利用lex和yacc做词法、语法分析
2016-03-25 21:48
399 查看
最近在一直做一个东西。设计一种脚本语言,再写一个翻译器,将这种脚本语言翻译成avr-gcc可以执行的C语言程序,再将得到的C语言程序利用avr-gcc编译器编译成Intel的hex文件格式,再写一个类似bootloader的东西,将这个hex文件以无线的方式加载到内存执行。这个类似bootloader的东西就是直接跟单片机芯片的存储器打交道,实现起来确实有点难度。万事开头难,只要做好第一步,慢慢来,总是可以实现的。
本以为这个翻译器很好做,无非就是按照一般编译原理的路子就是词法分析、语法分析、语义分析、中间代码生成等一系列步骤,最终转换成avr-gcc支持的C语言代码。事非经过不知难,结果第一步就卡住了。词法分析就是将输入的源程序分割成一系列的单词(Token),这个过程可以依赖正则表达式来实现。所以需要写一个正则表达式的引擎,解析正则表达式。自己也写了一个,测试了一下结果发现效率不是一般的低,呵呵。只好另辟思路,利用古老而又强大的工具yacc、lex来做。发现这个工具确实很强大,熟练掌握之,再用其来实现各种文本搜索、重新定义一种脚本语言等,开发效率会很快。不扯了,最近也在学lex和yacc。这里给出一个例子,用lex和yacc做一个计算器。
Linux系统下面自带了flex和bison,它们是lex和yacc的增强版。可以在lex中利用正则表达式定义符号。calculator.l的源码如下:
程序比较简单,不解释。不懂的可以参考《Lex和Yacc》,很实用的一本书。
然后接下来用yacc生成语法分析器,calculator.y的源码如下:
在第一个%%之前定义了一系列的终结符和非终结符。然后又产生了类似下面结构的巴斯科范式(BackusNormal Form):
上面的一系列规则其实就是定义了一个如下的文法G[line_list]:
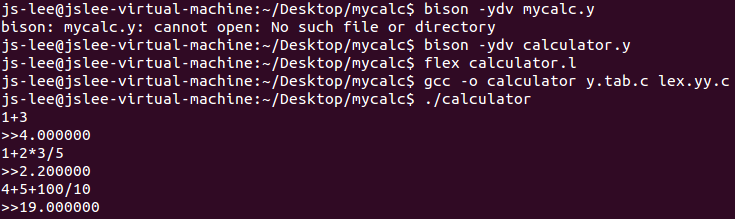
接下来编译并执行,操作如下图:
本以为这个翻译器很好做,无非就是按照一般编译原理的路子就是词法分析、语法分析、语义分析、中间代码生成等一系列步骤,最终转换成avr-gcc支持的C语言代码。事非经过不知难,结果第一步就卡住了。词法分析就是将输入的源程序分割成一系列的单词(Token),这个过程可以依赖正则表达式来实现。所以需要写一个正则表达式的引擎,解析正则表达式。自己也写了一个,测试了一下结果发现效率不是一般的低,呵呵。只好另辟思路,利用古老而又强大的工具yacc、lex来做。发现这个工具确实很强大,熟练掌握之,再用其来实现各种文本搜索、重新定义一种脚本语言等,开发效率会很快。不扯了,最近也在学lex和yacc。这里给出一个例子,用lex和yacc做一个计算器。
Linux系统下面自带了flex和bison,它们是lex和yacc的增强版。可以在lex中利用正则表达式定义符号。calculator.l的源码如下:
%{
#include <stdio.h>
#include "y.tab.h"
int
yywrap(void)
{
return 1;
}
%}
%%
"+" return ADD;
"-" return SUB;
"*" return MUL;
"/" return DIV;
"\n" return CR;
([1-9][0-9]*)|0|([0-9]+\.[0-9]*) {
double temp;
sscanf(yytext, "%lf", &temp);
yylval.double_value = temp;
return DOUBLE_LITERAL;
}
[ \t] ;
. {
fprintf(stderr, "lexical error.\n");
exit(1);
}
%%程序比较简单,不解释。不懂的可以参考《Lex和Yacc》,很实用的一本书。
然后接下来用yacc生成语法分析器,calculator.y的源码如下:
%{
#include<stdio.h>
#include<stdlib.h>
#define YYDEBUG 1
%}
%union {
int int_value;
double double_value;
}
%token <double_value> DOUBLE_LITERAL
%token ADD SUB MUL DIV CR
%type <double_value> expression term primary_expression
%%
line_list
: line
| line_list line
;
line
: expression CR
{
printf(">>%lf\n",$1);
}
expression
: term
| expression ADD term
{
$$=$1+$3;
}
| expression SUB term
{
$$=$1-$3;
}
;
term
: primary_expression
| term MUL primary_expression
{
$$=$1*$3;
}
| term DIV primary_expression
{
$$=$1/$3;
}
;
primary_expression
: DOUBLE_LITERAL
;
%%
int
yyerror(char const *str)
{
extern char *yytext;
fprintf(stderr,"parser error near %s\n",yytext);
return 0;
}
int main(void)
{
extern int yyparse(void);
extern FILE *yyin;
yyin=stdin;
if(yyparse()){
fprintf(stderr,"Error! Error! Error!\n");
exit(1);
}
}在第一个%%之前定义了一系列的终结符和非终结符。然后又产生了类似下面结构的巴斯科范式(BackusNormal Form):
line_list/*多行的规则*/ : line | line_list line ; line/*单行的规则*/ : expression CR/*一个表达式后面跟一个换行符*/ ; expression/*表达式的规则*/ : term | expression ADD term/*+得到的项*/ | expression SUB term/*-得到的项*/ ; term/*项的规则*/ : primary_expression | term MUL primary_expression/*乘得到的项*/ | term DIV primary_expression/*除得到的项*/ ; primary_expression/*一元表达式*/ : DOUBLE_LITERAL/*实数终结符*/ ;
上面的一系列规则其实就是定义了一个如下的文法G[line_list]:
line_list → line | line_list line line → expression CR expression → term | expression ADD term | expression SUB term term → primary_expression | term MUL primary_expression | term DIV primary_expression primary_expression → DOUBLE_LITERAL
接下来编译并执行,操作如下图:

相关文章推荐
- C语言中使用lex统计文本文件字符数
- How To Build a Yacc
- 学习cweb
- ruby解释器中的节点分类
- ruby中使用yacc定义的语法规则
- Lex Yacc应用初探
- JavaCC语法分析器
- yacc/lex windows 下 Parser Generator 使用指南
- 如何使用Lex和Yacc工具---Parser Generator+VC6.0配置
- VC6.0 + Parser Generator 2 详细设置
- GNU Make 使用手册(中译版)
- windows 下写yacc程序的经典计算器例子
- Windows下用yacc生成计算器c++程序
- Lex And Yacc
- lemon语法分析器生成器
- 词法分析器的自动生成
- 26th Oct Lab_Log
- 使用lex&yacc实现一个xml解析器 .
- Yacc: 另一个编译器的编译器(S.C.Johnson著,中文翻译)
- 初识 lex