Kafka集群部署及测试
2016-03-28 09:34
435 查看
题记
目前我们对大数据进行研究方向以Spark为主,其中Spark Streaming是可以接收动态数据流并进行处理,那么Spark Streaming支持多源的数据发送端,例如TCP、ZeroMQ、自然也包括Kafka,而且Kafka+SparkStreaming的技术融合也比较常用而且成熟,所以我们需要搭建一个Kafka集群进行流数据的测试。
--------------------------------------------------------------------------------------
Blog: http://blog.csdn.net/chinagissoft
QQ群:16403743
宗旨:专注于"GIS+"前沿技术的研究与交流,将云计算技术、大数据技术、容器技术、物联网与GIS进行深度融合,探讨"GIS+"技术和行业解决方案
转载说明:文章允许转载,但必须以链接方式注明源地址,否则追究法律责任!
--------------------------------------------------------------------------------------
环境介绍
目前我们的环境还是原有的Hadoop集群和Spark集群。三台集群,一台主节点,两台子节点。
192.168.12.210 master
192.168.12.211 slave1
192.168.12.212 slave2
同样,我们的目标在这三台机器部署Kafka集群,另外同时包括Zookeeper集群。
目前安装的kafka版本为:kafka_2.10-0.8.2.1(其中2.10是支持的Scala版本,0.8.2.1是kafka版本)
下载地址: https://kafka.apache.org/downloads.html
安装步骤
目前对于开源软件的部署,特别是在Linux环境下,基本上为绿色安装,也就是只需要解压缩软件包即可。
1、在210集群进行操作
解压缩kafka软件包
2、创建zookeeper的数据目录并设定服务器编号
3、修改%KAFKA_HOME%/config里面的配置文件,编辑 config/zookeeper.properties 文件,增加以下配置:
tickTime:zookeeper 服务器之间的心跳时间间隔,以毫秒为单位。
dataDir:zookeeper 的数据保存目录,我们也把 zookeeper 服务器的 ID 文件保存到这个目录下
clientPort:zookeeper 服务器会监听这个端口,然后等待客户端连接。
initLimit:zookeeper 集群中 follower 服务器和 leader 服务器之间建立初始连接时所能容忍的心跳次数的极限值。
syncLimit:zookeeper 集群中 follower 服务器和 leader 服务器之间请求和应答过程中所能容忍的心跳次数的极限值。
server.N:N 代表的是 zookeeper 集群服务器的编号。对于配置值,以 192.168.12.210:2888:3888 为例,192.168.12.210 表示该服务器的 IP 地址,2888 端口表示该服务器与 leader 服务器的数据交换端口,3888 表示选举新的 leader 服务器时候用到的通信端口。
4、修改%KAFKA_HOME%/config里面的配置文件
a. 编辑 config/server.properties 文件
broker.id:Kafka broker 的唯一标识,集群中不能重复。
port: Broker 的监听端口,用于监听 Producer 或者 Consumer 的连接。
host.name:当前 Broker 服务器的 IP 地址或者机器名。
zookeeper.contact:Broker 作为 zookeeper 的 client,可以连接的 zookeeper 的地址信息。
log.dirs:日志保存目录。
注意:修改zookeeper.connect为自己集群的IP及端口信息,HostName输入本机的IP,broker.id设置为唯一数字即可,例如210机器我设置的id=1.
b. 编辑 config/producer.properties 文件
broker.list:集群中 Broker 地址列表。
producer.type: Producer 类型,async 异步生产者,sync 同步生产者。
c. 编辑 config/consumer.properties 文件
zookeeper.connect: Consumer 可以连接的 zookeeper 服务器地址列表。
当我们将210机器的配置全部设置完毕之后,我们使用scp工具将kafka目录和zk_dir目录拷贝到211和212机器上,特别注意需要修改几个文件。
1、config/server.properties 文件的broker.id和hostname
2、zk_dir/myid
简单的可以将两个id对应起来,但是必须要保证集群环境中ID唯一
服务启动
对于kafka集群我们需要启动两个服务。
1、分别在三台不同集群启动zookeeper服务
前台启动:sh /home/supermap/kafka_2.10-0.8.2.1/bin/zookeeper-server-start.sh /home/supermap/kafka_2.10-0.8.2.1/config/zookeeper.properties
后台启动:nohup sh /home/supermap/kafka_2.10-0.8.2.1/bin/zookeeper-server-start.sh /home/supermap/kafka_2.10-0.8.2.1/config/zookeeper.properties &
注意:一开始启动第一台机器,服务信息会提示不能连接其他两台机器的消息输出。这个是正常的,如果其他两台机器服务都启动了就没有问题了。
2、分别在三台不同集群启动kafka服务
前台启动:sh /home/supermap/kafka_2.10-0.8.2.1/bin/kafka-server-start.sh /home/supermap/kafka_2.10-0.8.2.1/config/server.properties
后台启动:nohup sh /home/supermap/kafka_2.10-0.8.2.1/bin/kafka-server-start.sh /home/supermap/kafka_2.10-0.8.2.1/config/server.properties &
验证安装
1、创建和查看消息主题
连接zookeeper,创建一个名为user-behavior-topic的topic
查看此topic属性
查看已经创建的topic列表
2、创建消息生产者发送消息
3、创建消息消费者接收消息
目前我们对大数据进行研究方向以Spark为主,其中Spark Streaming是可以接收动态数据流并进行处理,那么Spark Streaming支持多源的数据发送端,例如TCP、ZeroMQ、自然也包括Kafka,而且Kafka+SparkStreaming的技术融合也比较常用而且成熟,所以我们需要搭建一个Kafka集群进行流数据的测试。
--------------------------------------------------------------------------------------
Blog: http://blog.csdn.net/chinagissoft
QQ群:16403743
宗旨:专注于"GIS+"前沿技术的研究与交流,将云计算技术、大数据技术、容器技术、物联网与GIS进行深度融合,探讨"GIS+"技术和行业解决方案
转载说明:文章允许转载,但必须以链接方式注明源地址,否则追究法律责任!
--------------------------------------------------------------------------------------
环境介绍
目前我们的环境还是原有的Hadoop集群和Spark集群。三台集群,一台主节点,两台子节点。
192.168.12.210 master
192.168.12.211 slave1
192.168.12.212 slave2
同样,我们的目标在这三台机器部署Kafka集群,另外同时包括Zookeeper集群。
目前安装的kafka版本为:kafka_2.10-0.8.2.1(其中2.10是支持的Scala版本,0.8.2.1是kafka版本)
下载地址: https://kafka.apache.org/downloads.html
安装步骤
目前对于开源软件的部署,特别是在Linux环境下,基本上为绿色安装,也就是只需要解压缩软件包即可。
1、在210集群进行操作
解压缩kafka软件包
tar –xvf kafka_2.10-0.8.2.1
2、创建zookeeper的数据目录并设定服务器编号
mkdir zk_dir然后再zk_dir目录下创建一个myid文件,编辑该文件,设置一个服务器唯一编号即可。例如在210机器上,myid文件只需要输入1即可。
3、修改%KAFKA_HOME%/config里面的配置文件,编辑 config/zookeeper.properties 文件,增加以下配置:
dataDir=/home/supermap/zk_dir/ clientPort=2181 initLimit=5 syncLimit=2 server.1=192.168.12.210:2888:3888 server.2=192.168.12.211:2888:3888 server.3=192.168.12.212:2888:3888
tickTime:zookeeper 服务器之间的心跳时间间隔,以毫秒为单位。
dataDir:zookeeper 的数据保存目录,我们也把 zookeeper 服务器的 ID 文件保存到这个目录下
clientPort:zookeeper 服务器会监听这个端口,然后等待客户端连接。
initLimit:zookeeper 集群中 follower 服务器和 leader 服务器之间建立初始连接时所能容忍的心跳次数的极限值。
syncLimit:zookeeper 集群中 follower 服务器和 leader 服务器之间请求和应答过程中所能容忍的心跳次数的极限值。
server.N:N 代表的是 zookeeper 集群服务器的编号。对于配置值,以 192.168.12.210:2888:3888 为例,192.168.12.210 表示该服务器的 IP 地址,2888 端口表示该服务器与 leader 服务器的数据交换端口,3888 表示选举新的 leader 服务器时候用到的通信端口。
4、修改%KAFKA_HOME%/config里面的配置文件
a. 编辑 config/server.properties 文件
supermap@master:~/kafka_2.10-0.8.2.1/config$ grep ^[a-z] server.properties broker.id=1 port=9092 host.name=192.168.12.210 num.network.threads=3 num.io.threads=8 socket.send.buffer.bytes=102400 socket.receive.buffer.bytes=102400 socket.request.max.bytes=104857600 log.dirs=/home/supermap/kafka-logs num.partitions=1 num.recovery.threads.per.data.dir=1 log.retention.hours=168 log.segment.bytes=1073741824 log.retention.check.interval.ms=300000 log.cleaner.enable=false zookeeper.connect=192.168.12.210:2181,192.168.12.211:2181,192.168.12.212:2181 zookeeper.connection.timeout.ms=6000
broker.id:Kafka broker 的唯一标识,集群中不能重复。
port: Broker 的监听端口,用于监听 Producer 或者 Consumer 的连接。
host.name:当前 Broker 服务器的 IP 地址或者机器名。
zookeeper.contact:Broker 作为 zookeeper 的 client,可以连接的 zookeeper 的地址信息。
log.dirs:日志保存目录。
注意:修改zookeeper.connect为自己集群的IP及端口信息,HostName输入本机的IP,broker.id设置为唯一数字即可,例如210机器我设置的id=1.
b. 编辑 config/producer.properties 文件
supermap@master:~/kafka_2.10-0.8.2.1/config$ grep ^[a-z] producer.properties metadata.broker.list=192.168.12.210:9092,192.168.12.211:9092,192.168.12.212:9092 producer.type=async compression.codec=none serializer.class=kafka.serializer.DefaultEncoder
broker.list:集群中 Broker 地址列表。
producer.type: Producer 类型,async 异步生产者,sync 同步生产者。
c. 编辑 config/consumer.properties 文件
supermap@master:~/kafka_2.10-0.8.2.1/config$ grep ^[a-z] consumer.properties zookeeper.connect=192.168.12.210:2181,192.168.12.211:2181,192.168.12.212:2181 zookeeper.connection.timeout.ms=6000 group.id=test-consumer-group
zookeeper.connect: Consumer 可以连接的 zookeeper 服务器地址列表。
当我们将210机器的配置全部设置完毕之后,我们使用scp工具将kafka目录和zk_dir目录拷贝到211和212机器上,特别注意需要修改几个文件。
1、config/server.properties 文件的broker.id和hostname
2、zk_dir/myid
简单的可以将两个id对应起来,但是必须要保证集群环境中ID唯一
服务启动
对于kafka集群我们需要启动两个服务。
1、分别在三台不同集群启动zookeeper服务
前台启动:sh /home/supermap/kafka_2.10-0.8.2.1/bin/zookeeper-server-start.sh /home/supermap/kafka_2.10-0.8.2.1/config/zookeeper.properties
后台启动:nohup sh /home/supermap/kafka_2.10-0.8.2.1/bin/zookeeper-server-start.sh /home/supermap/kafka_2.10-0.8.2.1/config/zookeeper.properties &
注意:一开始启动第一台机器,服务信息会提示不能连接其他两台机器的消息输出。这个是正常的,如果其他两台机器服务都启动了就没有问题了。
[2016-03-21 23:12:04,946] WARN Cannot open channel to 2 at election address /192.168.12.211:3888 (org.apache.zookeeper.server.quorum.QuorumCnxManager) java.net.ConnectException: Connection refused at java.net.PlainSocketImpl.socketConnect(Native Method) at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:339) at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:200) at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:182) at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392) at java.net.Socket.connect(Socket.java:579) at org.apache.zookeeper.server.quorum.QuorumCnxManager.connectOne(QuorumCnxManager.java:368) at org.apache.zookeeper.server.quorum.QuorumCnxManager.connectAll(QuorumCnxManager.java:402) at org.apache.zookeeper.server.quorum.FastLeaderElection.lookForLeader(FastLeaderElection.java:840) at org.apache.zookeeper.server.quorum.QuorumPeer.run(QuorumPeer.java:762) [2016-03-21 23:12:04,949] WARN Cannot open channel to 3 at election address /192.168.12.212:3888 (org.apache.zookeeper.server.quorum.QuorumCnxManager) java.net.ConnectException: Connection refused at java.net.PlainSocketImpl.socketConnect(Native Method) at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:339) at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:200) at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:182) at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392) at java.net.Socket.connect(Socket.java:579) at org.apache.zookeeper.server.quorum.QuorumCnxManager.connectOne(QuorumCnxManager.java:368) at org.apache.zookeeper.server.quorum.QuorumCnxManager.connectAll(QuorumCnxManager.java:402) at org.apache.zookeeper.server.quorum.FastLeaderElection.lookForLeader(FastLeaderElection.java:840) at org.apache.zookeeper.server.quorum.QuorumPeer.run(QuorumPeer.java:762)
2、分别在三台不同集群启动kafka服务
前台启动:sh /home/supermap/kafka_2.10-0.8.2.1/bin/kafka-server-start.sh /home/supermap/kafka_2.10-0.8.2.1/config/server.properties
后台启动:nohup sh /home/supermap/kafka_2.10-0.8.2.1/bin/kafka-server-start.sh /home/supermap/kafka_2.10-0.8.2.1/config/server.properties &
验证安装
1、创建和查看消息主题
连接zookeeper,创建一个名为user-behavior-topic的topic
supermap@master:~$ sh /home/supermap/kafka_2.10-0.8.2.1/bin/kafka-topics.sh --create \ > --replication-factor 3 \ > --partition 3 \ > --topic user-behavior-topic \ > --zookeeper 192.168.12.210:2181,192.168.12.211:2181,192.168.12.212:2181 Created topic "user-behavior-topic".
查看此topic属性
supermap@master:~$ sh /home/supermap/kafka_2.10-0.8.2.1/bin/kafka-topics.sh --describe --zookeeper 192.168.12.210:2181,192.168.12.211:2181,192.168.12.212:2181 --topic user-behavior-topic Topic:user-behavior-topic PartitionCount:3 ReplicationFactor:3 Configs: Topic: user-behavior-topic Partition: 0 Leader: 2 Replicas: 2,3,1 Isr: 2,3,1 Topic: user-behavior-topic Partition: 1 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2 Topic: user-behavior-topic Partition: 2 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3
查看已经创建的topic列表
supermap@master:~$ sh /home/supermap/kafka_2.10-0.8.2.1/bin/kafka-topics.sh --list --zookeeper 192.168.12.210:2181,192.168.12.211:2181,192.168.12.212:2181 user-behavior-topic user-behavior-topic
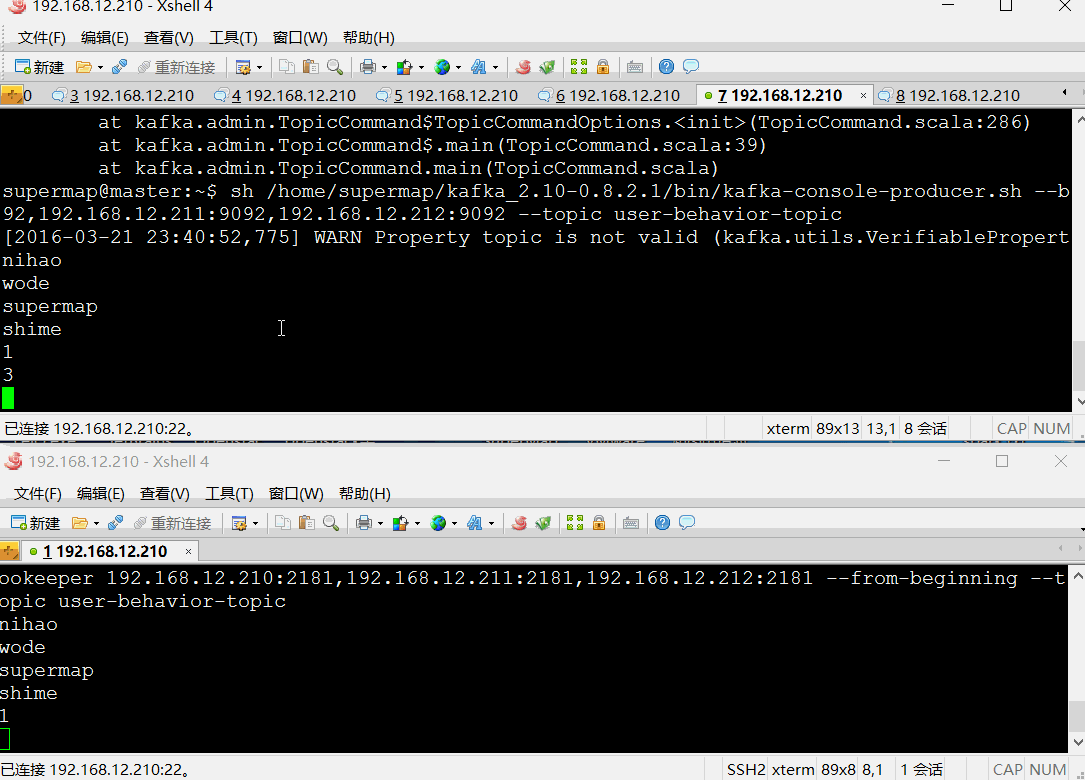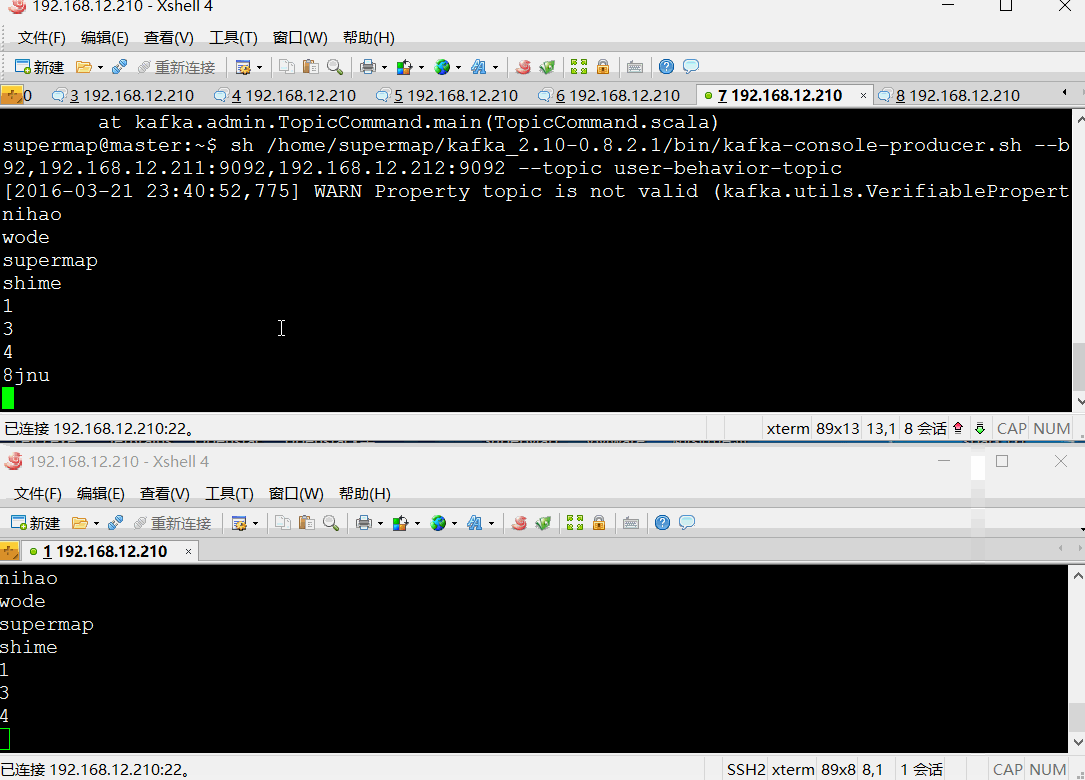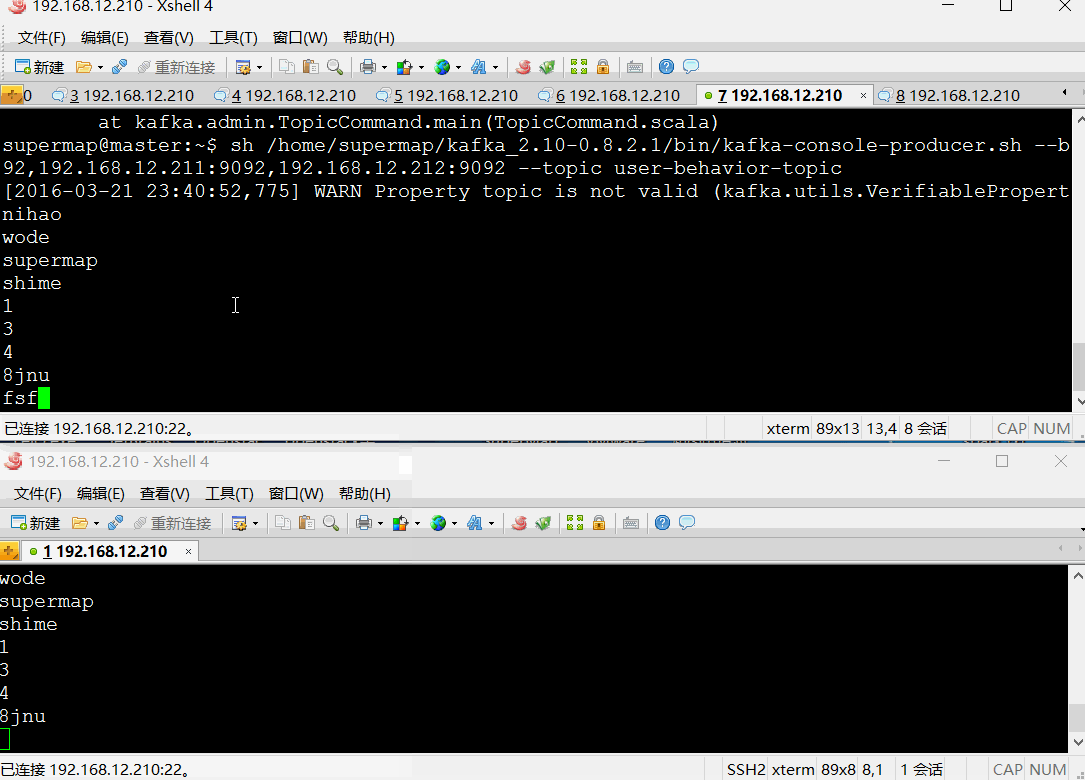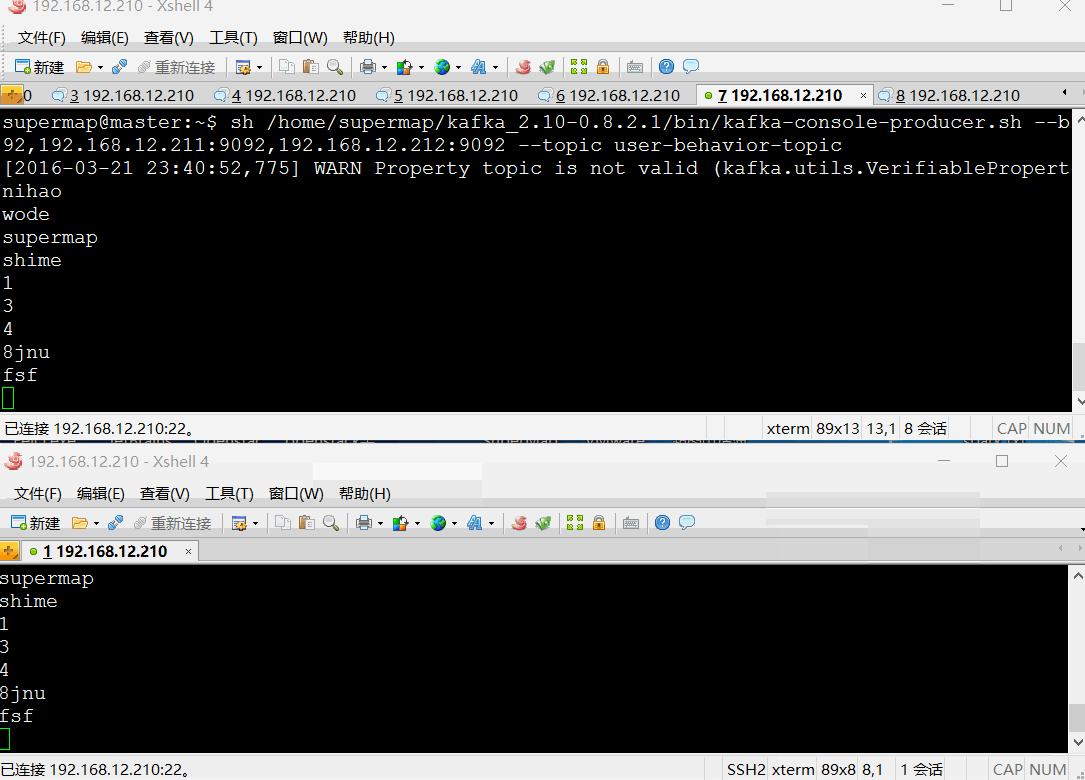
2、创建消息生产者发送消息
sh /home/supermap/kafka_2.10-0.8.2.1/bin/kafka-console-producer.sh --broker-list 192.168.12.210:9092,192.168.12.211:9092,192.168.12.212:9092 --topic user-behavior-topic
3、创建消息消费者接收消息
sh /home/supermap/kafka_2.10-0.8.2.1/bin/kafka-console-consumer.sh --zookeeper 192.168.12.210:2181,192.168.12.211:2181,192.168.12.212:2181 --from-beginning --topic user-behavior-topic

相关文章推荐
- Kafka 之 中级
- Shell脚本实现自动安装zookeeper
- 基于Zookeeper的使用详解
- Linux下Kafka单机安装配置方法(图文)
- Kafka使用入门教程第1/2页
- mesos + marathon + docker部署
- 基于zk的配置管理
- 搭建分布式架构4--ZooKeeper注册中心安装
- 搭建分布式架构5--ZooKeeper 集群的安装 3ff0
- SolrCloud4.9+zookeeper在CentOS上的搭建与安装
- 基于外部ZooKeeper的GlusterFS作为分布式文件系统的完全分布式HBase集群安装指南
- Storm集群的搭建
- Zookeeper配置项说明
- redis集群搭建
- Logstash 与Elasticsearch整合使用示例
- Kafka+Log4j实现日志集中管理
- 使用 RMI + ZooKeeper 实现远程调用框架
- 轻量级分布式 RPC 框架
- 整合Kafka到Spark Streaming——代码示例和挑战