Hadoop完全分布式集群配置
2016-03-13 13:23
351 查看
1.前话
寒假实在太闲了,所以闲着无聊地去了解“大数据”这个新概念,这几年到处都在说什么大数据时代的,不能不让我感到好奇啊。大数据有啥用?随便谷歌百度一大堆我也不多说了。
我自己的理解是,单个数据价值微乎其微,但当数据量极大时,那么就可以通过截取统计海量数据来进行分析,以此得出十分有价值的结果。
例如:
谷歌公司的搜索数据库,这数据库数据量是极大的,数据种类也是极大的,它存储着世界各地用户使用谷歌时键入的搜索关键词。
所以当我们对其进行大数据挖掘,对搜索关键词中含有“药”的关键字进行统计分析,就可以间接得出各个国家国民健康水平,病种分布,某病种发病的区域比重等,通过大数据挖掘,提取有用的信息,然后得出了十分有价值的信息。
因为这种数据库数据量极大,且多为分布式存储,直接遍历分析困难,且十分耗时。
所以出现了解决大数据如何挖掘的问题的技术——Hadoop
2.Hadoop是什么
我直接度娘一段吧:Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
总之,Hadoop是由Java编写的一套框架,它解决大数据挖掘的问题,而我们只需编写相应的MapReduce程序即可。
好啦,其他的也不介绍了(其实其他的我也不懂),先吧Hadoop整个运行框架搭建起来吧。
提示:你需要一定的linux基础 :)
3.框架搭建(Linux环境,Hadoop2.6.4)
官方文档入口 http://hadoop.apache.org/docs/r2.6.4/Hadoop有三种运行模式
本机模式(一台主机)
伪分布模式(一台主机)
完全分布模式(多台主机,即集群)
本机模式直接解压,修改
${HADOOP_PREFIX}/etc/hadoop/hadoop-env.sh,添加export JAVA_HOME=/usr/java/latest即可。
伪分布模式也直接跟着官方文档一步步配置即可。
伪分布模式是单机配置,将该单机作为master配置后的Hadoop程序文件夹分发给其他作为slaver的主机,增加配置内容即可实现完全分布模式配置。
3.0 准备
因为只有一台笔记本,要模拟完全分布模式就得使用虚拟机了。我使用的是Oracle VirtualBox,这是一款免费的软件。
本配置实例需要的镜像相应配置如下:
| hostname | ip地址 | 系统 |
|---|---|---|
| master | 192.168.1.113 | CentOS7 |
| slaver01 | 192.168.1.114 | CentOS7 |
| slaver02 | 192.168.1.115 | CentOS7 |
因此我只需配置作为master的主机,然后拷贝多两份系统镜像修改其hostname和ip地址即可。
一台主机别名master作为完全分布集群的NameNode主机,其他别名slaver*作为DataNode主机。
修改文件
/etc/hostname
master
修改文件
/etc/hosts
192.168.1.113 master 192.168.1.114 slaver01 192.168.1.115 slaver02
3.1 安装Java配置环境(略)
3.2 本机SSH免密码登陆(略)
3.3 下载解压并配置Hadoop路径
下载Hadoop程序压缩包解压至指定目录,例如
/usr/local/hadoop2.6.4
配置
/etc/profile,添加Hadoop目录路径
export HADOOP_PREFIX=/usr/local/hadoop,并添加至PATH中
export PATH=$PATH:$HADOOP_PREFIX
3.4 Hadoop完全分布模式配置
3.4.1 修改${HADOOP_PREFIX}/etc/hadoop/hadoop-env.sh
添加内容 export JAVA_HOME=/usr/java/latest
3.4.2 修改${HADOOP_PREFIX}/etc/hadoop/core-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop-2.6.4/tmp</value> </property> </configuration>
3.4.3 修改${HADOOP_PREFIX}/etc/hadoop/hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/usr/local/hadoop-2.6.4/data/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/usr/local/hadoop-2.6.4/data/datanode</value> </property> </configuration>
3.4.4 修改${HADOOP_PREFIX}/etc/hadoop/mapred-site.xml
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> </configuration>
3.4.5 修改${HADOOP_PREFIX}/etc/hadoop/yarn-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<description>The hostname of the ResourceManager.</description>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>${yarn.resourcemanager.hostname}:8090</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
</configuration>3.4.5 修改${HADOOP_PREFIX}/etc/hadoop/slaves
该slaves文件需填写DataNode的IP地址,前面已配置/etc/hosts因此填写hostname即可
slaver01 slaver02
3.5 拷贝多两份master系统镜像
修改拷贝出的系统hostname分别为 slaver01 和 slaver023.6 启动
3.6.1 首先格式化NameNode
执行命令hdfs namenode -format
3.6.2 启动所有服务
进入目录${HADOOP_PREFIX}/sbin执行命令
./start-all.sh
特别注意,防火墙允许相应端口或者关闭防火墙
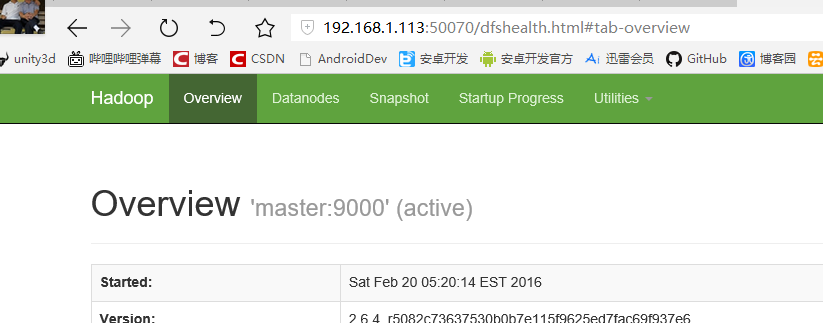
浏览器键入 http://192.168.1.113:50070/ 可查看Hadoop运行信息,若NameNode启动成功和DataNode也存在列表中说明配置成功。

相关文章推荐
- 详解HDFS Short Circuit Local Reads
- Hadoop_2.1.0 MapReduce序列图
- 使用Hadoop搭建现代电信企业架构
- 分布式版本管理git入门指南使用资料汇总及文章推荐
- RedHat 5.8 安装Oracle 11gR2_Grid集群
- 单机版搭建Hadoop环境图文教程详解
- mysql集群之MMM简单搭建
- 康诺云推出三款智能硬件产品,为健康管理业务搭建数据池
- C#分布式事务的超时处理实例分析
- MySQL中使用innobackupex、xtrabackup进行大数据的备份和还原教程
- Erlang分布式节点中的注册进程使用实例
- MySQL的集群配置的基本命令使用及一次操作过程实录
- MySQL slave_net_timeout参数解决的一个集群问题案例
- hadoop常见错误以及处理方法详解
- Redis 集群搭建和简单使用教程
- hadoop 单机安装配置教程
- hadoop的hdfs文件操作实现上传文件到hdfs
- hadoop实现grep示例分享
- Windows Server 2003 下配置 MySQL 集群(Cluster)教程