基于itemBase的协同过滤
2016-03-07 00:00
281 查看
一.什么是协同过滤
举个简单的例子,我们网购的时候当我们购买了一件物品A,网站基本上都会做这样一个提示,购买该物品的人还购买了。。然后是一个推荐清单,这就是典型的协同过滤,这具体是怎样实现的呢?下面是我自己实现一个协同过滤的案例。
二.算法原理
基于item的协同过滤,通过用户对不同item的评分来评测item之间的相似性,基于item之间的相似性做出推荐。简单来讲就是:给用户推荐和他之前喜欢的物品相似的物品。
对购买了物品A的用户C做推荐时:对于物品A和物品B在用户B同现共1次,对于物品A和物品C在用户A、B同现共2次,所以物品A和C的相似度2大于物品A和B的相似度1,所以将物品C推荐给用户C。
那么,问题来了如果用户C表现出对物品B的喜好程度程度大于对物品C的喜好程度,那么我们再用户C做推荐时是推荐物品B还是推荐物品C呢?
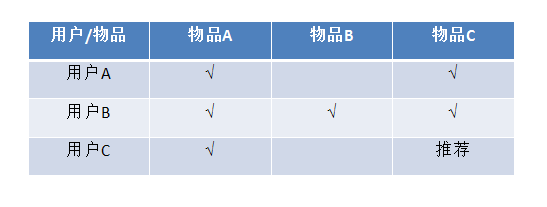
三.矩阵模型

为了解决上述问题,引入了用户评分矩矩阵。(上图)左侧是物品的同现矩阵,中间是用户对物品的评分矩阵,这样一来物品之间的相似度和用户对物品的喜好程度两个维度就都有了,两个矩阵相乘得到物品的推荐矩阵。物品之间的相似度越高左侧对应的值就越大;用户对物品的的喜好度越大则用户评分矩阵中对应的值也就越大;最终二者乘积就越大,这样在推荐矩阵中分值越高的推荐度也就越大。
四.实现步骤
建立物品的同现矩阵
建立用户对物品的评分矩阵
计算得出推荐结果矩阵
推荐结果矩阵=物品的同现矩阵* 用户对物品的评分矩阵
过滤与排序
五.mapreduce的job流程及进出数据格式


六.每个job的具体工作
第一个job:集中每一个用户的所有的item,item之间做笛卡尔积同现,值记为1


第二个job:计算物品同现次数,得到物品的同现矩阵


第三个job:用户的评分矩阵(根据用户点击、收藏、购买等行为得到用户对物品的打分情况,具体分值根据具体情况自定义)


第四个job:矩阵相乘得到推荐矩阵


第五个job:过滤(过滤掉已经购买过的item)与排序(降序)

举个简单的例子,我们网购的时候当我们购买了一件物品A,网站基本上都会做这样一个提示,购买该物品的人还购买了。。然后是一个推荐清单,这就是典型的协同过滤,这具体是怎样实现的呢?下面是我自己实现一个协同过滤的案例。
二.算法原理
基于item的协同过滤,通过用户对不同item的评分来评测item之间的相似性,基于item之间的相似性做出推荐。简单来讲就是:给用户推荐和他之前喜欢的物品相似的物品。
对购买了物品A的用户C做推荐时:对于物品A和物品B在用户B同现共1次,对于物品A和物品C在用户A、B同现共2次,所以物品A和C的相似度2大于物品A和B的相似度1,所以将物品C推荐给用户C。
那么,问题来了如果用户C表现出对物品B的喜好程度程度大于对物品C的喜好程度,那么我们再用户C做推荐时是推荐物品B还是推荐物品C呢?
三.矩阵模型
为了解决上述问题,引入了用户评分矩矩阵。(上图)左侧是物品的同现矩阵,中间是用户对物品的评分矩阵,这样一来物品之间的相似度和用户对物品的喜好程度两个维度就都有了,两个矩阵相乘得到物品的推荐矩阵。物品之间的相似度越高左侧对应的值就越大;用户对物品的的喜好度越大则用户评分矩阵中对应的值也就越大;最终二者乘积就越大,这样在推荐矩阵中分值越高的推荐度也就越大。
四.实现步骤
建立物品的同现矩阵
建立用户对物品的评分矩阵
计算得出推荐结果矩阵
推荐结果矩阵=物品的同现矩阵* 用户对物品的评分矩阵
过滤与排序
五.mapreduce的job流程及进出数据格式
六.每个job的具体工作
第一个job:集中每一个用户的所有的item,item之间做笛卡尔积同现,值记为1
第二个job:计算物品同现次数,得到物品的同现矩阵
第三个job:用户的评分矩阵(根据用户点击、收藏、购买等行为得到用户对物品的打分情况,具体分值根据具体情况自定义)
第四个job:矩阵相乘得到推荐矩阵
第五个job:过滤(过滤掉已经购买过的item)与排序(降序)

相关文章推荐
- Hadoop_2.1.0 MapReduce序列图
- MongoDB中的MapReduce简介
- MongoDB学习笔记之MapReduce使用示例
- MongoDB中MapReduce编程模型使用实例
- MapReduce中ArrayWritable 使用指南
- Java函数式编程(七):MapReduce
- java连接hdfs ha和调用mapreduce jar示例
- 用PHP和Shell写Hadoop的MapReduce程序
- JavaScript mapreduce工作原理简析
- mongodb mapredReduce 多个条件分组(group by)
- HBase基本原理
- HDFS DatanodeProtocol——sendHeartbeat
- HDFS DatanodeProtocol——register
- Hadoop集群提交作业问题总结
- Hadoop源码分析 HDFS ClientProtocol——addBlock
- Hadoop源码分析HDFS ClientProtocol——create
- Hadoop源码分析FSNamesystem几个重要的成员变量
- Hadoop源码分析HDFS ClientProtocol——getBlockLocations
- Hadoop源码分析HDFS Client向HDFS写入数据的过程解析
- ZooKeeper基本理解