超限学习机 (Extreme Learning Machine, ELM) 学习笔记 (一)
2016-03-25 17:15
190 查看
1. ELM 是什么
ELM的个人理解: 单隐层的前馈人工神经网络,特别之处在于训练权值的算法: 在单隐层的前馈神经网络中,输入层到隐藏层的权值根据某种分布随机赋予,当我们有了输入层到隐藏层的权值之后,可以根据最小二乘法得到隐藏层到输出层的权值,这也就是ELM的训练模型过程。
与BP算法不同,BP算法(后向传播算法),输入层到隐藏层的权值,和隐藏层到输出层的权值全部需要迭代求解(梯度下降法)
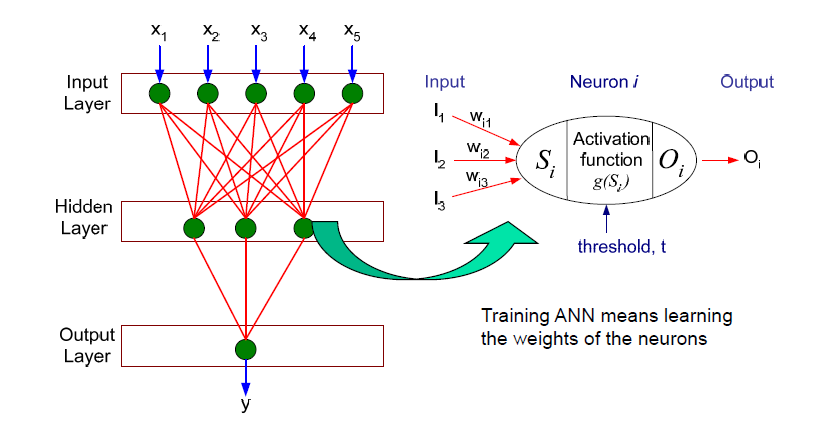
用一张老图来说明,也就是说上图中的Wi1,Wi2,Wi3 在超限学习机中,是随机的,固定的,不需要迭代求解的。我们的目标只需要求解从隐藏层到输出层的权值。毫无疑问,相对于BP算法,训练速度大大提高了。
2. ELM 的训练过程
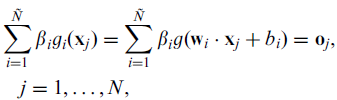
在上述公式中,wi 表示输入层到隐藏层的权值, bi表示系统偏置(bias),ß 则是我们的目标:隐藏层到输出层的权值,N 表示训练集的大小,oj 表示分类结果。为了无限逼近训练数据的真实结果,我们希望分类结果与真实结果t一致,那么也就是

所以上式可以表示为
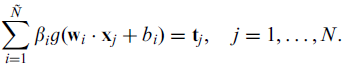
(懒了,不想用公式编辑器,TAT)
用矩阵表示,则

其中N 表示训练集的大小,N~ 表示隐藏层结点的数量,g(x)表示active function(激活函数?),g(x)要求无限可微。
怎么求解这个方程就成为了ELM的训练过程,恩。
求解方法:1. 传统的梯度下降法 (不说了,就是BP算法)
2. LS 最小二乘法方法
目标:最小化误差
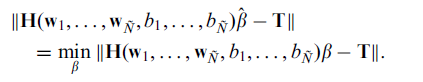
根据 Hß = T, 如果H 是一个方阵的话,ß可以直接求解为H-1T。
如果H不是, 最小误差的ß 为
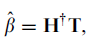
,其中H+ 为H的Moore-Penrose 广义逆。
先写到这里了,基本训练过程已经搞清楚了,可是一个这么简单的算法为什么可以work,还有待研究。。。
ELM的个人理解: 单隐层的前馈人工神经网络,特别之处在于训练权值的算法: 在单隐层的前馈神经网络中,输入层到隐藏层的权值根据某种分布随机赋予,当我们有了输入层到隐藏层的权值之后,可以根据最小二乘法得到隐藏层到输出层的权值,这也就是ELM的训练模型过程。
与BP算法不同,BP算法(后向传播算法),输入层到隐藏层的权值,和隐藏层到输出层的权值全部需要迭代求解(梯度下降法)
用一张老图来说明,也就是说上图中的Wi1,Wi2,Wi3 在超限学习机中,是随机的,固定的,不需要迭代求解的。我们的目标只需要求解从隐藏层到输出层的权值。毫无疑问,相对于BP算法,训练速度大大提高了。
2. ELM 的训练过程
在上述公式中,wi 表示输入层到隐藏层的权值, bi表示系统偏置(bias),ß 则是我们的目标:隐藏层到输出层的权值,N 表示训练集的大小,oj 表示分类结果。为了无限逼近训练数据的真实结果,我们希望分类结果与真实结果t一致,那么也就是
所以上式可以表示为
(懒了,不想用公式编辑器,TAT)
用矩阵表示,则
其中N 表示训练集的大小,N~ 表示隐藏层结点的数量,g(x)表示active function(激活函数?),g(x)要求无限可微。
怎么求解这个方程就成为了ELM的训练过程,恩。
求解方法:1. 传统的梯度下降法 (不说了,就是BP算法)
2. LS 最小二乘法方法
目标:最小化误差
根据 Hß = T, 如果H 是一个方阵的话,ß可以直接求解为H-1T。
如果H不是, 最小误差的ß 为
,其中H+ 为H的Moore-Penrose 广义逆。
先写到这里了,基本训练过程已经搞清楚了,可是一个这么简单的算法为什么可以work,还有待研究。。。

相关文章推荐
- startActivityForResult 页面跳转回调
- HNOI模拟 Day3.23
- iOS获取设备唯一标识的各种方法?IDFA、IDFV、UDID分别是什么含义?
- git stash和git stash pop
- 使用VS2008自带的dumpbin.exe查看dll包含的函数
- JQuery的复选框的attr("checked")一直为undefined问题
- Journey :Diary, Journal(旅行日记)
- Hibernate与 MyBatis的比较
- Android实用开发技巧之二:用Serializable方式及Parcelable方式实现Intent传递对象功能
- vc 利用无名管道 控制台程序实现cmd功能
- java url方法解释
- Journey :Diary, Journal(旅行日记)
- javascript之小积累-获取url传参的值
- ThreadLocal类理解
- 近期改BUG遇到的小问题及经验总结
- 下载网络文件HttpURLConnection.getContentLength()大小为 0
- 类扫描工具类
- android之多渠道打包---秒打秒打
- C++之拷贝控制操作入门(1)
- Java RTTI与反射(参照Java编程思想与新浪博客)