linux下的grep,egrep及正则表达式
2016-03-12 17:16
531 查看
一, linux上常用的文本搜索工具,grep家族和正则表达式及介绍linux上常用的文本搜索工具:
grep(egrep,fgrep):文本搜索工具;基于”pattern“对给定文本进行搜索操作; sed:Stream EDitor,流编辑器,行编辑工具;文本编辑工具; awk:GNU awk,文本格式化工具;文本报告生成器;
正则表达式:由一类特殊字符及文本字符所编写的模式,其有些字符不表示其字面意义,而是用于表示控制或通配的功能; 一般分为两类: 基本正则表达式:BRE 扩展正则表达式:ERE grep家族: grep:支持使用基本正则表达式; egrep:支持使用扩展正则表达式; fgrep:不支持使用正则表达式; grep命令和基本正则表达式 grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配到的行打印出来。grep全称是Globally search for a Regular Expression and print out the line,表示全局搜索正则表达式并打印匹配结果的意思。
作用:文本搜索工具,根据用户指定的”pattern(过滤条件)“对目标文本逐行进行匹配检查;打印出符合条件的行; 模式:由文本字符及正则表达式元字符所编写的过滤条件; 格式:grep [OPTIONS] PATTERN [FILE...] 常用选项:-i:忽略字符大小写
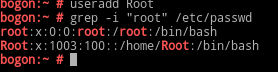
-o:仅显示匹配 到的文本自身
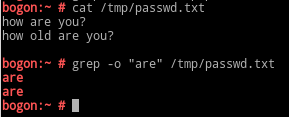
--color=auto:对匹配到的文本着色后高亮显示

-v:显示除匹配结果以外的所有内容
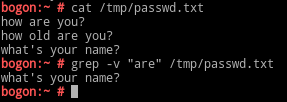
-q, --quiet, --silient:静默模式,不输出任何信息;
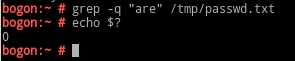
-e PATTERN, --regexp=PATTERN:多模式机制;
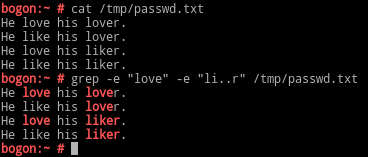
-A n : n为数字,表示显示匹配到内容及其后面的n行
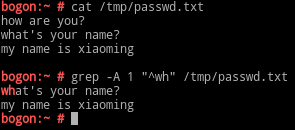
-B n : n为数字,表示显示匹配到内容及其前面的n行
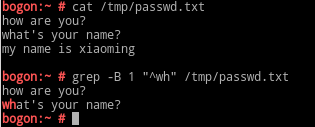
-C n : n为数字,表示显示匹配到内容及其前后的n行
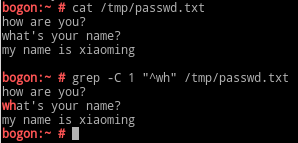
-E:等同于egrep,支持扩展的正则表达式;
-F, --fixed-strings:支持使用固定字符串,不支持正则表达式,相当于fgrep;
-G, --basic-regexp:支持使用基本正则表达式;
-P, --perl-regexp:支持使用pcre正则表达式;基本正则表达式元字符
位置锚定:^:行首锚定;用于模式的最左侧;格式为:^PATTERN
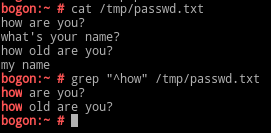
$:行尾锚定;用于模式的最右侧;格式为:PATTERN$
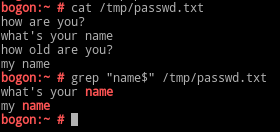
^$:空白行;^[[:space:]]*$:空行或包含空白字符的行;单词:非特殊字符组成的连续字符(字符串)都称为单词; \< 或 \b:词首锚定,用于单词模式的左侧; \> 或 \b:词尾锚定,用于单词模式的右侧; \<PATTERN\>:匹配完整单词;
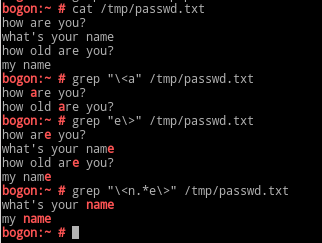
字符匹配:
.:匹配任意单个字符;
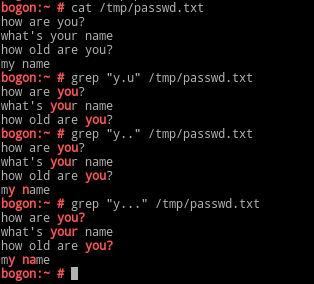
[ ]:匹配范围内的任意单个字符;
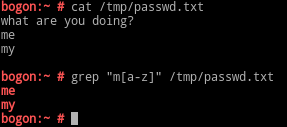
[^ ]:匹配范围外的任意单个字符;
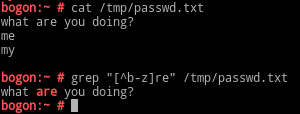
[[:digit:]]:任意数字;
[[:lower:]]:任意小写字母; [[:upper:]]:任意大写字母; [[:alpha:]]:任意字母; [[:alnum:]]:任意的字母和数字; [[:space:]]:空白字符; [[:blank:]]:空格和Tab键等; [[:punct:]]:所有的标点符号。匹配次数:用在要指定其出现的次数的字符的后面,用于限制其前面字符出现的次数,默认工作于贪婪模式;
*:匹配前面的字符任意次(0,1或多次)
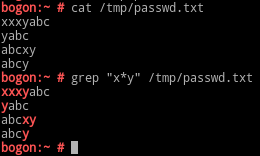
.*:任意长度的任意字符;
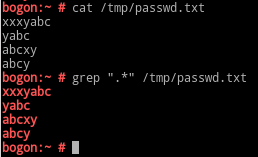
\+:匹配前面的字符至少1次;
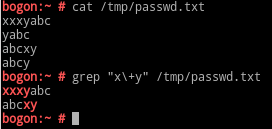
\?:匹配前面的0次或1次,即前面的字符可有可无;(大于等于0,小于等于1)
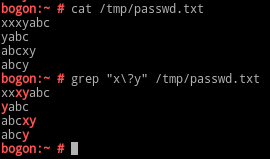
\{m\}:其前面的字符出现m次,m为非负整数;
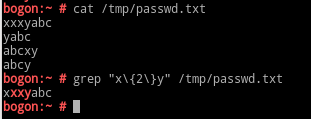
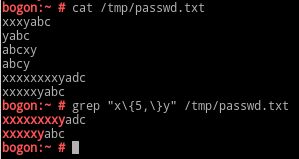
\{m,n\}:其前面的字符出现m次,m为非负整数;[m,n]
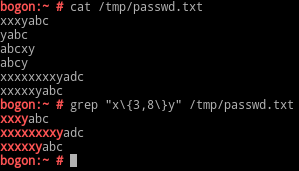
\{0,n\}:至多n次
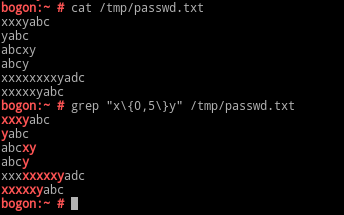
\{m,\}:至少m次;
分组及引用
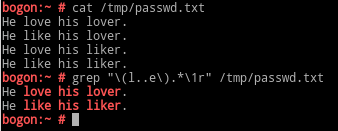
\(PATTERN\):将此PATTERN匹配到的字符当作一个不可侵害整体进行处理。 Note:分组括号中的模式匹配到的字符会被正则表达式引擎自动记录于内部的变量中,这些变量是\1, \2, \3, ... pat1\(pat2\)pat3\(pat4\(pat5\)pat6\) \n:模式中第n个左括号以及与之匹配的右括号之间的模式所匹配到的字符串;(不是模式,而是模式匹配的结果) \1:第一组括号中的pattern匹配到的字符串; \2:第二组括号中的pattern匹配到的字符串; ……后向引用:引用前面的分组括号中的模式所匹配到的字符;
egrep命令和扩展正则表达式:
egrep [OPTIONS] PATTERN [FILE...]
注:常用选项与grep一致,参考上述grep的常用选项即可。egrep和grep的区别地方:+ : 表示匹配前面的字符至少一次
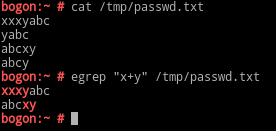
? : 等同于grep中的\?,在egrep中不需要转义() : 等同于grep中的\(\),在egrep中不需要转义{} : 等同于grep中的\{\},在egrep中不需要转义
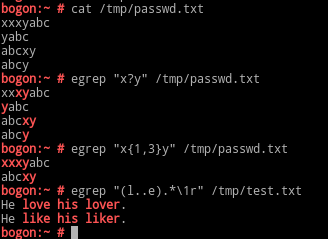
分组及引用:
(pattern):分组,括号中的模式匹配到的字符会被记录于正则表达式引擎内部的变量中;后向引用:\1, \2, ...
| : 表示匹配符号两边的任意一边,比如a|b,表示匹配a或者b
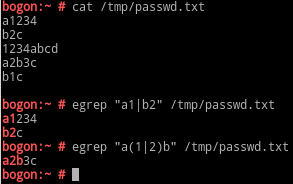
注意,| 左右带括号和不带括号的区别
以上就是grep和egrep及正则表达式的简单用法。
grep(egrep,fgrep):文本搜索工具;基于”pattern“对给定文本进行搜索操作; sed:Stream EDitor,流编辑器,行编辑工具;文本编辑工具; awk:GNU awk,文本格式化工具;文本报告生成器;
正则表达式:由一类特殊字符及文本字符所编写的模式,其有些字符不表示其字面意义,而是用于表示控制或通配的功能; 一般分为两类: 基本正则表达式:BRE 扩展正则表达式:ERE grep家族: grep:支持使用基本正则表达式; egrep:支持使用扩展正则表达式; fgrep:不支持使用正则表达式; grep命令和基本正则表达式 grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配到的行打印出来。grep全称是Globally search for a Regular Expression and print out the line,表示全局搜索正则表达式并打印匹配结果的意思。
作用:文本搜索工具,根据用户指定的”pattern(过滤条件)“对目标文本逐行进行匹配检查;打印出符合条件的行; 模式:由文本字符及正则表达式元字符所编写的过滤条件; 格式:grep [OPTIONS] PATTERN [FILE...] 常用选项:-i:忽略字符大小写
-o:仅显示匹配 到的文本自身
--color=auto:对匹配到的文本着色后高亮显示
-v:显示除匹配结果以外的所有内容
-q, --quiet, --silient:静默模式,不输出任何信息;
-e PATTERN, --regexp=PATTERN:多模式机制;
-A n : n为数字,表示显示匹配到内容及其后面的n行
-B n : n为数字,表示显示匹配到内容及其前面的n行
-C n : n为数字,表示显示匹配到内容及其前后的n行
-E:等同于egrep,支持扩展的正则表达式;
-F, --fixed-strings:支持使用固定字符串,不支持正则表达式,相当于fgrep;
-G, --basic-regexp:支持使用基本正则表达式;
-P, --perl-regexp:支持使用pcre正则表达式;基本正则表达式元字符
位置锚定:^:行首锚定;用于模式的最左侧;格式为:^PATTERN
$:行尾锚定;用于模式的最右侧;格式为:PATTERN$
^$:空白行;^[[:space:]]*$:空行或包含空白字符的行;单词:非特殊字符组成的连续字符(字符串)都称为单词; \< 或 \b:词首锚定,用于单词模式的左侧; \> 或 \b:词尾锚定,用于单词模式的右侧; \<PATTERN\>:匹配完整单词;
字符匹配:
.:匹配任意单个字符;
[ ]:匹配范围内的任意单个字符;
[^ ]:匹配范围外的任意单个字符;
[[:digit:]]:任意数字;
[[:lower:]]:任意小写字母; [[:upper:]]:任意大写字母; [[:alpha:]]:任意字母; [[:alnum:]]:任意的字母和数字; [[:space:]]:空白字符; [[:blank:]]:空格和Tab键等; [[:punct:]]:所有的标点符号。匹配次数:用在要指定其出现的次数的字符的后面,用于限制其前面字符出现的次数,默认工作于贪婪模式;
*:匹配前面的字符任意次(0,1或多次)
.*:任意长度的任意字符;
\+:匹配前面的字符至少1次;
\?:匹配前面的0次或1次,即前面的字符可有可无;(大于等于0,小于等于1)
\{m\}:其前面的字符出现m次,m为非负整数;
\{m,n\}:其前面的字符出现m次,m为非负整数;[m,n]
\{0,n\}:至多n次
\{m,\}:至少m次;
分组及引用
\(PATTERN\):将此PATTERN匹配到的字符当作一个不可侵害整体进行处理。 Note:分组括号中的模式匹配到的字符会被正则表达式引擎自动记录于内部的变量中,这些变量是\1, \2, \3, ... pat1\(pat2\)pat3\(pat4\(pat5\)pat6\) \n:模式中第n个左括号以及与之匹配的右括号之间的模式所匹配到的字符串;(不是模式,而是模式匹配的结果) \1:第一组括号中的pattern匹配到的字符串; \2:第二组括号中的pattern匹配到的字符串; ……后向引用:引用前面的分组括号中的模式所匹配到的字符;
egrep命令和扩展正则表达式:
egrep [OPTIONS] PATTERN [FILE...]
注:常用选项与grep一致,参考上述grep的常用选项即可。egrep和grep的区别地方:+ : 表示匹配前面的字符至少一次
? : 等同于grep中的\?,在egrep中不需要转义() : 等同于grep中的\(\),在egrep中不需要转义{} : 等同于grep中的\{\},在egrep中不需要转义
分组及引用:
(pattern):分组,括号中的模式匹配到的字符会被记录于正则表达式引擎内部的变量中;后向引用:\1, \2, ...
| : 表示匹配符号两边的任意一边,比如a|b,表示匹配a或者b
注意,| 左右带括号和不带括号的区别
以上就是grep和egrep及正则表达式的简单用法。

相关文章推荐
- Linux socket 初步
- Linux Kernel 4.0 RC5 发布!
- linux lsof详解
- linux 文件权限
- Linux 执行数学运算
- 10 篇对初学者和专家都有用的 Linux 命令教程
- Linux 与 Windows 对UNICODE 的处理方式
- Ubuntu12.04下QQ完美走起啊!走起啊!有木有啊!
- 解決Linux下Android开发真机调试设备不被识别问题
- 运维入门
- 运维提升
- Linux 自检和 SystemTap
- Ubuntu Linux使用体验
- c语言实现hashmap(转载)
- Linux 信号signal处理机制
- linux下mysql添加用户
- Scientific Linux 5.5 图形安装教程
- Linux 下无损图片压缩小工具介绍