HDU1735字数统计(贪心)
2016-03-09 17:59
274 查看
[align=left]问题描述
[/align]
一天,淘气的Tom不小心将水泼到了他哥哥Jerry刚完成的作文上。原本崭新的作文纸顿时变得皱巴巴的,更糟糕的是由于水的关系,许多字都看不清了。可怜的Tom知道他闯下大祸了,等Jerry回来一定少不了一顿修理。现在Tom只想知道Jerry的作文被“破坏”了多少。
Jerry用方格纸来写作文,每行有L个格子。(图1显示的是L = 10时的一篇作文,’X’表示该格有字,该文有三个段落)。
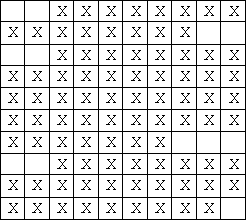
图1
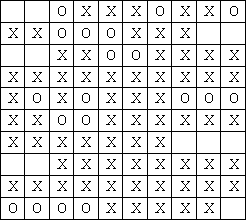
图2
图2显示的是浸水后的作文 ,‘O’表示这个位置上的文字已经被破坏。可是Tom并不知道原先哪些格子有文字,哪些没有,他唯一知道的是原文章分为M个段落,并且每个段落另起一行,空两格开头,段落内部没有空格(注意:任何一行只要开头的两个格子没有文字就可能是一个新段落的开始,例如图2中可能有4个段落)。
Tom想知道至少有多少个字被破坏了,你能告诉他吗?
[align=left]Input[/align]
测试数据有多组。每组测试数据的第一行有三个整数:N(作文的行数1 ≤ N ≤ 10000),L(作文纸每行的格子数10 ≤ L ≤ 100),M(原文的段落数1 ≤ M ≤ 20),用空格分开。
接下来是一个N × L的位矩阵(Aij)(相邻两个数由空格分开),表示被破坏后的作文。其中Aij取0时表示第i行第j列没有文字(或者是看不清了),取1时表示有文字。你可以假定:每行至少有一个1,并且所有数据都是合法的。
[align=left]Output[/align]
对于每组测试输出一行,一个整数,表示至少有多少文字被破坏。
Sample Input
10 10 3
0 0 0 1 1 1 0 1 1 0
1 1 0 0 0 1 1 1 0 0
0 0 1 1 0 0 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 0 1 0 1 1 1 0 0 0
1 1 0 0 1 1 1 1 1 1
1 1 1 1 1 1 1 0 0 0
0 0 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
0 0 0 0 1 1 1 1 1 0
[align=left]Sample Output[/align]
19
大水题一道,不用算法就能做,但写的时候思路有些混乱了..WA了几次。
思路:在输入时候,先标记一定已经被破坏的空格,包括跟在‘X’前面的‘O’,假如下一行不然不是段落开头的话,末尾的'O'也肯定被污染,(不包括前两格)之后再遍历每行并标记每一个可能成为段落开头的行,根据填补所需要的文字数进行排序。
#include<iostream>
#include<cstdio>
#include<set>
#include<map>
#include<vector>
#include<cstring>
#include<string>
#include<sstream>
#include<algorithm>
#include<cmath>
#include<cctype>
#include<cstdlib>
#define mem(x); memset(x,0,sizeof(x));
#define mem2(x); memset(x,-1,sizeof(x));
#define xh(i,k,N) for(i=(k);i<(N);i++)
#define hx(i,k,N) for(i=(k);i>(N);i--)
#define gcd(a,b); {return a==0?b:gcd(b%a,a);}
using namespace std;
const int INF =0x3f3f3f3f;
const double eps = 1e-8;
const double pi = acos(-1.0);
const int MAXN = 10000+10;
typedef int ll;
const int E=105;
typedef unsigned long long llu;
typedef long double ld;
int i,j,k,ans,flag;
int arr[MAXN][E];
int save[MAXN];
int cmp(int i,int j){
return i>j;
}
int main(void){
int N,L,M;
// freopen("in.txt","r",stdin); //从in.txt 中读入数据
//freopen("out.txt","w",stdout); // 将最后数据写入out.txt中
while(~scanf("%d%d%d",&N,&L,&M)){
mem(arr);
mem(save);
ans=0;
for(i=0;i<N;i++)
for(j=0;j<L;j++)
scanf("%d",&arr[i][j]);
for(i=0;i<N;i++){
flag=0;
for(j=L-1;j>1;j--){//情况1:需要填补的0处于1的前面,因此从后往前遍历,遇到1则标记
if(arr[i][j]==1&&!flag)
flag=1;
else if(flag&&arr[i][j]==0){
arr[i][j]=1;
ans++;
//printf("%d %d\n",i,j);
}
else if(arr[i][j]==0){
if(i<N-1&&(arr[i+1][1]+arr[i+1][0]>=1)){//情况2:下一行不然不是某段落的开头,则必然已经被污染
arr[i][j]=1;
ans++;
//printf("%d %d\n",i,j);
}
}
}
if(arr[i][0]+arr[i][1]==1){//一行的头两格分情况考虑,00和11均不变
arr[i][0]=arr[i][1]=1;
ans++;
//printf("%d %d\n",i,j);
}
}
//printf("%d\n",ans);
int nd=0;//可能为开头的行数
for(i=1;i<N;i++){
if(arr[i][0]+arr[i][1]==0){
nd++;
for(j=2;j<L;j++)
if(!arr[i-1][j])
save[nd]++;//累计填补所需要的文字
}
}
sort(save,save+nd+1,cmp);
for(i=M-1;i<nd;i++){
ans+=save[i];
ans+=2;//也要补上段落开头的两个文字
}
printf("%d\n",ans);
}
return 0;
}
[/align]
一天,淘气的Tom不小心将水泼到了他哥哥Jerry刚完成的作文上。原本崭新的作文纸顿时变得皱巴巴的,更糟糕的是由于水的关系,许多字都看不清了。可怜的Tom知道他闯下大祸了,等Jerry回来一定少不了一顿修理。现在Tom只想知道Jerry的作文被“破坏”了多少。
Jerry用方格纸来写作文,每行有L个格子。(图1显示的是L = 10时的一篇作文,’X’表示该格有字,该文有三个段落)。
图1
图2
图2显示的是浸水后的作文 ,‘O’表示这个位置上的文字已经被破坏。可是Tom并不知道原先哪些格子有文字,哪些没有,他唯一知道的是原文章分为M个段落,并且每个段落另起一行,空两格开头,段落内部没有空格(注意:任何一行只要开头的两个格子没有文字就可能是一个新段落的开始,例如图2中可能有4个段落)。
Tom想知道至少有多少个字被破坏了,你能告诉他吗?
[align=left]Input[/align]
测试数据有多组。每组测试数据的第一行有三个整数:N(作文的行数1 ≤ N ≤ 10000),L(作文纸每行的格子数10 ≤ L ≤ 100),M(原文的段落数1 ≤ M ≤ 20),用空格分开。
接下来是一个N × L的位矩阵(Aij)(相邻两个数由空格分开),表示被破坏后的作文。其中Aij取0时表示第i行第j列没有文字(或者是看不清了),取1时表示有文字。你可以假定:每行至少有一个1,并且所有数据都是合法的。
[align=left]Output[/align]
对于每组测试输出一行,一个整数,表示至少有多少文字被破坏。
Sample Input
10 10 3
0 0 0 1 1 1 0 1 1 0
1 1 0 0 0 1 1 1 0 0
0 0 1 1 0 0 1 1 1 1
1 1 1 1 1 1 1 1 1 1
1 0 1 0 1 1 1 0 0 0
1 1 0 0 1 1 1 1 1 1
1 1 1 1 1 1 1 0 0 0
0 0 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1
0 0 0 0 1 1 1 1 1 0
[align=left]Sample Output[/align]
19
大水题一道,不用算法就能做,但写的时候思路有些混乱了..WA了几次。
思路:在输入时候,先标记一定已经被破坏的空格,包括跟在‘X’前面的‘O’,假如下一行不然不是段落开头的话,末尾的'O'也肯定被污染,(不包括前两格)之后再遍历每行并标记每一个可能成为段落开头的行,根据填补所需要的文字数进行排序。
#include<iostream>
#include<cstdio>
#include<set>
#include<map>
#include<vector>
#include<cstring>
#include<string>
#include<sstream>
#include<algorithm>
#include<cmath>
#include<cctype>
#include<cstdlib>
#define mem(x); memset(x,0,sizeof(x));
#define mem2(x); memset(x,-1,sizeof(x));
#define xh(i,k,N) for(i=(k);i<(N);i++)
#define hx(i,k,N) for(i=(k);i>(N);i--)
#define gcd(a,b); {return a==0?b:gcd(b%a,a);}
using namespace std;
const int INF =0x3f3f3f3f;
const double eps = 1e-8;
const double pi = acos(-1.0);
const int MAXN = 10000+10;
typedef int ll;
const int E=105;
typedef unsigned long long llu;
typedef long double ld;
int i,j,k,ans,flag;
int arr[MAXN][E];
int save[MAXN];
int cmp(int i,int j){
return i>j;
}
int main(void){
int N,L,M;
// freopen("in.txt","r",stdin); //从in.txt 中读入数据
//freopen("out.txt","w",stdout); // 将最后数据写入out.txt中
while(~scanf("%d%d%d",&N,&L,&M)){
mem(arr);
mem(save);
ans=0;
for(i=0;i<N;i++)
for(j=0;j<L;j++)
scanf("%d",&arr[i][j]);
for(i=0;i<N;i++){
flag=0;
for(j=L-1;j>1;j--){//情况1:需要填补的0处于1的前面,因此从后往前遍历,遇到1则标记
if(arr[i][j]==1&&!flag)
flag=1;
else if(flag&&arr[i][j]==0){
arr[i][j]=1;
ans++;
//printf("%d %d\n",i,j);
}
else if(arr[i][j]==0){
if(i<N-1&&(arr[i+1][1]+arr[i+1][0]>=1)){//情况2:下一行不然不是某段落的开头,则必然已经被污染
arr[i][j]=1;
ans++;
//printf("%d %d\n",i,j);
}
}
}
if(arr[i][0]+arr[i][1]==1){//一行的头两格分情况考虑,00和11均不变
arr[i][0]=arr[i][1]=1;
ans++;
//printf("%d %d\n",i,j);
}
}
//printf("%d\n",ans);
int nd=0;//可能为开头的行数
for(i=1;i<N;i++){
if(arr[i][0]+arr[i][1]==0){
nd++;
for(j=2;j<L;j++)
if(!arr[i-1][j])
save[nd]++;//累计填补所需要的文字
}
}
sort(save,save+nd+1,cmp);
for(i=M-1;i<nd;i++){
ans+=save[i];
ans+=2;//也要补上段落开头的两个文字
}
printf("%d\n",ans);
}
return 0;
}

相关文章推荐
- IOS_UITableViewCell(UITabel)自动适应Row高
- Android Mediaplayer的使用
- winform子窗体控制父窗体控件
- 选项卡制作问题--折磨了我一整天,记录下来
- Epic Games王祢:UE4在移动平台的开发优势
- Android Studio 工作中用快捷键
- web中父页面与子页面传值的问题
- Effective STL 第一章:容器(四)
- Symmetric Tree
- JNDI配置
- 148.View the Exhibit and examine the structure of the PRODUCTS tables.
- [转]backbone.js 初探
- nginx重启
- 从相册或者相机获得uri转为bitmap
- jedis调用redis之事物
- Tomcat配置虚拟主机的方法
- Chapter 4. Button, Checkbutton, and Radiobutton Widgets 按钮,复选按钮,单选按钮
- A + B + C Problem
- cell的自适应
- rtc关机闹钟5 AlarmManager研究