Spark On Yarn集群环境搭建
2016-03-08 19:43
671 查看
一、Scala安装
下载scala安装包,地址:http://www.scala-lang.org/download/
配置环境变量
下载完成后,解压到指定的目录下,在/etc/profile文件中配置环境变量:
验证scala的安装
二、安装spark
下载spark安装包,地址:http://spark.apache.org/downloads.html
下载完成后,拷贝到指定的目录下:/usr/local/jiang/,然后解压:
解压后在配置中添加java环境变量、scala环境变量、hadoop环境变量等conf/spark-env.sh
配置从机conf/slaves
当然这里配置的是主机名,所以在/etc/hosts中一定要添加主机名和ip的映射,不然没法识别的:
将配置好的spark-1.6.0-bin-hadoop2.6文件远程拷贝到相对应的从机中:
启动集群
启动完成后,查看主从机的进程:
主机:
从机:
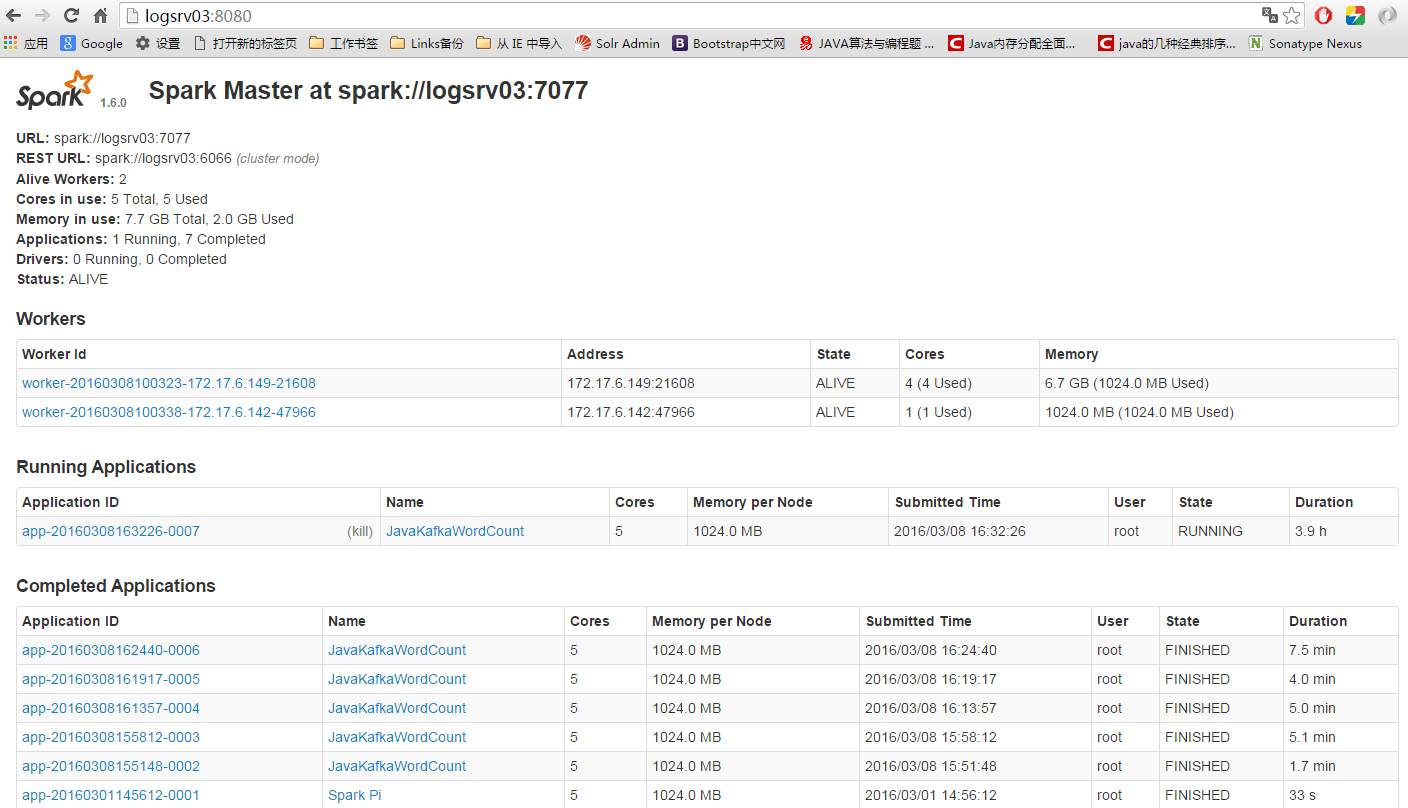
三、安装完成后,可以查看spark的UI:
运行wordcout例子:
命令:
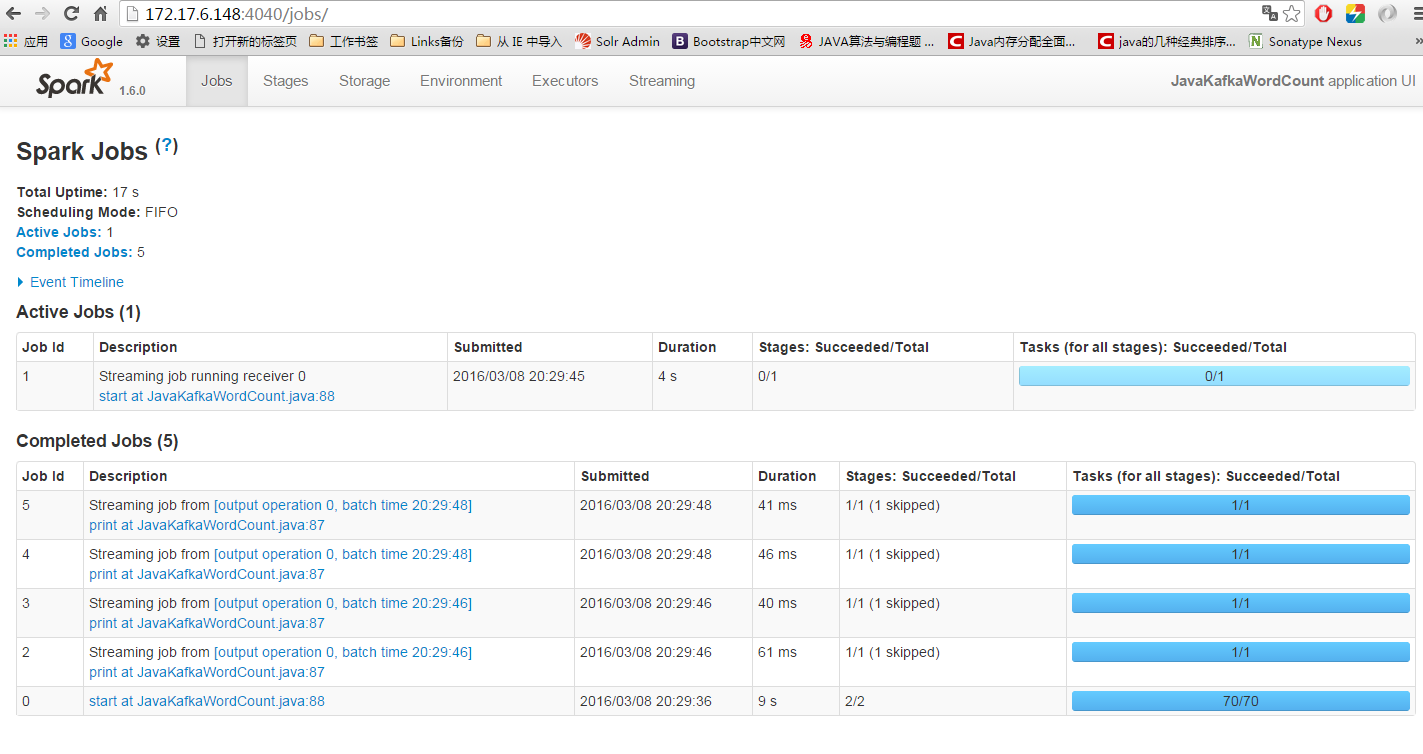
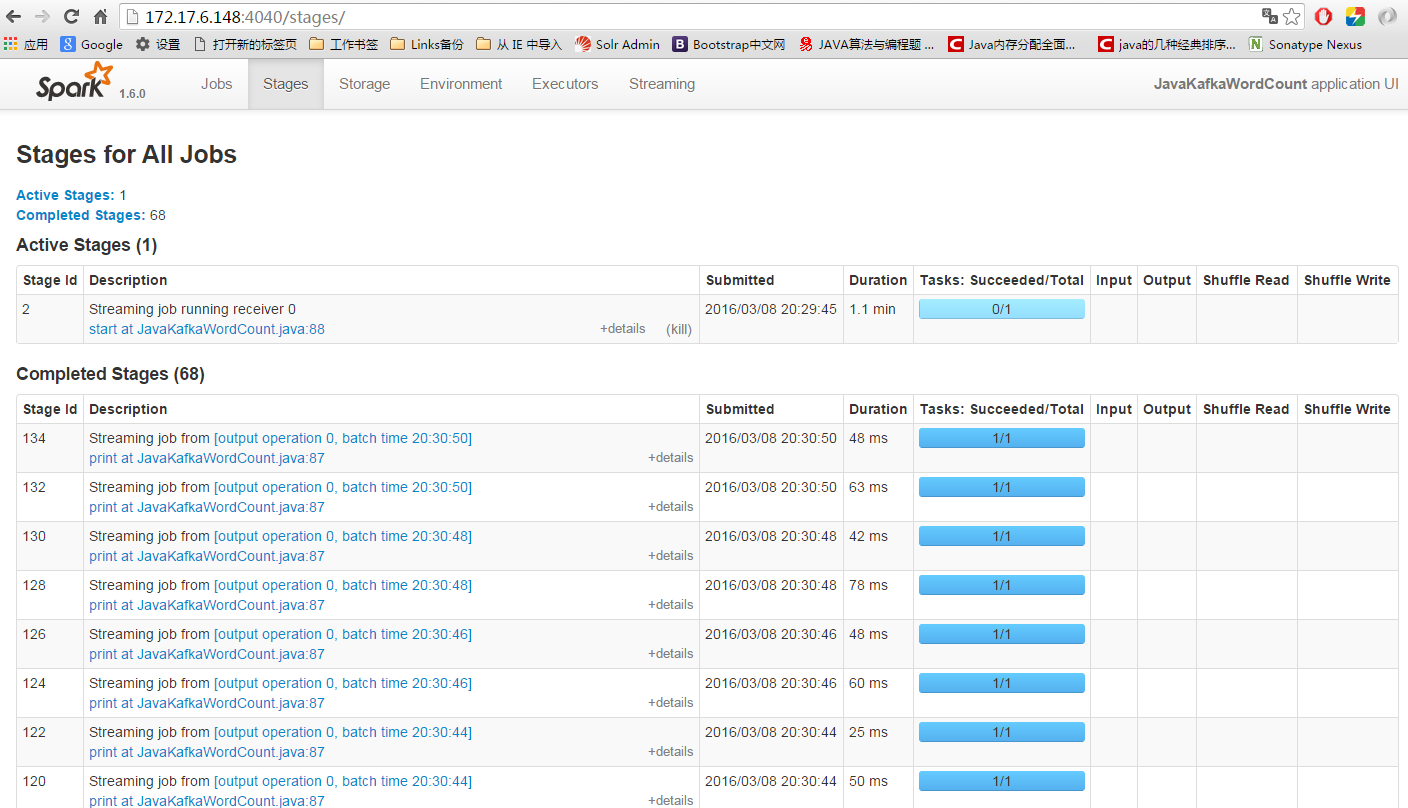
运行后spark的UI:
下载scala安装包,地址:http://www.scala-lang.org/download/
配置环境变量
下载完成后,解压到指定的目录下,在/etc/profile文件中配置环境变量:
export SCALA_HOME=/usr/local/jiang/scala-2.10.6 export PATH=$PATH:$SCALA_HOME/bin
验证scala的安装
[root@logsrv03 etc]# scala -version Scala code runner version 2.10.6 -- Copyright 2002-2013, LAMP/EPFL
二、安装spark
下载spark安装包,地址:http://spark.apache.org/downloads.html
下载完成后,拷贝到指定的目录下:/usr/local/jiang/,然后解压:
tar -zxvf spark-1.6.0-bin-hadoop2.6.tgz
解压后在配置中添加java环境变量、scala环境变量、hadoop环境变量等conf/spark-env.sh
# set scala environment export SCALA_HOME=/usr/local/jiang/scala-2.10.6 # set java environment export JAVA_HOME=/usr/local/jdk1.7.0_71 # set hadoop export HADOOP_HOME=/usr/local/jiang/hadoop-2.7.1 export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop # set spark SPARK_MASTER_IP=logsrv03 SPARK_LOCAL_DIRS=/usr/local/jiang/spark-1.6.0 SPARK_DRIVER_MEMORY=1G
配置从机conf/slaves
logsrv02 logsrv04
当然这里配置的是主机名,所以在/etc/hosts中一定要添加主机名和ip的映射,不然没法识别的:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 172.17.6.141 logsrv01 172.17.6.142 logsrv02 172.17.6.149 logsrv04 172.17.6.148 logsrv03 172.17.6.150 logsrv05 172.17.6.159 logsrv08 172.17.6.160 logsrv09 172.17.6.161 logsrv10 172.17.6.164 logtest01 172.17.6.165 logtest02 172.17.6.166 logtest03 172.30.2.193 devops172302193 172.30.2.194 devops172302194 172.30.2.195 devops172302195
将配置好的spark-1.6.0-bin-hadoop2.6文件远程拷贝到相对应的从机中:
[root@logsrv03 jiang]# scp -r spark-1.6.0-bin-hadoop2.6 root@logsrv02:/usr/local/jiang/ [root@logsrv03 jiang]# scp -r spark-1.6.0-bin-hadoop2.6 root@logsrv04:/usr/local/jiang/
启动集群
[root@logsrv03 spark-1.6.0-bin-hadoop2.6]# sbin/start-all.sh
启动完成后,查看主从机的进程:
主机:
[root@logsrv03 spark-1.6.0-bin-hadoop2.6]# jps 25325 NameNode 23973 Master 17643 ResourceManager 25523 SecondaryNameNode 28839 Jps
从机:
[root@logsrv02 spark-1.6.0-bin-hadoop2.6]# jps 744 Worker 4406 Jps 2057 DataNode 2170 NodeManager
三、安装完成后,可以查看spark的UI:
运行wordcout例子:
命令:
./bin/spark-submit \ --name JavaKafkaWordCount \ --master spark://logsrv03:7077 \ --executor-memory 1G \ --class examples.streaming.JavaKafkaWordCount \ log_spark-0.0.1-SNAPSHOT.jar 172.17.6.142:2181,172.17.6.148:2181,172.17.6.149:2181 11 log-topic 5
运行后spark的UI:

相关文章推荐
- Spark RDD API详解(一) Map和Reduce
- 使用spark和spark mllib进行股票预测
- Spark随谈——开发指南(译)
- RedHat 5.8 安装Oracle 11gR2_Grid集群
- Spark,一种快速数据分析替代方案
- mysql集群之MMM简单搭建
- MySQL的集群配置的基本命令使用及一次操作过程实录
- MySQL slave_net_timeout参数解决的一个集群问题案例
- Redis 集群搭建和简单使用教程
- Windows Server 2003 下配置 MySQL 集群(Cluster)教程
- tomcat6_apache2.2_ajp 负载均衡加集群实战分享
- 用apache和tomcat搭建集群(负载均衡)
- Red Hat Linux,Apache2.0+Weblogic9.2负载均衡集群安装配置
- Hadoop2.X/YARN环境搭建--CentOS7.0 JDK配置
- Hadoop单机版和全分布式(集群)安装
- Hadoop2.X/YARN环境搭建--CentOS7.0系统配置
- java结合HADOOP集群文件上传下载
- eclipse 开发 spark Streaming wordCount
- Spring3.2.0和Quartz1.8.6集群配置