关于 sklearn.decomposition.KernelPCA的简单介绍
2016-03-19 11:43
399 查看
from sklearn import decomposition import numpy as np A1_mean = [1, 1] A1_cov = [[2, .99], [1, 1]] A1 = np.random.multivariate_normal(A1_mean, A1_cov, 50) A2_mean = [5, 5] A2_cov = [[2, .99], [1, 1]] A2 = np.random.multivariate_normal(A2_mean, A2_cov, 50) A = np.vstack((A1, A2)) #A1:50*2;A2:50*2,水平连接 B_mean = [5, 0] B_cov = [[.5, -1], [-0.9, .5]] B = np.random.multivariate_normal(B_mean, B_cov, 100) import matplotlib.pyplot as plt plt.scatter(A[:,0],A[:,1],c='r',marker='o') plt.scatter(B[:,0],B[:,1],c='g',marker='*') plt.show() #很蠢的想法,把A和B合并,然后进行一维可分 kpca = decomposition.KernelPCA(kernel='cosine', n_components=1) AB = np.vstack((A, B)) AB_transformed = kpca.fit_transform(AB) plt.scatter(AB_transformed,AB_transformed,c='b',marker='*') plt.show() kpca = decomposition.KernelPCA(n_components=1) AB = np.vstack((A, B)) AB_transformed = kpca.fit_transform(AB) plt.scatter(AB_transformed,AB_transformed,c='b',marker='*') plt.show()
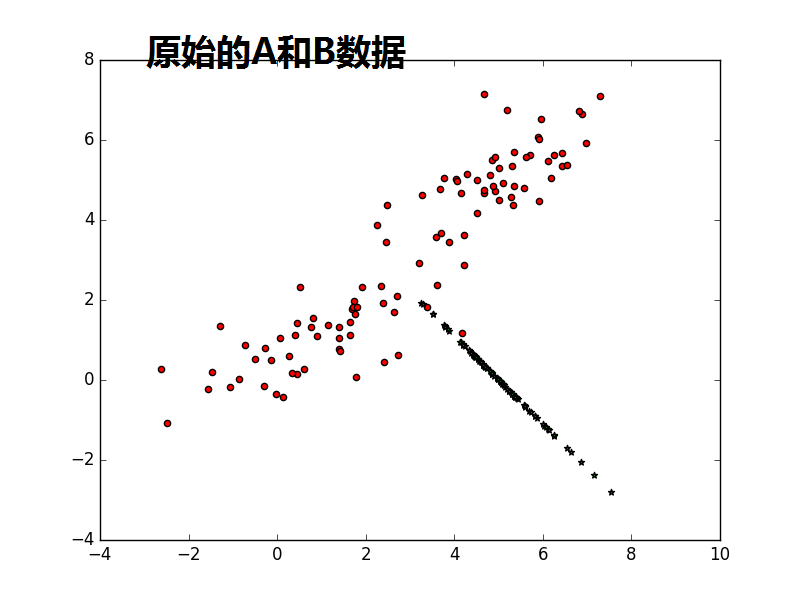

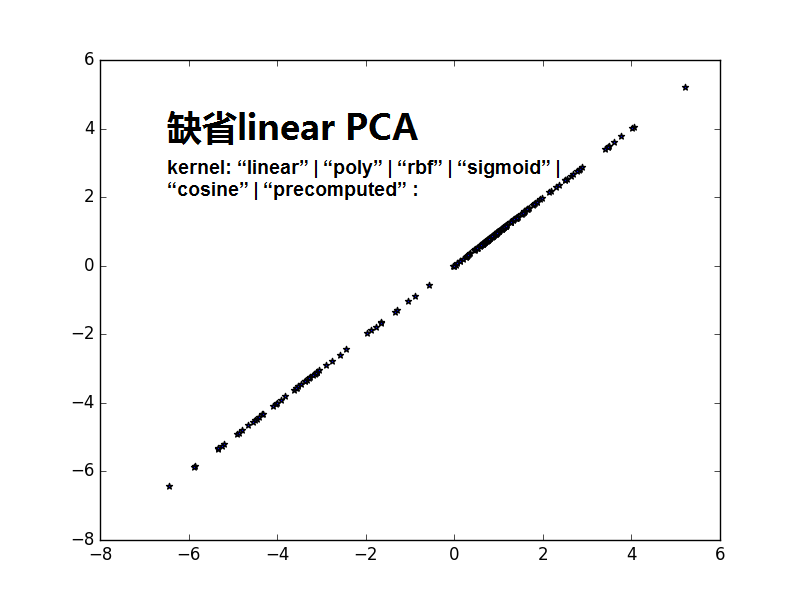
注意1:书上说consin PCA 比缺省的linear PCA要好,是不是consin PCA更紧致,数据不发散.
始终搞不懂什么时候用,什么时候不用
fit(X, y=None)
Fit the model from data in X.
ParametersX: array-like, shape (n_samples, n_features) :
Training vector, where n_samples in the number of samples and n_features is the numberof features.
fit_transform(X, y=None, **params)
Fit the model from data in X and transform X.
ParametersX: array-like, shape (n_samples, n_features) :
Training vector, where n_samples in the number of samples and n_features is the numberof features.

相关文章推荐
- swift获取手机通讯录列表
- AngularJS 控制器
- 释迦牟尼佛和阿弥陀佛有何区别?
- 安卓屏幕适应
- JAVA native method简介
- 希尔排序C++
- 题二 源代码编译:拓扑排序
- java -jar 执行 eclipse export 的 jar 包报错处理
- android开发之路10(文件的读写)
- BZOJ-1227 虔诚的墓主人 树状数组+离散化+组合数学
- Objective - C类的扩展
- 【笔记】mac配置文件
- BZOJ-1227 虔诚的墓主人 树状数组+离散化+组合数学
- php 调试
- sqlite显示查询所消耗时间
- mysql 连接字符串与SQL不同
- linux下/dev/dsp:No such file or directory解决方法
- double与flaot在杭电时的区别
- 右键快捷菜单压缩文件的消失问题解决办法!
- java 高级特性——注解