Python RabbitMQ
2016-03-21 10:26
501 查看
RabbitMQRabbitMQ是一个在AMQP基础上完整的,可复用的企业消息系统。他遵循Mozilla Public License开源协议。MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法。应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们。消 息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信,直接调用通常是用于诸如远程过程调用的技术。排队指的是应用程序通过 队列来通信。队列的使用除去了接收和发送应用程序同时执行的要求。RabbitMQ安装
启动/停止 service rabbitmq-server start/stop
安装API
pip install pika
or
easy_install pika
or
源码 https://pypi.python.org/pypi/pika
使用API操作RabbitMQ基于Queue可以实现生产者消费者模型,而对于RabbitMQ来说,生产和消费不再针对内存里的一个Queue对象,而是某台服务器上的RabbitMQ Server实现的消息队列。
1. acknowledgment 消息不丢失no-ack = False,如果生产者遇到情况(its channel is closed, connection is closed, or TCP connection is lost)挂掉了,那么,RabbitMQ会重新将该任务添加到队列中。
2. durable 消息不丢失
生产者消息持久化
3. 消息获取顺序
默认消息队列里的数据是按照顺序被消费者拿走,例如:消费者1 去队列中获取 奇数 序列的任务,消费者1去队列中获取 偶数 序列的任务。
如果Rabbit只管按顺序把消息发到各个消费者身上,不考虑消费者负载的话,很可能出现,一个机器配置不高的消费者那里堆积了很多消息处理不完,同时配置高的消费者却一直很轻松。为解决此问题,可以在各个消费者端,配置perfetch=1,意思就是告诉RabbitMQ在我这个消费者当前消息还没处理完的时候就不要再给我发新消息了。
channel.basic_qos(prefetch_count=1) 表示谁来谁取,不再按照奇偶数排列
4. 发布订阅
发布订阅和简单的消息队列区别在于,发布订阅会将消息发送给所有的订阅者,而消息队列中的数据被消费一次便消失。所以,RabbitMQ实现发布和订阅时,会为每一个订阅者创建一个队列,而发布者发布消息时,会将消息放置在所有相关队列中。
exchange type = fanout
5. 关键字发送 exchange type = direct之前事例,发送消息时明确指定某个队列并向其中发送消息,RabbitMQ还支持根据关键字发送,即:队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据 关键字 判定应该将数据发送至指定队列。
6. 模糊匹配 exchange type = topic在topic类型下,可以让队列绑定几个模糊的关键字,之后发送者将数据发送到exchange,exchange将传入”路由值“和 ”关键字“进行匹配,匹配成功,则将数据发送到指定队列。# 表示可以匹配 0 个 或 多个 单词
* 表示只能匹配 一个 单词
发送者路由值 队列中
www.google.com www.* -- 不匹配
www.baidu.com www.# -- 匹配
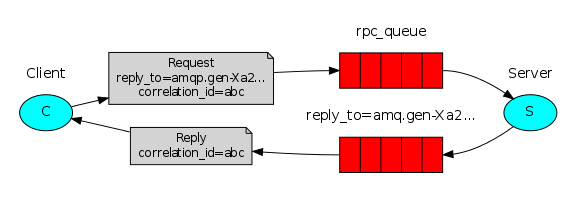
一个RPC流程是:
C 启动,然后创建一个匿名私有(exclusive=Ture)的反馈队列。
C 发送请求的时候,要附上reply_to(用户反馈的队列名)和correlation_id(反馈的***ID)。
请求被发送到 rpc_queue 队列.
S 等待队列. 发现有消息到达则计算fib(x)然后通过反馈队列反馈给C.
C 等待反馈队列,发现有反馈信息到达,比对反馈***ID。符合,发送下一个计算请求。不符合,再等。
RPC Server
RPC Client
安装配置epel源 # rpm -ivh http://dl.fedoraproject.org/pub/epel/6/i386/epel-release-6-8.noarch.rpm 安装erlang # yum -y install erlang 安装RabbitMQ # yum -y install rabbitmq-serverwin下安装推荐http://blog.csdn.net/a__java___a/article/details/17614797
启动/停止 service rabbitmq-server start/stop
安装API
pip install pika
or
easy_install pika
or
源码 https://pypi.python.org/pypi/pika
使用API操作RabbitMQ基于Queue可以实现生产者消费者模型,而对于RabbitMQ来说,生产和消费不再针对内存里的一个Queue对象,而是某台服务器上的RabbitMQ Server实现的消息队列。
import pika
# ######################### 生产者 #########################
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='MQ1')
channel.basic_publish(exchange='',routing_key='MQ1',body='Hello World!')
print(" [x] Sent 'Hello World!'")
connection.close()import pika
# ########################## 消费者 ##########################
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='MQ1')
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
channel.basic_consume(callback,queue='MQ1',no_ack=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()1. acknowledgment 消息不丢失no-ack = False,如果生产者遇到情况(its channel is closed, connection is closed, or TCP connection is lost)挂掉了,那么,RabbitMQ会重新将该任务添加到队列中。
import pika
# ########################## 消费者 ##########################
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='MQ1')
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
import time
time.sleep(10)
print('ok')
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_consume(callback,queue='MQ1',no_ack=False)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()2. durable 消息不丢失
生产者消息持久化
import pika
# ######################### 生产者 #########################
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
# 消息持久化
channel.queue_declare(queue='MQ2', durable=True)
channel.basic_publish(exchange='',routing_key='MQ2',body='Hello World!',
properties=pika.BasicProperties(
delivery_mode=2, # 消息持久化
))
print(" [x] Sent 'Hello World!'")
connection.close()import pika
# ########################## 消费者 ##########################
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='MQ2', durable=True) # 消息持久化
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
import time
time.sleep(10)
print('ok')
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_consume(callback,queue='MQ2',no_ack=False)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()3. 消息获取顺序
默认消息队列里的数据是按照顺序被消费者拿走,例如:消费者1 去队列中获取 奇数 序列的任务,消费者1去队列中获取 偶数 序列的任务。
如果Rabbit只管按顺序把消息发到各个消费者身上,不考虑消费者负载的话,很可能出现,一个机器配置不高的消费者那里堆积了很多消息处理不完,同时配置高的消费者却一直很轻松。为解决此问题,可以在各个消费者端,配置perfetch=1,意思就是告诉RabbitMQ在我这个消费者当前消息还没处理完的时候就不要再给我发新消息了。
channel.basic_qos(prefetch_count=1) 表示谁来谁取,不再按照奇偶数排列
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='MQ2',durable=True) # 消息持久化
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
import time
time.sleep(10)
print('ok')
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(callback,
queue='hello',
no_ack=False)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()4. 发布订阅
发布订阅和简单的消息队列区别在于,发布订阅会将消息发送给所有的订阅者,而消息队列中的数据被消费一次便消失。所以,RabbitMQ实现发布和订阅时,会为每一个订阅者创建一个队列,而发布者发布消息时,会将消息放置在所有相关队列中。
exchange type = fanout
import pika,sys
##------------------------发布者-----------------
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs',type='fanout')
message = ' '.join(sys.argv[1:]) or "info: Hello World!"
channel.basic_publish(exchange='logs',routing_key='',body=message)
print(" [x] Sent %r" % message)
connection.close()import pika
##------------------------订阅者-----------------
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs',type='fanout')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue #获取随机队列名
channel.queue_bind(exchange='logs',queue=queue_name)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r" % body)
channel.basic_consume(callback,queue=queue_name,no_ack=True)
channel.start_consuming()5. 关键字发送 exchange type = direct之前事例,发送消息时明确指定某个队列并向其中发送消息,RabbitMQ还支持根据关键字发送,即:队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据 关键字 判定应该将数据发送至指定队列。
import pika
# ######################### 生产者 #########################
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='direct_logs',type='direct')
message = 'Hello World!'
channel.basic_publish(exchange='direct_logs',
routing_key= 'mingyue', #绑定的关键字
body=message)
print(" [x] Sent %r" % (message))
connection.close()import pika
# # ########################## 消费者 ##########################
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='direct_logs',type='direct')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
# 绑定两个不同的关键字
channel.queue_bind(exchange='direct_logs',queue=queue_name,routing_key= 'shuoming')
channel.queue_bind(exchange='direct_logs',queue=queue_name,routing_key= 'mingyue')
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
channel.basic_consume(callback,queue=queue_name,no_ack=True)
channel.start_consuming()6. 模糊匹配 exchange type = topic在topic类型下,可以让队列绑定几个模糊的关键字,之后发送者将数据发送到exchange,exchange将传入”路由值“和 ”关键字“进行匹配,匹配成功,则将数据发送到指定队列。# 表示可以匹配 0 个 或 多个 单词
* 表示只能匹配 一个 单词
发送者路由值 队列中
www.google.com www.* -- 不匹配
www.baidu.com www.# -- 匹配
import pika
# ######################### 生产者 #########################
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='topic_logs',type='topic')
message = 'Hello World!'
channel.basic_publish(exchange='topic_logs',
routing_key= 'www.baidu.com', #匹配模糊关键字
body=message)
print(" [x] Sent %r" % (message))
connection.close()import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='topic_logs',type='topic')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
# 绑定两个不同的关键字
channel.queue_bind(exchange='topic_logs',queue=queue_name,routing_key= 'www.*')
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
channel.basic_consume(callback,queue=queue_name,no_ack=True)
channel.start_consuming()Remote procedure call (RPC)
RPC 远程过程调用。客户端C,向服务端S请求一项服务,官网举了一个计算fibonacci值的例子。C 向S请求计算fib(x),S 则计算,算完之后发给,或者说反馈给C。C收到反馈信息之后才能想S 继续请求服务。一个RPC流程是:
C 启动,然后创建一个匿名私有(exclusive=Ture)的反馈队列。
C 发送请求的时候,要附上reply_to(用户反馈的队列名)和correlation_id(反馈的***ID)。
请求被发送到 rpc_queue 队列.
S 等待队列. 发现有消息到达则计算fib(x)然后通过反馈队列反馈给C.
C 等待反馈队列,发现有反馈信息到达,比对反馈***ID。符合,发送下一个计算请求。不符合,再等。
RPC Server
import pika
import time
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='rpc_queue')
def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n-1) + fib(n-2)
def on_request(ch, method, props, body):
n = int(body)
print(" [.] fib(%s)" % n)
response = fib(n)
ch.basic_publish(exchange='',
routing_key=props.reply_to,
properties=pika.BasicProperties(correlation_id = \
props.correlation_id),
body=str(response))
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(on_request, queue='rpc_queue')
print(" [x] Awaiting RPC requests")
channel.start_consuming()RPC Client
import pika,uuid
class FibonacciRpcClient(object):
def __init__(self):
self.connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
self.channel = self.connection.channel()
result = self.channel.queue_declare(exclusive=True)
self.callback_queue = result.method.queue
self.channel.basic_consume(self.on_response, no_ack=True,
queue=self.callback_queue)
def on_response(self, ch, method, props, body):
if self.corr_id == props.correlation_id:
self.response = body
def call(self, n):
self.response = None
self.corr_id = str(uuid.uuid4())
self.channel.basic_publish(exchange='',
routing_key='rpc_queue',
properties=pika.BasicProperties(
reply_to = self.callback_queue,
correlation_id = self.corr_id,
),
body=str(n))
while self.response is None:
self.connection.process_data_events()
return int(self.response)
fibonacci_rpc = FibonacciRpcClient()
print(" [x] Requesting fib(30)")
response = fibonacci_rpc.call(30)
print(" [.] Got %r" % response)

相关文章推荐
- RPC failed; result=22, HTTP code = 411
- Python动态类型的学习---引用的理解
- Python3写爬虫(四)多线程实现数据爬取
- 垃圾邮件过滤器 python简单实现
- 下载并遍历 names.txt 文件,输出长度最长的回文人名。
- install and upgrade scrapy
- Scrapy的架构介绍
- Centos6 编译安装Python
- 使用Python生成Excel格式的图片
- 让Python文件也可以当bat文件运行
- [Python]推算数独
- Python中zip()函数用法举例
- Python中map()函数浅析
- Python将excel导入到mysql中
- Python在CAM软件Genesis2000中的应用
- 使用Shiboken为C++和Qt库创建Python绑定
- FREEBASIC 编译可被python调用的dll函数示例