Hive学习路线图
2016-03-14 19:20
218 查看
Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop,
Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项目包括,YARN, Hcatalog, Oozie, Cassandra, Hama, Whirr, Flume, Bigtop, Crunch, Hue等。
从2011年开始,中国进入大数据风起云涌的时代,以Hadoop为代表的家族软件,占据了大数据处理的广阔地盘。开源界及厂商,所有数据软件,无一不向Hadoop靠拢。Hadoop也从小众的高富帅领域,变成了大数据开发的标准。在Hadoop原有技术基础之上,出现了Hadoop家族产品,通过“大数据”概念不断创新,推出科技进步。
作为IT界的开发人员,我们也要跟上节奏,抓住机遇,跟着Hadoop一起雄起!
关于作者:
张丹(Conan), 程序员Java,R,PHP,Javascript
weibo:@Conan_Z
blog: http://blog.fens.me
email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/hadoop-hive-roadmap/

前言
Hive是Hadoop家族中一款数据仓库产品,Hive最大的特点就是提供了类SQL的语法,封装了底层的MapReduce过程,让有SQL基础的业务人员,也可以直接利用Hadoop进行大数据的操作。就是这一个点,解决了原数据分析人员对于大数据分析的瓶颈。
让我们把Hive的环境构建起来,帮助非开发人员也能更好地了解大数据。
目录
Hive介绍
Hive学习路线图
我的使用经历
Hive的使用案例
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
详细地Hive的安装和使用介绍,请参考文章:Hive安装及使用攻略
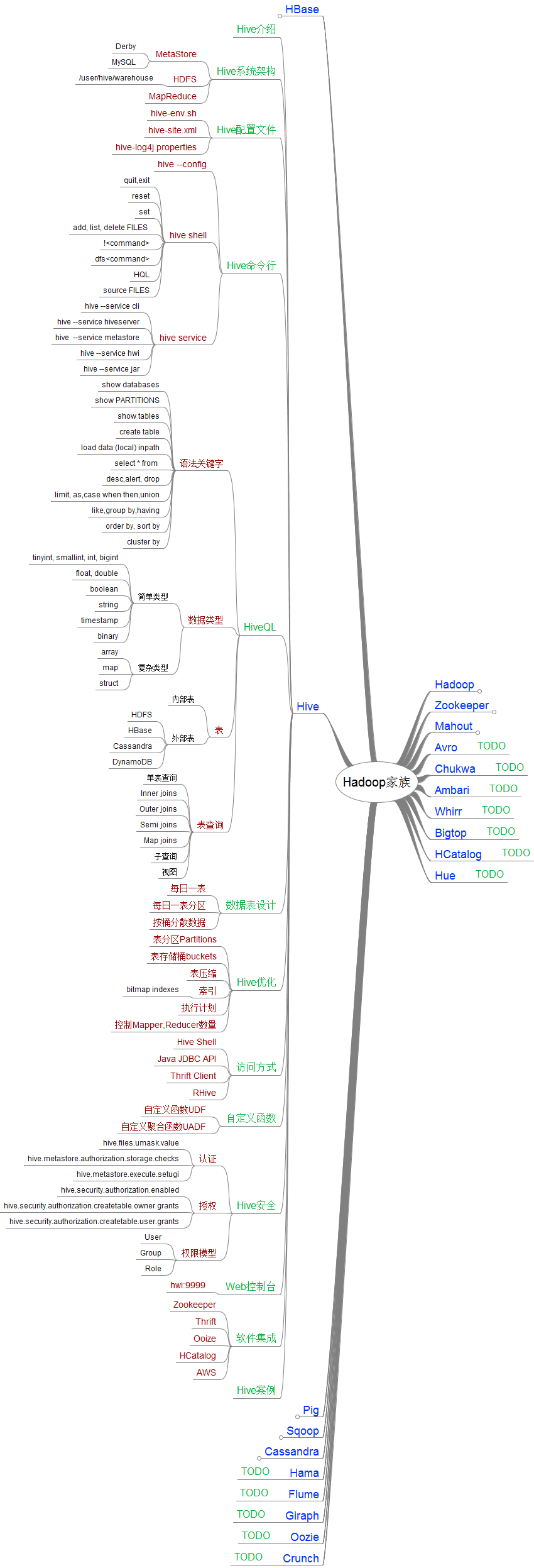
Hive的知识点,我已经列在图中,希望帮助其他人更好的了解Hive。
接下来,是我的使用经历,谁都没有捷径。把心踏实下来,就不那么难了。
1. 帮助无开发经验的数据分析人员,有能力处理大数据
2. 构建标准化的MapReduce开发过程
1). 帮助无开发经验的数据分析人员,有能力处理大数据
完全符合与Hive的设计理念,一直在强调,无需多言。
2). 构建标准化的MapReduce开发过程
这个方面是我们需要努力的方向。
首先,Hive已经用类SQL的语法封装了MapReduce过程,这个封装过程就是MapReduce的标准化的过程。
我们在做业务或者工具时,会针对场景用逻辑封装,这是第二层封装是在Hive之上的封装。在第二层封装时,我们要尽可能多的屏蔽Hive的细节,让接口单一化,低少灵活性,再次精简HQL的语法结构。只满足我们的系统要求,专用的接口。
在使用二次封装的接口时,我们已经可以不用知道Hive是什么, 更不用知道Hadoop是什么。我们只需要知道,SQL查询(SQL92标准),怎么写效率高,怎么写可以完成业务需要就可以了。
当我们完成了Hive的二次封装后,我们可以构建标准化的MapReduce开发过程。
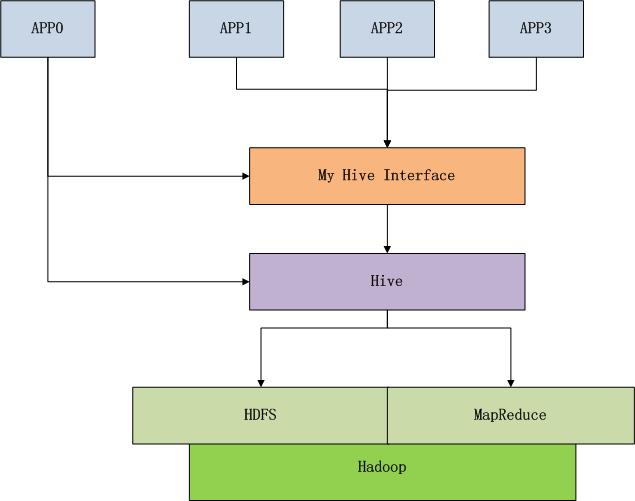
通过上图的思路,我们可以统一企业内部各种应用对于Hive的依赖,并且当人员素质升高后,有可以剥离Hive,用更优秀的底层解决方案来替换,如果封装的接口的不变,甚至替换Hive时业务使用都不知道,我们已经替换了Hive。
这个过程是需要经历的,也是有意义的。当我在考虑构建Hadoop分析工具时,以Hive作为Hadoop访问接口是最有效的。
3). 有关Hive的运维:
因为Hive是基于Hadoop构建的,简单地说就是一套Hadoop的访问接口,Hive本身并没有太多的东西,所以运维上面我们注意下面几个问题就行了。
1. 使用单独的数据库存储元数据
2. 定义合理的表分区和键
3. 设置合理的bucket数据量
4. 进行表压缩
5. 定义外部表使用规范
6. 合理的控制Mapper, Reducer数量
Hive安装及使用攻略
Hive导入10G数据的测试
R利剑NoSQL系列文章 之 Hive
用RHive从历史数据中提取逆回购信息
相关文章:
Hadoop家族产品学习路线图
转载请注明出处:
http://blog.fens.me/hadoop-hive-roadmap/
Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项目包括,YARN, Hcatalog, Oozie, Cassandra, Hama, Whirr, Flume, Bigtop, Crunch, Hue等。
从2011年开始,中国进入大数据风起云涌的时代,以Hadoop为代表的家族软件,占据了大数据处理的广阔地盘。开源界及厂商,所有数据软件,无一不向Hadoop靠拢。Hadoop也从小众的高富帅领域,变成了大数据开发的标准。在Hadoop原有技术基础之上,出现了Hadoop家族产品,通过“大数据”概念不断创新,推出科技进步。
作为IT界的开发人员,我们也要跟上节奏,抓住机遇,跟着Hadoop一起雄起!
关于作者:
张丹(Conan), 程序员Java,R,PHP,Javascript
weibo:@Conan_Z
blog: http://blog.fens.me
email: bsspirit@gmail.com
转载请注明出处:
http://blog.fens.me/hadoop-hive-roadmap/
前言
Hive是Hadoop家族中一款数据仓库产品,Hive最大的特点就是提供了类SQL的语法,封装了底层的MapReduce过程,让有SQL基础的业务人员,也可以直接利用Hadoop进行大数据的操作。就是这一个点,解决了原数据分析人员对于大数据分析的瓶颈。
让我们把Hive的环境构建起来,帮助非开发人员也能更好地了解大数据。
目录
Hive介绍
Hive学习路线图
我的使用经历
Hive的使用案例
1. Hive介绍
Hive起源于Facebook,它使得针对Hadoop进行SQL查询成为可能,从而非程序员也可以方便地使用。Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能,可以将SQL语句转换为MapReduce任务运行。Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
详细地Hive的安装和使用介绍,请参考文章:Hive安装及使用攻略
2. Hive学习路线图
Hive的知识点,我已经列在图中,希望帮助其他人更好的了解Hive。
接下来,是我的使用经历,谁都没有捷径。把心踏实下来,就不那么难了。
3. 我的使用经历
我使用Hive有两个考虑:1. 帮助无开发经验的数据分析人员,有能力处理大数据
2. 构建标准化的MapReduce开发过程
1). 帮助无开发经验的数据分析人员,有能力处理大数据
完全符合与Hive的设计理念,一直在强调,无需多言。
2). 构建标准化的MapReduce开发过程
这个方面是我们需要努力的方向。
首先,Hive已经用类SQL的语法封装了MapReduce过程,这个封装过程就是MapReduce的标准化的过程。
我们在做业务或者工具时,会针对场景用逻辑封装,这是第二层封装是在Hive之上的封装。在第二层封装时,我们要尽可能多的屏蔽Hive的细节,让接口单一化,低少灵活性,再次精简HQL的语法结构。只满足我们的系统要求,专用的接口。
在使用二次封装的接口时,我们已经可以不用知道Hive是什么, 更不用知道Hadoop是什么。我们只需要知道,SQL查询(SQL92标准),怎么写效率高,怎么写可以完成业务需要就可以了。
当我们完成了Hive的二次封装后,我们可以构建标准化的MapReduce开发过程。
通过上图的思路,我们可以统一企业内部各种应用对于Hive的依赖,并且当人员素质升高后,有可以剥离Hive,用更优秀的底层解决方案来替换,如果封装的接口的不变,甚至替换Hive时业务使用都不知道,我们已经替换了Hive。
这个过程是需要经历的,也是有意义的。当我在考虑构建Hadoop分析工具时,以Hive作为Hadoop访问接口是最有效的。
3). 有关Hive的运维:
因为Hive是基于Hadoop构建的,简单地说就是一套Hadoop的访问接口,Hive本身并没有太多的东西,所以运维上面我们注意下面几个问题就行了。
1. 使用单独的数据库存储元数据
2. 定义合理的表分区和键
3. 设置合理的bucket数据量
4. 进行表压缩
5. 定义外部表使用规范
6. 合理的控制Mapper, Reducer数量
4. Hive的使用案例
已经整理成文章的案例Hive安装及使用攻略
Hive导入10G数据的测试
R利剑NoSQL系列文章 之 Hive
用RHive从历史数据中提取逆回购信息
相关文章:
Hadoop家族产品学习路线图
转载请注明出处:
http://blog.fens.me/hadoop-hive-roadmap/

相关文章推荐
- 详解HDFS Short Circuit Local Reads
- Hadoop_2.1.0 MapReduce序列图
- 使用Hadoop搭建现代电信企业架构
- 分享Hive的一份胶片资料
- 单机版搭建Hadoop环境图文教程详解
- Hadoop生态上几个技术的关系与区别:hive、pig、hbase 关系与区别
- hadoop常见错误以及处理方法详解
- hadoop 单机安装配置教程
- hadoop的hdfs文件操作实现上传文件到hdfs
- hadoop实现grep示例分享
- ASP.NET学习路线图浅谈
- MongoDB中的MapReduce简介
- MongoDB学习笔记之MapReduce使用示例
- MongoDB中MapReduce编程模型使用实例
- Apache Hadoop版本详解
- MapReduce中ArrayWritable 使用指南
- Java函数式编程(七):MapReduce
- linux下搭建hadoop环境步骤分享
- java连接hdfs ha和调用mapreduce jar示例