python基础(类,文件,struct,拷贝,集合)
2016-03-06 18:25
639 查看
[b]一.类[/b]
[b]二.文件[/b]

[b]三.struct,pack,unpack[/b]
[b]

[/b]
[b]四.拷贝[/b]
[b]五.集合[/b]
[b]
[/b]
#coding=utf-8
class Animal(object):
def __init__(self, name):
self.name = name
zebra = Animal("Jeffrey")
print zebra.name
#override
class Employee(object):
def __init__(self, emplotee_name):
self.employee_name = emplotee_name
def calculate_wage(self, hours):
self.hours = hours
return hours * 20.0
class PartTimeEmployee(Employee):
def calculate_wage(self, hours):
self.hours = hours
return hours * 12.0
def full_time_wage(self, hours):
return super(PartTimeEmployee, self).calculate_wage(hours)
milton = PartTimeEmployee("Li")
print milton.full_time_wage(10) #200
print milton.calculate_wage(10) #120
class Car(object):
condition = "new"
my_car = Car()
print my_car.condition #new
class A(object):
def __init__(self, n):
self.__n = n
aa = A(10)
aa #__n是私有变量,对象无法访问[b]二.文件[/b]
#coding=utf-8
"""
w wb (+)写
r rb (+)读
a ab (+)追加
"""
my_List = [i**2 for i in range(1, 11)]
f = open("output.txt", 'w')
for item in my_List:
f.write(str(item) + '\n')
f.close()
print f.readline() #一行
print f.read() #全部
with open("text.txt", 'w') as textfile:
textfile.write("success!")
if textfile.closed == False:
textfile.close()
print textfile.closed#coding=utf-8
import os
import shutil
import glob
"""
文件夹操作
"""
print os.getcwd()
os.mkdir("D:\\cwd")
print os.path.exists("D:\\cwd")
os.chdir("D:\\cwd")
print os.getcwd()
f = file("a.txt", "w")
f.close()
shutil.copy("E:\\b.txt", "D:\\cwd\\b.txt")
shutil.copy("E:\\b.txt", "D:\\cwd\\c.txt")
shutil.copy("E:\\b.txt", "D:\\cwd\\d.txt")
os.remove("a.txt")
os.rename("b.txt", "e.txt")
"""
文件夹遍历
"""
for root, dirs, files in os.walk(os.getcwd()):
print files
break
for file in os.listdir(os.getcwd()):
if os.path.isfile(os.path.join(os.getcwd(), file)):
print file
print glob.glob("*.txt")
os.chdir("D:\\")
shutil.rmtree("D:\\cwd")
#os.removedirs("D:\\cwd") error,删除多层空文件夹
#os.rmdir("D:\\cwd") error,只适用于空文件夹[b]三.struct,pack,unpack[/b]
[b]
[/b]
#coding=utf-8
import struct
a = 1
b = 2
c = 'sss'
d = 1.1
e = [a, b, c, d]
ss = struct.pack('ii3sf', a, b, c, d)
a, b, c, d = struct.unpack('ii3sf', ss)
print a, b, c, d #1 2 sss 1.10000002384
ss = struct.pack('ii3sf', *e)
a, b, c, d = struct.unpack('ii3sf', ss)
print a, b, c, d #1 2 sss 1.10000002384
x = [1, 2, 3]
y = [4, 5, 6]
xyz = zip(x, y)
print zip(x, y) #[(1, 4), (2, 5), (3, 6)]
print zip(x) #[(1,), (2,), (3,)]
print zip(*xyz) #[(1, 2, 3), (4, 5, 6)]
"""
[(1, 2, 3), (4, 5, 6), (7, 8, 9)]
一般认为这是一个unzip的过程,它的运行机制是这样的:
在运行zip(*xyz)之前,xyz的值是:[(1, 4), (2, 5), (3, 6)]
那么,zip(*xyz) 等价于 zip((1, 4), (2, 5), (3, 6))
所以,运行结果是:[(1, 2, 3), (4, 5, 6)]
"""[b]四.拷贝[/b]
#coding=utf-8
import copy
a = [1, 2, 3]
b = a
b[0] = 4
print a #[4, 2, 3]
a[0] = 1
print b #[1, 2, 3]
b = copy.deepcopy(a)
b[0] = 4
print a #[1, 2, 3]
a = {'a':1, 'b':2, 'c':3}
b = a
b['a'] = 4
print a #{'a': 4, 'c': 3, 'b': 2}
b.clear()
print a #{}
a = {'a':1, 'b':2, 'c':3}
b = a.copy()
b['a'] = 4
print a #{'a': 1, 'c': 3, 'b': 2}
b.clear()
print a #{'a': 1, 'c': 3, 'b': 2}[b]五.集合[/b]
[b]
[/b]
#coding=utf-8
#in, not in, <, >
aSet = set([1, 2, 3, 4])
bSet = set([3, 4, 5])
print aSet #set([1, 2, 3, 4])
print aSet.intersection([3, 4, 5]) #set([3, 4])
print aSet & bSet #set([3, 4])
print aSet.union([5, 6]) #set([1, 2, 3, 4, 5, 6])
print aSet.difference([3, 4, 5]) #set([1, 2])
print aSet.issubset(bSet) #False
aSet.add(5)
print aSet #set([1, 2, 3, 4, 5])
aSet.remove(5)
print aSet #set([1, 2, 3, 4])
aSet.update(bSet)
print aSet #set([1, 2, 3, 4, 5])
"""
python的set和其他语言类似, 是一个无序不重复元素集, 基本功能包括关系测试和消除重复元素. 集合对象还支持union(联合), intersection(交), difference(差)和sysmmetric difference(对称差集)等数学运算.
sets 支持 x in set, len(set),和 for x in set。作为一个无序的集合,sets不记录元素位置或者插入点。因此,sets不支持 indexing, slicing, 或其它类序列(sequence-like)的操作。
下面来点简单的小例子说明把。
>>> x = set('spam')
>>> y = set(['h','a','m'])
>>> x, y
(set(['a', 'p', 's', 'm']), set(['a', 'h', 'm']))
再来些小应用。
>>> x & y # 交集
set(['a', 'm'])
>>> x | y # 并集
set(['a', 'p', 's', 'h', 'm'])
>>> x - y # 差集
set(['p', 's'])
记得以前个网友提问怎么去除海量列表里重复元素,用hash来解决也行,只不过感觉在性能上不是很高,用set解决还是很不错的,示例如下:
>>> a = [11,22,33,44,11,22]
>>> b = set(a)
>>> b
set([33, 11, 44, 22])
>>> c = [i for i in b]
>>> c
[33, 11, 44, 22]
很酷把,几行就可以搞定。
1.8 集合
集合用于包含一组无序的对象。要创建集合,可使用set()函数并像下面这样提供一系列的项:
s = set([3,5,9,10]) #创建一个数值集合
t = set("Hello") #创建一个唯一字符的集合
与列表和元组不同,集合是无序的,也无法通过数字进行索引。此外,集合中的元素不能重复。例如,如果检查前面代码中t集合的值,结果会是:
>>> t
set(['H', 'e', 'l', 'o'])
注意只出现了一个'l'。
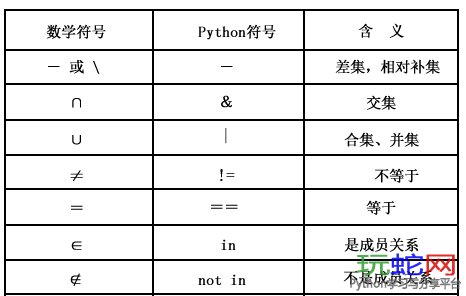
集合支持一系列标准操作,包括并集、交集、差集和对称差集,例如:
a = t | s # t 和 s的并集
b = t & s # t 和 s的交集
c = t – s # 求差集(项在t中,但不在s中)
d = t ^ s # 对称差集(项在t或s中,但不会同时出现在二者中)
基本操作:
t.add('x') # 添加一项
s.update([10,37,42]) # 在s中添加多项
使用remove()可以删除一项:
t.remove('H')
len(s)
set 的长度
x in s
测试 x 是否是 s 的成员
x not in s
测试 x 是否不是 s 的成员
s.issubset(t)
s <= t
测试是否 s 中的每一个元素都在 t 中
s.issuperset(t)
s >= t
测试是否 t 中的每一个元素都在 s 中
s.union(t)
s | t
返回一个新的 set 包含 s 和 t 中的每一个元素
s.intersection(t)
s & t
返回一个新的 set 包含 s 和 t 中的公共元素
s.difference(t)
s - t
返回一个新的 set 包含 s 中有但是 t 中没有的元素
s.symmetric_difference(t)
s ^ t
返回一个新的 set 包含 s 和 t 中不重复的元素
s.copy()
返回 set “s”的一个浅复制
请注意:union(), intersection(), difference() 和 symmetric_difference() 的非运算符(non-operator,就是形如 s.union()这样的)版本将会接受任何 iterable 作为参数。相反,它们的运算符版本(operator based counterparts)要求参数必须是 sets。这样可以避免潜在的错误,如:为了更可读而使用 set('abc') & 'cbs' 来替代 set('abc').intersection('cbs')。从 2.3.1 版本中做的更改:以前所有参数都必须是 sets。
另外,Set 和 ImmutableSet 两者都支持 set 与 set 之间的比较。两个 sets 在也只有在这种情况下是相等的:每一个 set 中的元素都是另一个中的元素(二者互为subset)。一个 set 比另一个 set 小,只有在第一个 set 是第二个 set 的 subset 时(是一个 subset,但是并不相等)。一个 set 比另一个 set 打,只有在第一个 set 是第二个 set 的 superset 时(是一个 superset,但是并不相等)。
子 set 和相等比较并不产生完整的排序功能。例如:任意两个 sets 都不相等也不互为子 set,因此以下的运算都会返回 False:a<b, a==b, 或者a>b。因此,sets 不提供 __cmp__ 方法。
因为 sets 只定义了部分排序功能(subset 关系),list.sort() 方法的输出对于 sets 的列表没有定义。
运算符
运算结果
hash(s)
返回 s 的 hash 值
下面这个表列出了对于 Set 可用二对于 ImmutableSet 不可用的运算:
运算符(voperator)
等价于
运算结果
s.update(t)
s |= t
返回增加了 set “t”中元素后的 set “s”
s.intersection_update(t)
s &= t
返回只保留含有 set “t”中元素的 set “s”
s.difference_update(t)
s -= t
返回删除了 set “t”中含有的元素后的 set “s”
s.symmetric_difference_update(t)
s ^= t
返回含有 set “t”或者 set “s”中有而不是两者都有的元素的 set “s”
s.add(x)
向 set “s”中增加元素 x
s.remove(x)
从 set “s”中删除元素 x, 如果不存在则引发 KeyError
s.discard(x)
如果在 set “s”中存在元素 x, 则删除
s.pop()
删除并且返回 set “s”中的一个不确定的元素, 如果为空则引发 KeyError
s.clear()
删除 set “s”中的所有元素
请注意:非运算符版本的 update(), intersection_update(), difference_update()和symmetric_difference_update()将会接受任意 iterable 作为参数。从 2.3.1 版本做的更改:以前所有参数都必须是 sets。
还请注意:这个模块还包含一个 union_update() 方法,它是 update() 方法的一个别名。包含这个方法是为了向后兼容。程序员们应该多使用 update() 方法,因为这个方法也被内置的 set() 和 frozenset() 类型支持。
"""aSet = frozenset([1,2,3,4])
bSet = frozenset([3,4,5,6])
a = {aSet:1, bSet:2}
print a #{frozenset([1, 2, 3, 4]): 1, frozenset([3, 4, 5, 6]): 2}

相关文章推荐
- python对绑定事件的鼠标、按键的判断
- python基础0306
- python基本数据类型
- python 列表特点及常用操作
- Python 元组和集合的特点及常用操作
- Python 字典的特点和常用操作
- python 按图形打印二叉树
- win7(64) python2.7(64) scrapy框架的搭建
- Python 2.7.11 字典操作
- Python中NumPy基础使用
- python
- python 常用
- python datetime时间差
- python 输出重定向
- python 文件夹操作
- python 文件编码
- python unitest基本
- python paramiko基本
- python selenium基本
- 使用pycharm进行win下多个版本python编程&&GTK,py2exe安装