即
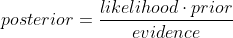
最大似然估计就是要用似然函数取到最大值时的参数值作为估计值,似然函数可以写做
%20=%20p(X%20%7C%20%5Ctheta)%20=%20%5Cprod_%7Bx%20%5Cin%20X%7D%7Bp(X%20=%20x%20%7C%20%5Ctheta)%7D)
由于有连乘运算,通常对似然函数取对数计算简便,即对数似然函数。最大似然估计问题可以写成
%20=%20argmax_%5Ctheta%20%5Csum_%7Bx%20%5Cin%20X%7D%5Clog%20p(x%7C%5Ctheta))
这是一个关于
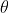
的函数,求解这个优化问题通常对
求导,得到导数为0的极值点。该函数取得最大值是对应的
的取值就是我们估计的模型参数。
以扔硬币的伯努利实验为例子,N次实验的结果服从二项分布,参数为P,即每次实验事件发生的概率,不妨设为是得到正面的概率。为了估计P,采用最大似然估计,似然函数可以写作
=%5Csum_%7Bi=1%7D%5EN%5Clog%20p(C=c_i%7Cp)%20%5C%5C%20&=%20n%5E%7B(1)%7D%5Clog%20p(C%20=%201%7Cp)%20+%20n%5E%7B(0)%7D%5Clog%20p(C%20=%200%7Cp)%5C%5C%20&=%20n%5E%7B(1)%7D%5Clog%20p%20+%20n%5E%7B(0)%7D%5Clog%20(1-p)%20%5Cend%7Baligned%7D)
其中

表示实验结果为i的次数。下面求似然函数的极值点,有
%7D%7D%7Bp%7D%20-%20%5Cfrac%7Bn%5E%7B(0)%7D%7D%7B1-p%7D%20=%200)
得到参数p的最大似然估计值为
%7D%7D%7Bn%5E%7B(1)%7D%20+%20n%5E%7B(0)%7D%7D%20=%20%5Cfrac%7Bn%5E%7B(1)%7D%7D%7BN%7D)
可以看出二项分布中每次事件发的概率p就等于做N次独立重复随机试验中事件发生的概率。
如果我们做20次实验,出现正面12次,反面8次
那么根据最大似然估计得到参数值p为12/20 = 0.6。
2、最大后验估计MAP
最大后验估计与最大似然估计相似,不同点在于估计
的函数中允许加入一个先验
)
,也就是说此时不是要求似然函数最大,而是要求由贝叶斯公式计算出的整个后验概率最大,即
%20p(%5Ctheta)%7D%7Bp(X)%7D%5C%5C%20&=%20argmax_%5Ctheta%20p(X%20%7C%20%5Ctheta)p(%5Ctheta)%20%5C%5C%20&=%20argmax_%5Ctheta%20%5C%7BL(%5Ctheta%7CX)%20+%20%5Clog%20p(%5Ctheta)%5C%7D%5C%5C%20&=%20argmax_%5Ctheta%20%5C%7B%5Csum_%7Bx%20%5Cin%20X%7D%20%5Clog%20p(x%20%7C%20%5Ctheta)%20+%20%5Clog%20p(%5Ctheta)%5C%7D%20%5Cend%7Baligned%7D)
注意这里P(X)与参数
无关,因此等价于要使分子最大。与最大似然估计相比,现在需要多加上一个先验分布概率的对数。在实际应用中,这个先验可以用来描述人们已经知道或者接受的普遍规律。例如在扔硬币的试验中,每次抛出正面发生的概率应该服从一个概率分布,这个概率在0.5处取得最大值,这个分布就是先验分布。先验分布的参数我们称为超参数(hyperparameter)即
=%20p(%5Ctheta%7C%5Calpha))
同样的道理,当上述后验概率取得最大值时,我们就得到根据MAP估计出的参数值。给定观测到的样本数据,一个新的值
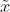
发生的概率是
%20=%20%5Cint_%7B%5Ctheta%20%5Cin%20%5CTheta%7Dp(%5Ctilde%7Bx%7D%7C%5Chat%7B%5Ctheta%7D_%7BMAP%7D)%20p(%5Ctheta%20%7C%20X)%20d%5Ctheta%20=%20p(%5Ctilde%7Bx%7D%7C%5Chat%7B%5Ctheta%7D_%7BMAP%7D))
下面我们仍然以扔硬币的例子来说明,我们期望先验概率分布在0.5处取得最大值,我们可以选用Beta分布即
%20=%20%5Cfrac%7B1%7D%7BB(%5Calpha,%20%5Cbeta)%7Dp%5E%7B%5Calpha%20-%201%7D(1-p)%5E%7B%5Cbeta%20-%201%7D%20%5Cstackrel%7B%5Ctriangle%7D%7B=%7DBeta(p%7C%5Calpha,%20%5Cbeta))
其中Beta函数展开是
%20=%20%5Cfrac%7B%5CGamma(%5Calpha)%5CGamma(%5Cbeta)%7D%7B%5CGamma(%5Calpha%20+%20%5Cbeta)%7D)
当x为正整数时
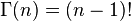
Beta分布的随机变量范围是[0,1],所以可以生成normalised probability values。下图给出了不同参数情况下的Beta分布的概率密度函数

我们取
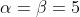
,这样先验分布在0.5处取得最大值,现在我们来求解MAP估计函数的极值点,同样对p求导数我们有
%7D%7D%7Bp%7D-%5Cfrac%7Bn%5E%7B(0)%7D%7D%7B1-p%7D+%5Cfrac%7B%5Calpha%20-%201%7D%7Bp%7D-%5Cfrac%7B%5Cbeta%20-%201%7D%7B1%20-%20p%7D%20=%200)
得到参数p的的最大后验估计值为
%7D%20+%20%5Calpha%20-%201%7D%7Bn%5E%7B(1)%7D%20+%20n%5E%7B(0)%7D%20+%20%5Calpha%20+%20%5Cbeta%20-%202%7D%20=%20%5Cfrac%7Bn%5E%7B(1)%7D%20+%204%7D%7Bn%5E%7B(1)%7D%20+%20n%5E%7B(0)%7D%20+%208%7D)
和最大似然估计的结果对比可以发现结果中多了
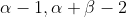
这样的pseudo-counts,这就是先验在起作用。并且超参数越大,为了改变先验分布传递的belief所需要的观察值就越多,此时对应的Beta函数越聚集,紧缩在其最大值两侧。
如果我们做20次实验,出现正面12次,反面8次,那么
那么根据MAP估计出来的参数p为16/28 = 0.571,小于最大似然估计得到的值0.6,这也显示了“硬币一般是两面均匀的”这一先验对参数估计的影响。
3 贝叶斯估计
贝叶斯估计是在MAP上做进一步拓展,此时不直接估计参数的值,而是允许参数服从一定概率分布。回顾一下贝叶斯公式
现在不是要求后验概率最大,这样就需要求
)
,即观察到的evidence的概率,由全概率公式展开可得
%20=%20%5Cint_%7B%5Ctheta%20%5Cin%20%5CTheta%7Dp(X%7C%5Ctheta)p(%5Ctheta)d%5Ctheta)
当新的数据被观察到时,后验概率可以自动随之调整。但是通常这个全概率的求法是贝叶斯估计比较有技巧性的地方。
那么如何用贝叶斯估计来做预测呢?如果我们想求一个新值
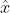
的概率,可以由
%20=%20%5Cint_%7B%5Ctheta%20%5Cin%20%5CTheta%7D%20p(%5Chat%7Bx%7D%20%7C%20%5Ctheta)p(%5Ctheta%7CX)d%5Ctheta=%5Cint_%7B%5Ctheta%20%5Cin%20%5CTheta%7Dp(%5Chat%7Bx%7D%7C%5Ctheta)%5Cfrac%7Bp(X%7C%5Ctheta)p(%5Ctheta)%7D%7Bp(X)%7Dd%5Ctheta)
来计算。注意此时第二项因子在

上的积分不再等于1,这就是和MLE及MAP很大的不同点。
我们仍然以扔硬币的伯努利实验为例来说明。和MAP中一样,我们假设先验分布为Beta分布,但是构造贝叶斯估计时,不是要求用后验最大时的参数来近似作为参数值,而是求满足Beta分布的参数p的期望,有

注意这里用到了公式
)
当T为二维的情形可以对Beta分布来应用;T为多维的情形可以对狄利克雷分布应用
根据结果可以知道,根据贝叶斯估计,参数p服从一个新的Beta分布。回忆一下,我们为p选取的先验分布是Beta分布,然后以p为参数的二项分布用贝叶斯估计得到的后验概率仍然服从Beta分布,由此我们说二项分布和Beta分布是共轭分布。在概率语言模型中,通常选取共轭分布作为先验,可以带来计算上的方便性。最典型的就是LDA中每个文档中词的Topic分布服从Multinomial分布,其先验选取共轭分布即Dirichlet分布;每个Topic下词的分布服从Multinomial分布,其先验也同样选取共轭分布即Dirichlet分布。
根据Beta分布的期望和方差计算公式,我们有

可以看出此时估计的p的期望和MLE ,MAP中得到的估计值都不同,此时如果仍然是做20次实验,12次正面,8次反面,那么我们根据贝叶斯估计得到的p满足参数为12+5和8+5的Beta分布,其均值和方差分别是17/30=0.567, 17*13/(31*30^2)=0.0079。可以看到此时求出的p的期望比MLE和MAP得到的估计值都小,更加接近0.5。
综上所述我们可以可视化MLE,MAP和贝叶斯估计对参数的估计结果如下

个人理解是,从MLE到MAP再到贝叶斯估计,对参数的表示越来越精确,得到的参数估计结果也越来越接近0.5这个先验概率,越来越能够反映基于样本的真实参数情况。
参考文献
Gregor Heinrich, Parameter estimation for test analysis, technical report
Wikipedia Beta分布词条 , http://en.wikipedia.org/wiki/Beta_distribution
1、最大似然估计MLE
首先回顾一下贝叶斯公式
这个公式也称为逆概率公式,可以将后验概率转化为基于似然函数和先验概率的计算表达式,即
最大似然估计就是要用似然函数取到最大值时的参数值作为估计值,似然函数可以写做
由于有连乘运算,通常对似然函数取对数计算简便,即对数似然函数。最大似然估计问题可以写成
这是一个关于
的函数,求解这个优化问题通常对
求导,得到导数为0的极值点。该函数取得最大值是对应的
的取值就是我们估计的模型参数。
以扔硬币的伯努利实验为例子,N次实验的结果服从二项分布,参数为P,即每次实验事件发生的概率,不妨设为是得到正面的概率。为了估计P,采用最大似然估计,似然函数可以写作
其中
表示实验结果为i的次数。下面求似然函数的极值点,有
得到参数p的最大似然估计值为
可以看出二项分布中每次事件发的概率p就等于做N次独立重复随机试验中事件发生的概率。
如果我们做20次实验,出现正面12次,反面8次
那么根据最大似然估计得到参数值p为12/20 = 0.6。
2、最大后验估计MAP
最大后验估计与最大似然估计相似,不同点在于估计
的函数中允许加入一个先验
,也就是说此时不是要求似然函数最大,而是要求由贝叶斯公式计算出的整个后验概率最大,即
注意这里P(X)与参数
无关,因此等价于要使分子最大。与最大似然估计相比,现在需要多加上一个先验分布概率的对数。在实际应用中,这个先验可以用来描述人们已经知道或者接受的普遍规律。例如在扔硬币的试验中,每次抛出正面发生的概率应该服从一个概率分布,这个概率在0.5处取得最大值,这个分布就是先验分布。先验分布的参数我们称为超参数(hyperparameter)即
同样的道理,当上述后验概率取得最大值时,我们就得到根据MAP估计出的参数值。给定观测到的样本数据,一个新的值
发生的概率是
下面我们仍然以扔硬币的例子来说明,我们期望先验概率分布在0.5处取得最大值,我们可以选用Beta分布即
其中Beta函数展开是
当x为正整数时
Beta分布的随机变量范围是[0,1],所以可以生成normalised probability values。下图给出了不同参数情况下的Beta分布的概率密度函数
我们取
,这样先验分布在0.5处取得最大值,现在我们来求解MAP估计函数的极值点,同样对p求导数我们有
得到参数p的的最大后验估计值为
和最大似然估计的结果对比可以发现结果中多了
这样的pseudo-counts,这就是先验在起作用。并且超参数越大,为了改变先验分布传递的belief所需要的观察值就越多,此时对应的Beta函数越聚集,紧缩在其最大值两侧。
如果我们做20次实验,出现正面12次,反面8次,那么
那么根据MAP估计出来的参数p为16/28 = 0.571,小于最大似然估计得到的值0.6,这也显示了“硬币一般是两面均匀的”这一先验对参数估计的影响。
3 贝叶斯估计
贝叶斯估计是在MAP上做进一步拓展,此时不直接估计参数的值,而是允许参数服从一定概率分布。回顾一下贝叶斯公式
现在不是要求后验概率最大,这样就需要求
,即观察到的evidence的概率,由全概率公式展开可得
当新的数据被观察到时,后验概率可以自动随之调整。但是通常这个全概率的求法是贝叶斯估计比较有技巧性的地方。
那么如何用贝叶斯估计来做预测呢?如果我们想求一个新值
的概率,可以由
来计算。注意此时第二项因子在
上的积分不再等于1,这就是和MLE及MAP很大的不同点。
我们仍然以扔硬币的伯努利实验为例来说明。和MAP中一样,我们假设先验分布为Beta分布,但是构造贝叶斯估计时,不是要求用后验最大时的参数来近似作为参数值,而是求满足Beta分布的参数p的期望,有
注意这里用到了公式
当T为二维的情形可以对Beta分布来应用;T为多维的情形可以对狄利克雷分布应用
根据结果可以知道,根据贝叶斯估计,参数p服从一个新的Beta分布。回忆一下,我们为p选取的先验分布是Beta分布,然后以p为参数的二项分布用贝叶斯估计得到的后验概率仍然服从Beta分布,由此我们说二项分布和Beta分布是共轭分布。在概率语言模型中,通常选取共轭分布作为先验,可以带来计算上的方便性。最典型的就是LDA中每个文档中词的Topic分布服从Multinomial分布,其先验选取共轭分布即Dirichlet分布;每个Topic下词的分布服从Multinomial分布,其先验也同样选取共轭分布即Dirichlet分布。
根据Beta分布的期望和方差计算公式,我们有
可以看出此时估计的p的期望和MLE ,MAP中得到的估计值都不同,此时如果仍然是做20次实验,12次正面,8次反面,那么我们根据贝叶斯估计得到的p满足参数为12+5和8+5的Beta分布,其均值和方差分别是17/30=0.567, 17*13/(31*30^2)=0.0079。可以看到此时求出的p的期望比MLE和MAP得到的估计值都小,更加接近0.5。
综上所述我们可以可视化MLE,MAP和贝叶斯估计对参数的估计结果如下
个人理解是,从MLE到MAP再到贝叶斯估计,对参数的表示越来越精确,得到的参数估计结果也越来越接近0.5这个先验概率,越来越能够反映基于样本的真实参数情况。
参考文献
Gregor Heinrich, Parameter estimation for test analysis, technical report
Wikipedia Beta分布词条 , http://en.wikipedia.org/wiki/Beta_distribution

相关文章推荐
- 线程和进程的区别
- lightoj 1084 - Winter DP
- mysql配置的讲解 mysql的root密码重置 mysql的登录
- [经典] 深搜寻路问题
- 二分查找(折半查找)
- POJ 1039 Pipe (直线与线段间的关系)
- 结队项目阶段报告
- 第五周作业 长方形
- [HNOI2016]树
- bzoj 3050: [Usaco2013 Jan]Seating
- edge.js
- ViewPager禁止滑动的问题
- 61D的代码如何利用Catcher抓取log
- 第五周上机实践项目 项目1--三角形类雏形(1)
- C++文件读写 实现文件每行数据齐长输出
- 在Ubuntu 10.04中文版下Qt编程,使用unixODBC和FreeTDS连接MS SQL Server 2005,并且中文不出现乱码的方法
- 第五周 时钟1
- 第五周 游戏角色类
- 高度和宽度不固定元素水平和垂直居中的实现(父元素高度和宽度固定)(完美解决兼容问题)
- Java 实现工厂设计模式的三种方式