Stanford 机器学习笔记 Week9 Recommender Systems
2016-03-26 23:35
260 查看
Predicting Movie Ratings
Problem Formulation
推荐系统举例: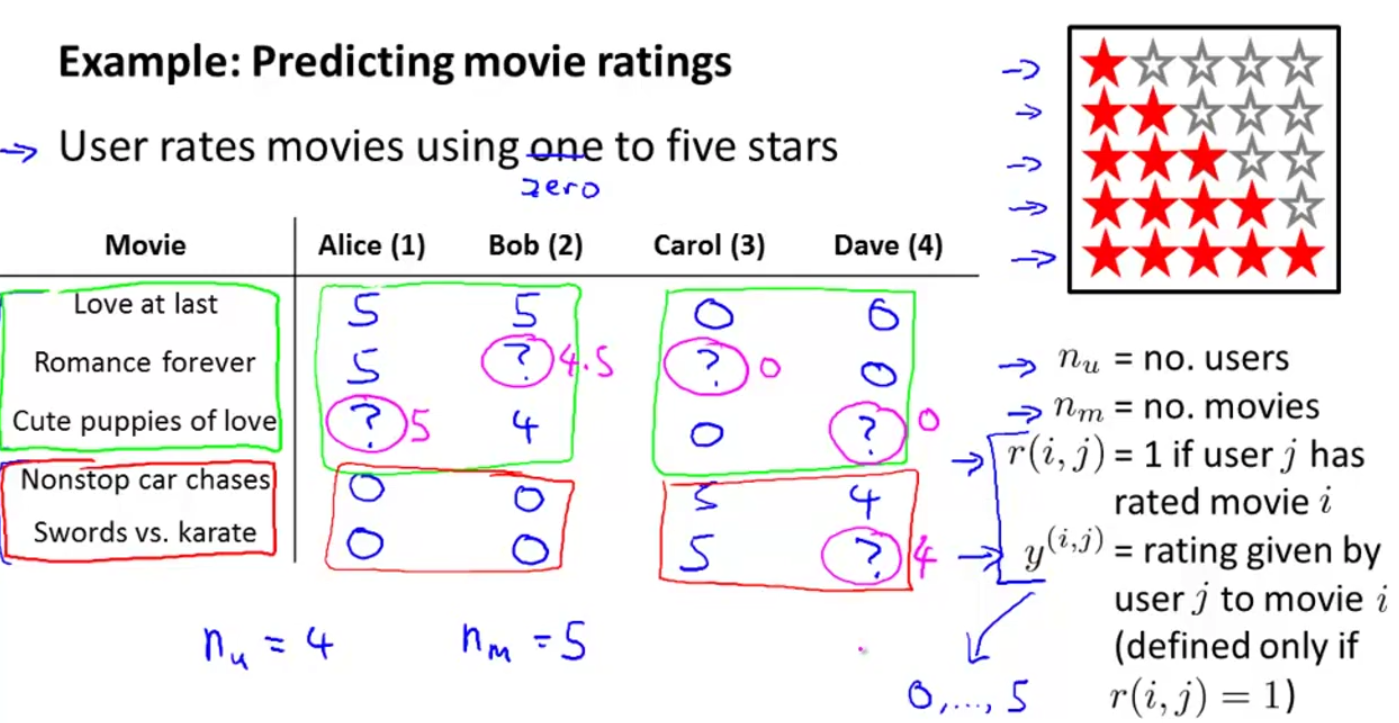
根据各个用户的打分记录,预测某用户对一没看过的电影的打分情况。
Content Based Recommendations
解决上一节问题的一个方法: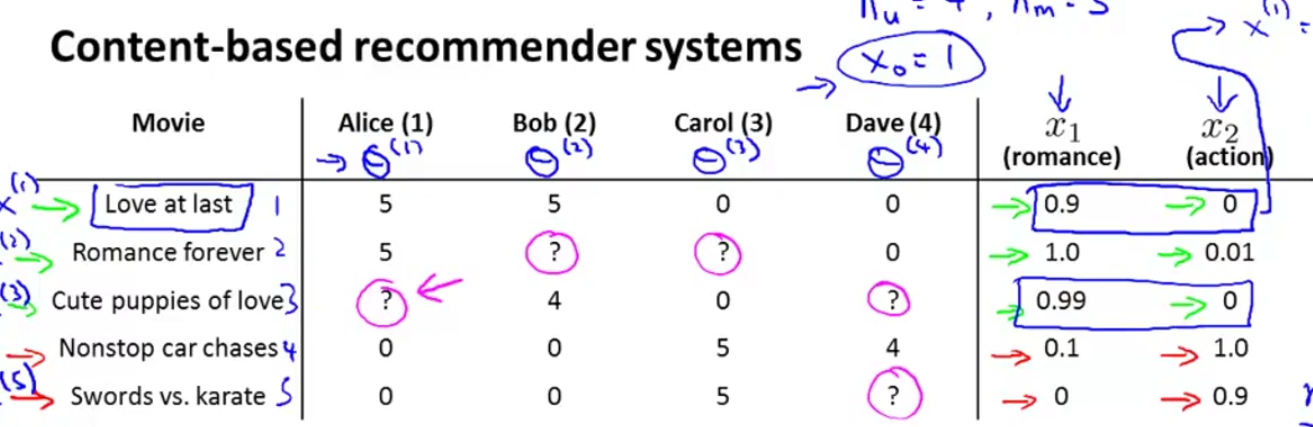
对于每个电影抽象出2个属性,romance 和 action,并手动赋值。再加上bias unit x0 = 1,就构成了表示每个电影属性的向量x(i)。那么这个问题就可以当成linear regression问题来解决。对于每个人求出向量θi ,第i人对第j电影的打分预测就是(θ(i))T*x(i)。
cost function:

做Gradient descent时的偏导数:

Collaborative Filtering
Collaborative Filtering
上一节每个电影的属性具体数值时人为设定的。假设我们已经知道每个人的喜好情况θ(i),那么我们可以根据打分情况计算出x(j),这又是一个线性回归问题。
偏导数为:
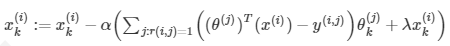
给定θ可以求出x,给定x可以求出θ,因此我们有一个初步的算法:随机初始化θ,然后计算X,再用X计算θ,X->θ->X->θ……直到收敛。这就是Collaborative Filtering(协同过滤)的思想。
Collaborative Filtering Algorithm
为了提高上一节算法的计算速度,可以将两个步骤合并起来:
因为两个步骤的Cost Function的前半部分实际是一样的,都是遍历了每个r(i,j) == 1的数对。新Cost Function同时计算θ和X。
注意因为同时考虑了θ和X,所以不需要手动设定bias unit θ0和X0了。
具体算法如下:

在初始化时,和神经网络中一样,为了计算出的x(i)不一样,不能全部初始化为0,而是初始化为接近0的极小值。
Low Rank Matrix Factorization
Vectorization: Low Rank Matrix Factorization
本节首先说明了上述算法可以使用矩阵运算实现。当运行算法结束后会得到各个电影许多属性的值,虽然这些属性具体表示什么含义需要人类自己去发现,但是在实践中,各属性的意义一般是十分明显的。
如何判断两个电影是否类似?计算属性向量的欧氏距离就可以了。
Implementational Detail: Mean Normalization
上述例子中,假设有一个人t没有对任何影片打过分。那么在执行算法时,Cost Function的前半部分中,没有一个r(i,j) == 1,因此前半部分与此人无关,会影响的只有后半部分的regularization part。这使得一定会将θ(t)预测为全0的向量。解决方式是:

对于每个电影计算评价的平均值,然后把每个元素减去该平均值,再执行协同过滤。做预测时,把得到的结果再加上平均值。这样对于一个没对任何电影做过评价的人,他的θ向量将会等于其他所有人对各电影打分的平均值。

相关文章推荐
- 用Python从零实现贝叶斯分类器的机器学习的教程
- My Machine Learning
- 机器学习---学习首页 3ff0
- 反向传播(Backpropagation)算法的数学原理
- 也谈 机器学习到底有没有用 ?
- 如何用70行代码实现深度神经网络算法
- 量子计算机编程原理简介 和 机器学习
- 近200篇机器学习&深度学习资料分享(含各种文档,视频,源码等)
- 已经证实提高机器学习模型准确率的八大方法
- 初识机器学习算法有哪些?
- 机器学习相关的库和工具
- 10个关于人工智能和机器学习的有趣开源项目
- 机器学习实践中应避免的7种常见错误
- 机器学习书单
- 北美常用的机器学习/自然语言处理/语音处理经典书籍
- 如何提升COBOL系统代码分析效率
- 自动编程体系设想(一)
- 自动编程体系设想(一)
- 支持向量机(SVM)算法概述
- [Ng机器学习公开课1]机器学习概述