一致性Hash
2016-03-28 14:31
225 查看
一致性Hash算法
传统hash算法的缺陷如果有一个机器加入或退出这个集群,则所有的数据映射都无效了,如果是持久化存储则要做数据迁移,如果是分布式缓存,则其他缓存就失效了(重新hash分布),容易导致雪崩现象。
一致性hash算法作用
在设计分布式cache系统的时候,我们需要让key的分布均衡,并且在增加cache server后,cache的迁移做到最少。
选择具体的机器节点不在只依赖需要缓存数据的key的hash本身了,而是机器节点本身也进行了hash运算。
算法描述
求出机器节点的hash值(例如ip地址),将其分布到0~2^32的圆环上(顺时针):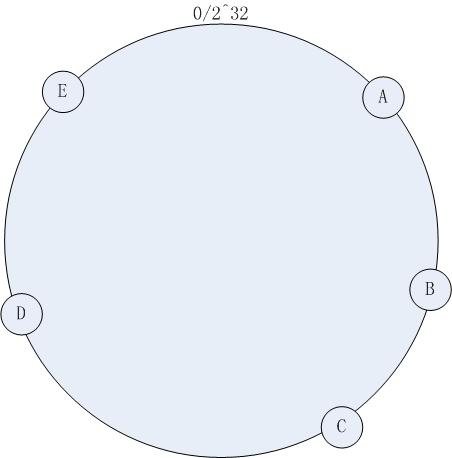
集群中有机器:A , B, C, D, E五台机器,通过一定的hash算法我们将其分布到如上图所示的环上
访问方式
如果有一个写入缓存的请求,其中Key值为K,计算器hash值Hash(K), Hash(K) 对应于环中的某一个点,如果该点对应没有映射到具体的某一个机器节点,那么顺时针查找,直到第一次找到有映射机器的节点,该节点就是确定的目标节点,如果超过了2^32仍然找不到节点,则命中第一个机器节点。比如 Hash(K) 的值介于A~B之间,那么命中的机器节点应该是B节点(如上图 )。
增加节点方式
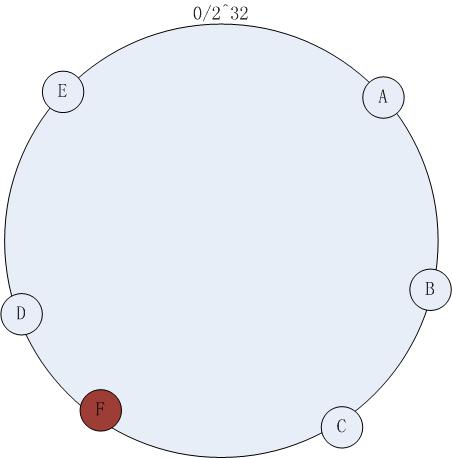
增加机器节点F之后,访问策略不改变,依然按照(2)中的方式访问,此时缓存命不中的情况依然不可避免,不能命中的数据是hash(K)在增加节点以前落在C~F之间的数据。尽管依然存在节点增加带来的命中问题,但是比较传统的 hash取模的方式,一致性hash已经将不命中的数据降到了最低。
Consistent Hashing最大限度地抑制了hash键的重新分布。
另外要取得比较好的负载均衡的效果,往往在服务器数量比较少的时候需要增加虚拟节点来保证服务器能均匀的分布在圆环上。因为使用一般的hash方法,服务器的映射地点的分布非常不均匀。使用虚拟节点的思想,为每个物理节点(服务器)在圆上分配100~200个点。这样就能抑制分布不均匀,最大限度地减小服务器增减时的缓存重新分布。用户数据映射在虚拟节点上,就表示用户数据真正存储位置是在该虚拟节点代表的实际物理服务器上。
应用场景分析
1、memcache的add方法:通过一致性hash算法确认当前客户端对应的cacheserver的hash值以及要存储数据key的hash进行对应,确认cacheserver,获取connection进行数据存储2、memcache的get方法:通过一致性hash算法确认当前客户端对应的cacheserver的hash值以及要提取数据的hash值,进而确认存储的cacheserver,获取connection进行数据提取
总结
1、一致性hash算法只是帮我们减少cache集群中的机器数量增减的时候,cache的数据能进行最少重建。只要cache集群的server数量有变化,必然产生数据命中的问题2、对于数据的分布均衡问题,通过虚拟节点的思想来达到均衡分配。当然,我们cache server节点越少就越需要虚拟节点这个方式来均衡负载。
3、我们的cache客户端根本不会维护一个map来记录每个key存储在哪里,都是通过key的hash和cacheserver(也许ip可以作为参数)的hash计算当前的key应该存储在哪个节点上。
4、当我们的cache节点崩溃了。我们必定丢失部分cache数据,并且要根据活着的cache server和key进行新的一致性匹配计算。有可能对部分没有丢失的数据也要做重建。
5、至于正常到达数据存储节点,如何找到key对应的数据,那就是cache server本身的内部算法实现了,此处不做描述。

相关文章推荐
- 【B/S】JavaScript简介
- jquery中append和after的区别
- 测试222
- 支付宝支付功能演示项目的搭建以及注意事项
- 【转】移动前端手机输入法自带emoji表情字符处理
- 抽签系统
- GoAhead 2.1.8嵌入式webserver源码分析学习(一)---开篇
- POJ1324 Holedox Moving(BFS)
- [BZOJ1027][JSOI2007]合金
- Android学习之定时执行后台任务
- [转载]放大器参数测试
- 在CentOS中使用 yum 安装MongoDB及服务器端配置
- 从一个页面跳转到另一个页面的任何位置处
- java 抽象工厂模式
- Android开发:实现APP自动填写注册验证码功能
- 单例模式(懒)写法整理(改之前标题“最佳写法”)
- 码农小汪-Hibernate学习3-Mapping declaration 映射定义
- C语言学习笔记之格式化I/O(scanf函数、printf函数)
- 15位随机数由大到小依次排序程序
- 又到清明节