Linux 性能测试工具
2016-03-29 16:02
507 查看
Linux 性能测试工具
linux performance查看系统配置
查看CPU信息
lscpu
Architecture: x86_64CPU op-mode(s): 32-bit, 64-bit
CPU(s): 8
Thread(s) per core: 2
Core(s) per socket: 4
CPU socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 58
Stepping: 9
CPU MHz: 1600.000
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 8192K
NUMA node0 CPU(s): 0-7
/proc/cpuinfo
cpuinfo可以查看详细信息[wangyl11@rhel149 ~]$ more /proc/cpuinfo
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 58
model name : Intel(R) Core(TM) i7-3770 CPU @ 3.40GHz
stepping : 9
cpu MHz : 1600.000
cache size : 8192 KB
…………
查看内存信息
/proc/meminfo
cat /proc/meminfo[wangyl11@rhel149 ~]$ cat /proc/meminfo
MemTotal: 32765960 kB # 系统总内存大小
MemFree: 5090232 kB # 剩余内存
Buffers: 578492 kB # 文件做缓冲大小
Cached: 4783976 kB # 被高速缓冲存储器(cache memory)用的内存的大小
SwapCached: 438840 kB
……………
free
hnwyllmm@ubuntu:~$ freetotal used free shared buffers cached
Mem: 2042656 157792 1884864 564 22880 48700
-/+ buffers/cache: 86212 1956444
Swap: 2094076 0 2094076
显示的结果以字节为单位:
total:总计物理内存的大小。
used:已使用多大。
free:可用有多少。
Shared:多个进程共享的内存总额。
Buffers/cached:磁盘缓存的大小。
第三行(-/+ buffers/cached):
used:已使用多大。
free:可用有多少。
区别:第二行(mem)的used/free与第三行(-/+ buffers/cache) used/free的区别。 这两个的区别在于使用的角度来看,第一行是从OS的角度来看,因为对于OS,buffers/cached 都是属于被使用,所以他的可用内存是16176KB,已用内存是3250004KB,其中包括,内核(OS)使用+Application(X, oracle,etc)使用的+buffers+cached.
第三行所指的是从应用程序角度来看,对于应用程序来说,buffers/cached 是等于可用的,因为buffer/cached是为了提高文件读取的性能,当应用程序需在用到内存的时候,buffer/cached会很快地被回收。
-m选项:以MB为单位显示
[wangyl11@rhel149 ~]$ free -m
total used free shared buffers cached
Mem: 31998 27011 4986 0 566 4676
-/+ buffers/cache: 21768 10229
Swap: 32765 6983 25781
网卡
lspci | grep -i eth
查看网卡硬件信息hnwyllmm@ubuntu:~$ lspci | grep -i eth
02:01.0 Ethernet controller: Intel Corporation 82545EM Gigabit Ethernet Controller (Copper) (rev 01)
ethtool eth0
查看网卡eth0的信息[root@rhel149 wangyl11]# ethtool eth0
Settings for eth0:
Supported ports: [ TP ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Supports auto-negotiation: Yes
Advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Advertised pause frame use: No
Advertised auto-negotiation: Yes
Speed: 1000Mb/s # 网卡的速度
Duplex: Full
Port: Twisted Pair
………….
磁盘
df -h
[wangyl11@rhel149 ~]$ df -hFilesystem Size Used Avail Use% Mounted on
/dev/sda6 20G 14G 5.6G 71% /
tmpfs 16G 0 16G 0% /dev/shm
/dev/sda1 494M 40M 429M 9% /boot
/dev/sda2 394G 326G 48G 88% /data01
/dev/sda9 403G 23G 360G 6% /data02
/dev/sda3 50G 38G 9.2G 81% /sw
/dev/sda8 9.9G 153M 9.2G 2% /tmp
/dev/sda7 9.9G 7.3G 2.1G 78% /var
性能测试的时候,经常出现日志或者话单文件把磁盘占满的情况,可以通过这个命令来验证。
lsblk
查看硬盘和分布区域hnwyllmm@ubuntu:~$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 20G 0 disk
├─sda1 8:1 0 18G 0 part /
├─sda2 8:2 0 1K 0 part
└─sda5 8:5 0 2G 0 part [SWAP]
大杂烩
dmidecode
输出的信息包括 BIOS、系统、主板、处理器、内存、缓存等等运行时系统监控工具
CPU占用
top
按照CPU占用率查看系统进程信息top - 10:56:49 up 69 days, 10:54, 10 users, load average: 0.02, 0.11, 0.15
Tasks: 277 total, 1 running, 274 sleeping, 0 stopped, 2 zombie
Cpu(s): 0.3%us, 0.1%sy, 0.0%ni, 99.1%id, 0.5%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 32765960k total, 27617088k used, 5148872k free, 580304k buffers
Swap: 33551712k total, 7154044k used, 26397668k free, 4737448k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
10353 qijf 20 0 5547m 1.7g 4264 S 1.3 5.3 50:54.00 odframe
2679 huangjx 20 0 2611m 428m 2532 S 0.7 1.3 8:28.79 odframe
12428 niuhg 20 0 847m 85m 50m S 0.7 0.3 99:33.40 mongod
15766 caizj 20 0 10.6g 166m 3912 S 0.7 0.5 7:05.29 java
6862 root 20 0 0 0 0 S 0.3 0.0 20:28.46 flush-8:0
15455 caizj 20 0 10.6g 166m 3924 S 0.3 0.5 7:06.37 java
15531 caizj 20 0 10.6g 169m 4776 S 0.3 0.5 7:19.69 java
15575 caizj 20 0 11.5g 165m 4436 S 0.3 0.5 13:46.97 java
1 root 20 0 19244 772 572 S 0.0 0.0 0:02.84 init
…….
top还可以按照进程占用内存排序,指定监控进程号,设置刷新频率等功能。
如果在测试过程中发现程序突然卡顿,一般会猜想到系统状态异常,除了磁盘、内存等异常,还可能是CPU被“吃掉”,比如有个特别消耗CPU的程序被启动,可以通过
top命令抓到罪魁祸首。
查看指定进程的CPU占用情况
top -p 'pid'
top - 11:08:48 up 69 days, 11:06, 11 users, load average: 2.80, 1.71, 0.78
Tasks: 1 total, 0 running, 1 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.6%us, 0.2%sy, 0.0%ni, 86.0%id, 13.3%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 32765960k total, 27585340k used, 5180620k free, 585860k buffers
Swap: 33551712k total, 7149372k used, 26402340k free, 4705800k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
31183 caizj 20 0 319m 2704 2264 S 0.0 0.0 0:00.72 mdb_zkfc_test
mpstat
监控所有CPU状态。top命令只能看到总的CPU负荷,
mpstat除了可以查看总的CPU负载,还可以查看CPU每个core的负载状态。
[wangyl11@rhel149 ~]$ mpstat
Linux 2.6.32-71.el6.x86_64 (rhel149) 03/29/2016 x86_64 (8 CPU)
10:59:11 AM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle
10:59:11 AM all 0.85 0.00 0.14 0.57 0.00 0.00 0.00 0.00 98.44
查看单个core信息
mpstat -P ALL
[wangyl11@rhel149 ~]$ mpstat -P ALL
Linux 2.6.32-71.el6.x86_64 (rhel149) 03/29/2016 x86_64 (8 CPU)
11:04:29 AM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle
11:04:29 AM all 0.85 0.00 0.14 0.57 0.00 0.00 0.00 0.00 98.44
11:04:29 AM 0 0.80 0.00 0.15 0.03 0.00 0.00 0.00 0.00 99.02
11:04:29 AM 1 1.12 0.00 0.32 0.13 0.00 0.01 0.00 0.00 98.43
11:04:29 AM 2 0.98 0.00 0.14 4.19 0.00 0.00 0.00 0.00 94.69
11:04:29 AM 3 0.65 0.00 0.07 0.01 0.00 0.00 0.00 0.00 99.27
11:04:29 AM 4 0.87 0.00 0.16 0.01 0.00 0.00 0.00 0.00 98.95
11:04:29 AM 5 0.75 0.00 0.06 0.01 0.00 0.01 0.00 0.00 99.17
11:04:29 AM 6 0.92 0.00 0.11 0.14 0.00 0.01 0.00 0.00 98.82
11:04:29 AM 7 0.73 0.00 0.06 0.01 0.00 0.00 0.00 0.00 99.20
一般的系统都会将网卡中断绑定到某个或某几个特定的CPU。如果网络在繁忙的时候,CPU总体状态很空闲,但是绑定网卡中断的CPU可能会应付不过来,也会导致整体流程运行异常。这时就可以通过
mpstat跟踪单个CPU来查看是否有这种异常。
内存
top -p `pid’
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND31183 caizj 20 0 319m 2704 2264 S 0.0 0.0 0:00.77 mdb_zkfc_test
%MEM 进程使用的物理内存百分比
VIRT 虚拟内存总量,单位kb。VIRT=SWAP+RES
SWAP 虚拟内存中,被换出的大小,单位kb。
RES 使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
CODE 可执行代码占用的物理内存大小,单位kb。
DATA 可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位kb
SHR 共享内存大小,单位kb
nFLT 页面错误次数
NOTE: 上面一些参数默认不输出,需要特定参数才会输出,具体参考man手册。
free -s `seconds’
定时输出内存信息,-s指定输出频率。ps -o pid,user,%cpu,%mem -p `pid’
查看指定进程的CPU和内存状态/proc/`pid’/maps
查看进程内存空间映射情况IO
/proc/`pid’/io
rchar: 6388651 # 进程读取的字节数,包括从缓存中读取的wchar: 70988260 # 进程写入的字节数,包括写入缓存中的
syscr: 818 # 读系统调用执行的次数
syscw: 9966 # 写系统调用执行的次数
read_bytes: 37916672 # 从物理磁盘中读取的字节数
write_bytes: 74756096 # 写入物理磁盘的字节数
cancelled_write_bytes: 4096
iostat
iostat可以显示CPU和I/O系统的负载情况及分区状态信息.
[rhel149 10353]# iostat
Linux 2.6.32-71.el6.x86_64 (rhel149) 03/29/2016 x86_64 (8 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.85 0.00 0.14 0.57 0.00 98.44
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 7.35 96.75 279.63 580916240 1678898304
各个输出项目的含义如下:
avg-cpu段:
%user: 在用户级别运行所使用的CPU的百分比.
%nice: nice操作所使用的CPU的百分比.
%sys: 在系统级别(kernel)运行所使用CPU的百分比.
%iowait: CPU等待硬件I/O时,所占用CPU百分比.
%idle: CPU空闲时间的百分比.
Device段:
tps: 每秒钟发送到的I/O请求数.
Blk_read /s: 每秒读取的block数.
Blk_wrtn/s: 每秒写入的block数.
Blk_read: 读入的block总数.
Blk_wrtn: 写入的block总数.
iostat 'seconds' ['count']
指定每个多长时间[
seconds]输出一次,一共输出
count次,
count可以省略。
如果系统的
iowait值偏高,说明程序在IO上可以做优化,除非是一个IO密集型的程序。
综合
vmstat
vmstat是一个综合型的系统监控工具,可以同时看到系统的CPU、IO、内存和系统进程执行状态。
vmstat 'seconds' ['count']
每隔
seconds秒输出一次,一共输出
count次,
count可以省略。
vmstat的输出样例:
[root@rhel149 10353]# vmstat
procs ———–memory———- —swap– —–io—- –system– —–cpu—–
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 7129728 4879500 615704 4636960 0 0 6 17 1 0 1 0 98 1 0
通过
vmstat可以关注系统的内存缓存状态,系统的系统调用时间占比(
sys列),空闲CPU时间(
id列)和CPU上下文切换次数(
cs列)。
vmstat的输出参数可以参考vmstat参数参考。
进程分析工具
pstack `pid’
pstack用来查看进程某时刻执行栈信息。常用来验证是否出现死锁,或者猜测程序可能在执行某个函数时耗时过长。strace
strace是跟踪系统调用的工具,可以检测系统调用的参数、返回值和执行时间。可以查看程序运行卡在哪里,比如recv/send占用时间长,说明网络调用有问题。命令示例:
strace -o output.txt -f -T -tt -e trace=all -p 28979
strace会跟踪
28979进程,将结果输出到
output.txt中。
valgrind
内存泄露和越界检查的葵花宝典。经典命令:
valgrind --leak-check=full --track-origins=yes --show-reachable=yes --log-file='memcheck.log' 'run command'
使用
valgrind检测内存问题,最好让进程能够正常退出。上面那条命令会跟踪
'run command'程序,并将结果输出到
'memcheck.log'中。
valgrind的输出和检查方法请参考valgrind的使用概述。
vtune
vtune是热点采集工具,支持Intel CPU,并提供了界面工具,查看热点十分方便。
vtune的准备:
1. 安装xmanager。
2. 设置SSH client支持X11转发。
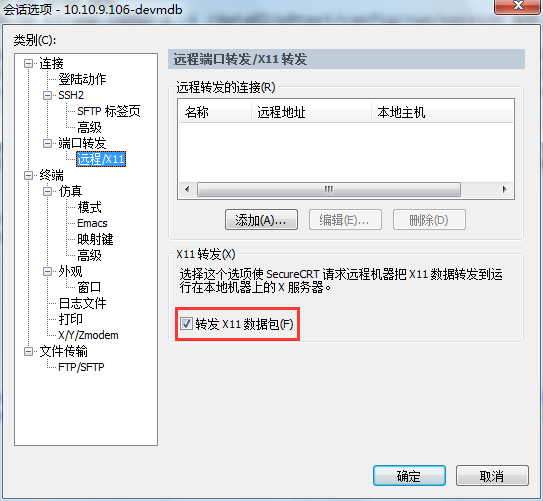
测试步骤:
1. 执行程序;
2. 采集数据:
amplxe-cl -collect hotspots -target-pid pid。这一步vtune会生成一个性能数据目录,这里面的数据供vtune后续分析;
3. 打开xmanager;
4. 执行amplxe-gui。vtune会打开一个窗口,如图。

图1. amplxe-gui打开的界面
打开采集数据并查看结果。
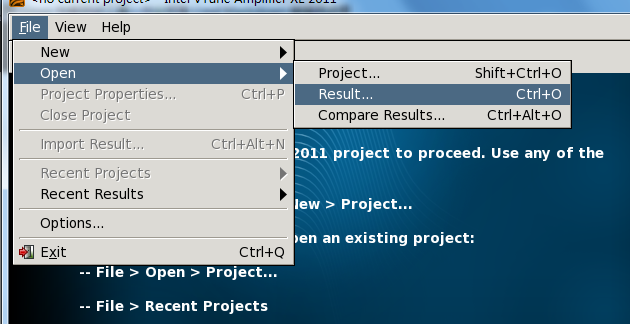
图2. 打开vtune采集数据
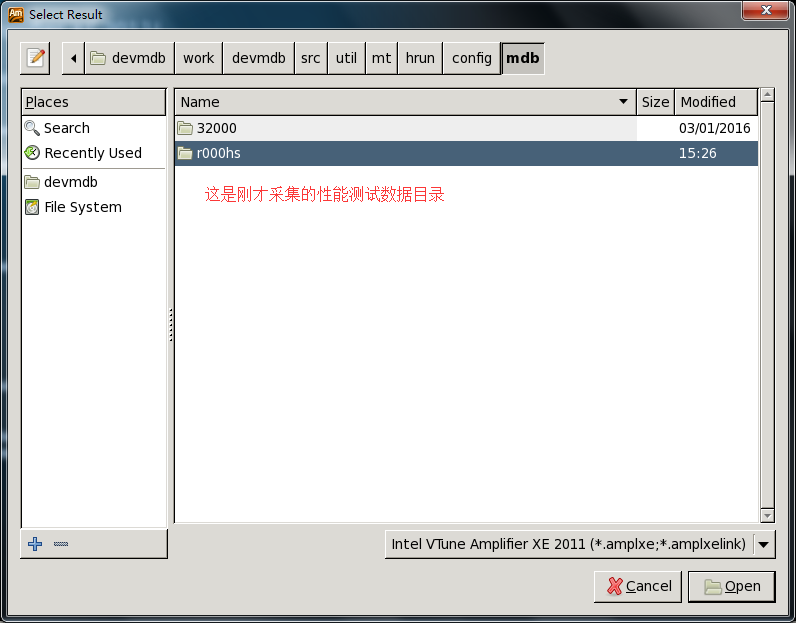
图3. 找到数据所在目录(gui会默认打开SSH client上执行amplxe-gui的目录)
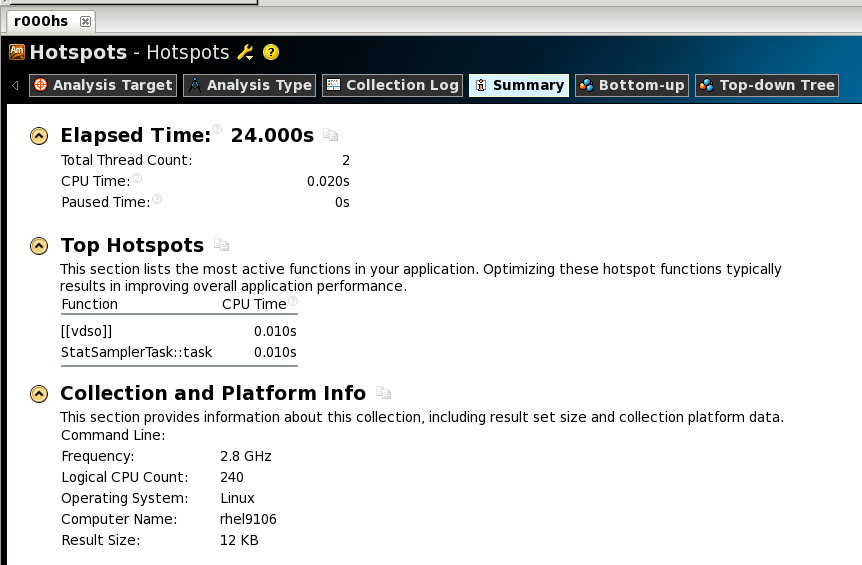
图4. vtune的分析汇总展示
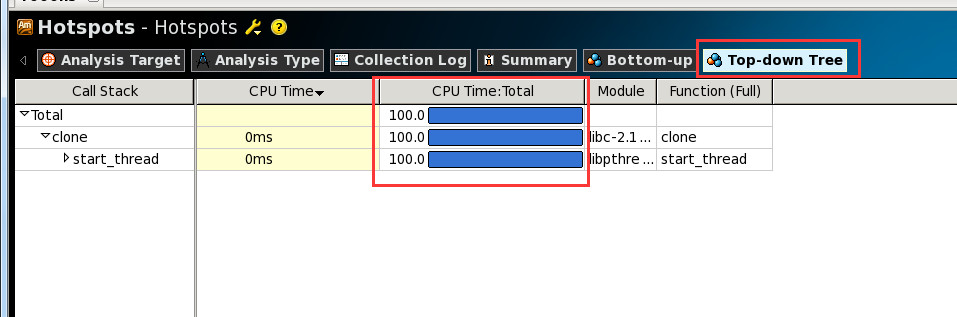
图5. vtune分析热点
参考
在Linux查看内存的大小Linux 查看系统硬件信息
Linux /proc/meminfo文件分析
Linux top命令解析
valgrind的使用概述

相关文章推荐
- Linux socket 初步
- Linux Kernel 4.0 RC5 发布!
- linux lsof详解
- linux 文件权限
- Linux 执行数学运算
- 10 篇对初学者和专家都有用的 Linux 命令教程
- Linux 与 Windows 对UNICODE 的处理方式
- Ubuntu12.04下QQ完美走起啊!走起啊!有木有啊!
- 解決Linux下Android开发真机调试设备不被识别问题
- 运维入门
- 运维提升
- Linux 自检和 SystemTap
- Ubuntu Linux使用体验
- c语言实现hashmap(转载)
- Linux 信号signal处理机制
- linux下mysql添加用户
- Scientific Linux 5.5 图形安装教程
- Linux 下无损图片压缩小工具介绍