机器学习十大算法之C4.5
2016-03-28 20:43
197 查看
C4.5由J.Ross Quinlan在ID3的基础上提出。从ID3算法中衍生出了C4.5和CART两种算法,这两种算法在数据挖掘中都非常重要。
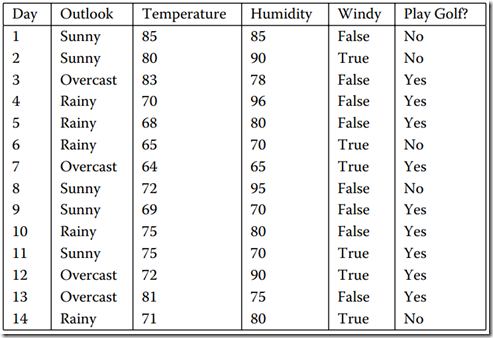
数据集如图所示,它表示的是天气情况与去不去打高尔夫球之间的关系。
C4.5并不是一个算法,而是一组算法——C4.5,非剪枝C4.5和C4.5规则。下图中的算法给出C4.5的基本工作流程:

我们可能有疑问,一个元组本身有很多属性,我们怎么知道首先要对哪个属性进行判断,接下来要对哪个属性进行判断?
一般而言,随着划分过程不断进行,我们希望决策树的分支节点所包含的样本尽可能属于同一类别,即节点的“纯度”越来越高。
划分选择
“信息熵”是度量样本集合纯度最常用的一种指标,样本集合D的信息熵定义为:
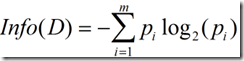
信息熵的值越小,则D的纯度越高。
现在假定按照属性a划分D中的元组,且属性a将D划分成v个不同的类。在该划分之后,为了得到准确的分类还需要的信息由下面的式子度量:
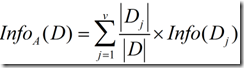
于是可计算出用属性a对样本集D进行划分所获得的“信息增益”
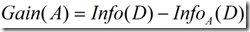
一般而言,信息增益越大,则意味着使用属性a来进行划分所获得的“纯度提升”越大。因此,我们可用信息增益来进行决策树的划分属性选择。
著名的ID3决策树算法就是以信息增益为准则来选择划分属性的。
但是,以信息增益为准则的话其实是有一个缺点,那就是它偏向于具有大量值的属性。什么意思呢?就是说在训练集中,某个属性所取的不同
值的个数越多,那么越有可能拿它来作为分裂属性。例如一个训练集中有10个元组,对于某一个属性a,它分别取1~10这十个数,如果对a进
行分裂将会分成10个类,那么对于每一个类Info(Dj)=0,从而式(2)为0,该属性划分所得到的信息增益(3)最大,但是这样的决策树显然
不具有泛化能力,无法对新样本进行有效预测。
正是基于此,ID3后面的C4.5采用了信息增益率这样一个概念。信息增益率使用“分裂信息”值将信息增益规范化。分类信息类似于Info(D),
定义如下:
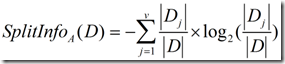
这个值表示通过将训练数据集D划分成对应于属性a测试的v个输出的v个划分产生的信息。信息增益率定义:
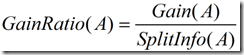
需要注意的是,增益率准则对可取值数目较少的属性有所偏好,因此,C4.5算法并不是直接选择增益率最大的候选划分属性,而是使用了一
个启发式:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
C4.5克服了ID3的两个缺点:
1、用信息增益选择属性时偏向于选择分枝比较多的属性值,即取值多的属性
2、不能处理连贯属性
数据集中,Outlook和Windy取离散值,Temperature和Humidity则取连续值。C4.5是如何处理连续属性的呢?实际上它先把连续属性转
换为离散属性再进行处理。虽然本质上属性的取值是连续的,但对于有限的采样数据它是离散的,如果有N条样本,那么我们有N-1种离散化
的方法:<=vj的分到左子树,>vj的分到右子树。计算这N-1种情况下最大的信息增益率。
在离散属性上只需要计算1次信息增益率,而在连续属性上却需要计算N-1次,计算量是相当大的。有办法可以减少计算量。对于连续属性先
进行排序,只有在决策属性发生改变的地方才需要切开。比如对Temperature进行排序
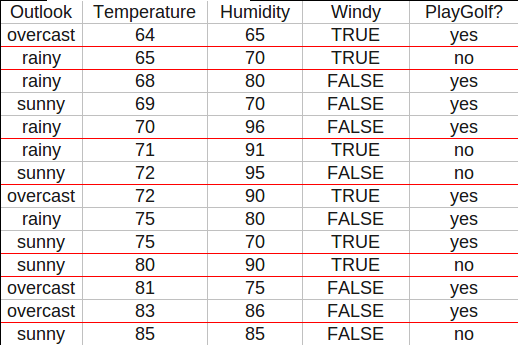
本来有13种离散化的情况,现在只需计算7种。如果利用增益率来选择连续值属性的分界点,会导致一些副作用。分界点将样本分成两个部
分,这两个部分的样本个数之比也会影响增益率。根据增益率公式,我们可以发现,当分界点能够把样本分成数量相等的两个子集时(我们
称此时的分界点为等分分界点),增益率的抑制会被最大化,因此等分分界点被过分抑制了。子集样本个数能够影响分界点,显然不合理。
因此在决定分界点是还是采用增益这个指标,而选择属性的时候才使用增益率这个指标。这个改进能够很好得抑制连续值属性的倾向。当然
还有其它方法也可以抑制这种倾向,比如MDL。
数据集如图所示,它表示的是天气情况与去不去打高尔夫球之间的关系。
C4.5并不是一个算法,而是一组算法——C4.5,非剪枝C4.5和C4.5规则。下图中的算法给出C4.5的基本工作流程:
我们可能有疑问,一个元组本身有很多属性,我们怎么知道首先要对哪个属性进行判断,接下来要对哪个属性进行判断?
一般而言,随着划分过程不断进行,我们希望决策树的分支节点所包含的样本尽可能属于同一类别,即节点的“纯度”越来越高。
划分选择
“信息熵”是度量样本集合纯度最常用的一种指标,样本集合D的信息熵定义为:
信息熵的值越小,则D的纯度越高。
现在假定按照属性a划分D中的元组,且属性a将D划分成v个不同的类。在该划分之后,为了得到准确的分类还需要的信息由下面的式子度量:
于是可计算出用属性a对样本集D进行划分所获得的“信息增益”
一般而言,信息增益越大,则意味着使用属性a来进行划分所获得的“纯度提升”越大。因此,我们可用信息增益来进行决策树的划分属性选择。
著名的ID3决策树算法就是以信息增益为准则来选择划分属性的。
但是,以信息增益为准则的话其实是有一个缺点,那就是它偏向于具有大量值的属性。什么意思呢?就是说在训练集中,某个属性所取的不同
值的个数越多,那么越有可能拿它来作为分裂属性。例如一个训练集中有10个元组,对于某一个属性a,它分别取1~10这十个数,如果对a进
行分裂将会分成10个类,那么对于每一个类Info(Dj)=0,从而式(2)为0,该属性划分所得到的信息增益(3)最大,但是这样的决策树显然
不具有泛化能力,无法对新样本进行有效预测。
正是基于此,ID3后面的C4.5采用了信息增益率这样一个概念。信息增益率使用“分裂信息”值将信息增益规范化。分类信息类似于Info(D),
定义如下:
这个值表示通过将训练数据集D划分成对应于属性a测试的v个输出的v个划分产生的信息。信息增益率定义:
需要注意的是,增益率准则对可取值数目较少的属性有所偏好,因此,C4.5算法并不是直接选择增益率最大的候选划分属性,而是使用了一
个启发式:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
C4.5克服了ID3的两个缺点:
1、用信息增益选择属性时偏向于选择分枝比较多的属性值,即取值多的属性
2、不能处理连贯属性
数据集中,Outlook和Windy取离散值,Temperature和Humidity则取连续值。C4.5是如何处理连续属性的呢?实际上它先把连续属性转
换为离散属性再进行处理。虽然本质上属性的取值是连续的,但对于有限的采样数据它是离散的,如果有N条样本,那么我们有N-1种离散化
的方法:<=vj的分到左子树,>vj的分到右子树。计算这N-1种情况下最大的信息增益率。
在离散属性上只需要计算1次信息增益率,而在连续属性上却需要计算N-1次,计算量是相当大的。有办法可以减少计算量。对于连续属性先
进行排序,只有在决策属性发生改变的地方才需要切开。比如对Temperature进行排序
本来有13种离散化的情况,现在只需计算7种。如果利用增益率来选择连续值属性的分界点,会导致一些副作用。分界点将样本分成两个部
分,这两个部分的样本个数之比也会影响增益率。根据增益率公式,我们可以发现,当分界点能够把样本分成数量相等的两个子集时(我们
称此时的分界点为等分分界点),增益率的抑制会被最大化,因此等分分界点被过分抑制了。子集样本个数能够影响分界点,显然不合理。
因此在决定分界点是还是采用增益这个指标,而选择属性的时候才使用增益率这个指标。这个改进能够很好得抑制连续值属性的倾向。当然
还有其它方法也可以抑制这种倾向,比如MDL。

相关文章推荐
- 使用Swift打造动态库SDK和DemoAPP时所遇到的(Xcode7.3)
- 关于c#的webbrows控件自动填写表单并获取提交后的网页内容
- POJ 2965(dfs ,规律)
- 3.1 电子书框架
- Image特效
- 理解 Android Build 系统
- Android获取手机信息和APP信息大全
- 第三周JAVA学习
- 搭建Drools开发环境
- 谈谈RGB、YUY2、YUYV、YVYU、UYVY、AYUV
- JavaSE入门学习32:Java常用类之时间日期相关类
- 学习javaEE每一天2016.3.28
- Very Sleepy使用图文教程
- poj 2985(并查集+线段树求K大数)
- JavaScript单步调试
- LRU Cache算法实现(leetcode)
- UML类图基本画法(startuml演示)
- File类
- poj 3268 Silver Cow Party(最短路)
- 百度插件uaredirect.js电脑版跳转到手机版网站