【one day one linux】grep工具
2016-03-05 23:28
471 查看
grep 筛选功能
学习这些命令采用20/80原则,这样,可以达到使用%20的命令选项,处理80%的情况。
那么接下来看看我自己选择的一些grep的命令选项:
grep的基本使用
这里我在.bashrc 加入了一个命名别名:alias grep=grep --color=auto
很多时候grep用于管道之后,pattern部分可以使用引号引起来,也可以不用


以上是grep的基本用法,后面还有grep与正则表达式的结合
基础正则表达式
1.特殊字符
2.编码语系对正则表达式的影响
先看两种语系下字符集的差别
LANG=C 时:0 1 2 3 4 ... A B C D ... Z a b c d ... z
LANG=zh_CN时:0 1 2 3 4 ... a A b B c C d D ... z Z
从上面的编码的顺序很容易看出两种编码的差别。所以同一个正则表达式在两种编码下就会存在差异:
[A-Z] 在LANG=C时,是正常的意思,在LANG=zh_CN时,代表A b B c C d D ... z Z,就会出现并不是我们想要的字符。
所以我们可以使用下面一些特殊字符来表示意思。
这里只列出几个常用的就行:
[:alnum:] 代表英文大小写字符,及数字
[:alpha:] 代表任何英文字符 a-z A-Z
[:upper:] 代表大写字母 A-Z
[:lower:] 代表小写字母 a-z
[:digit:] 代表数字 0-9
3.接下来是grep的一些高级参数
grep可以使用正则表达式来筛选自己需要的字段。
(1)使用"[]"来查找集合字符
如果我想要查找test和tast这两个单词,可以使用正则表达式如下:
如上所示,根据这两个单词的共同点,把不同的地方用"[]"字符集合表示。
集合可以使用反向选择符等一些符号来丰富命令。
比如:
(2)行首符号"^"和行尾符号"$"
这里注意区分行首符号与反向选择符号的区别,区别在于是否在中括号[]中,在中括号的是反向选择符号,没有在的是行首符号
比如我们选择行首有"the"的
(3)任意一个字符"." 与重复字符"*"
"." 小数点:代表一定有一个任意字符的意思。
"*"星号:代表重复前一个字符0到无穷大次。 (请特别注意这里,它是可以重复0次的)
如下:
那么当我们需要重复某个字符至少多次可以像这样写,"ooo*" 这代表至少重复两次以上。
(4)限定字符范围 {}
因为{}在shell中是有特殊用途的,所有在使用的时候需要加上转义符号"\",使其变为一般的{}
参考boke:
grep命令
学习这些命令采用20/80原则,这样,可以达到使用%20的命令选项,处理80%的情况。
#grep 的使用格式 grep [option] pattern file
那么接下来看看我自己选择的一些grep的命令选项:
-c 计算符合范本的列数 -i 忽略pattern中的大小写 -w 忽略大小写,并搜索整个词汇 -r 递归的搜索所在目录的所有子目录 -v 查找和pattern不匹配的行 -n 打印出匹配行的行号 --color=auto 将pattern在匹配行中高亮 -A 后面加上数字,为after的意思,表示后续的n也列出来 -B 后面加数字,为before的意思,便是前面n行也列出来
grep的基本使用
这里我在.bashrc 加入了一个命名别名:alias grep=grep --color=auto
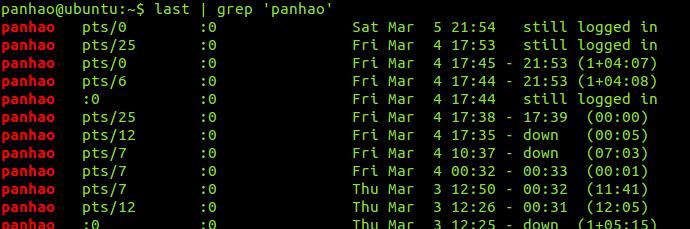
#输出last中有某用户名的一行 >># last | grep 'panhao'
很多时候grep用于管道之后,pattern部分可以使用引号引起来,也可以不用
#-v参数使用 >> # last | grep -v panhao
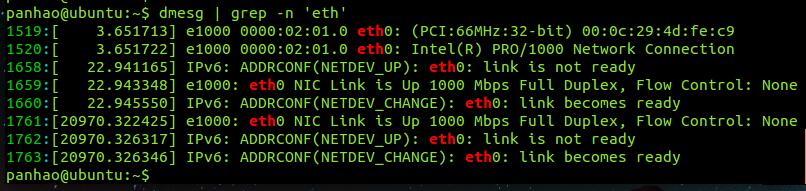
#用dmesg列出内核信息,再以grep找出内含eth的那行 dmesg | grep 'eth'
#显示行号的grep dmesg | grep -n 'eth'
#参数 -A -B的使用 dmesg | grep -n A1 B2 'eth'
以上是grep的基本用法,后面还有grep与正则表达式的结合
基础正则表达式
1.特殊字符
| ^string | 意义:待查找的字符串在行首(以string开头的) |
| string$ | 意义:待查找的字符串在行尾(以string结尾的) |
| . | 意义:代表一定有一个任意字符的字符在该位置 |
| \ | 意义:转义字符,将命令中的特殊字符去除 |
| * | 意义:重复零个或者多个前一个字符 |
| [list] | 意义:选取待查找的字符(比如:[afl]代表"a"或者"f"或者"l") |
| [n1-n2] | 意义:代表n1到n2的字符集合(注意:这个表达式和bash使用的编码有关,后面会提到) |
| [^list] | 意义:反向查找,没有list字符集合的字符串 |
| \{n,m\} | 意义:连续n到m个前一个字符。若为\{n\}则是连续n个前一个字符,若为\{n,\}则为连续n个以上的字符。 |
先看两种语系下字符集的差别
LANG=C 时:0 1 2 3 4 ... A B C D ... Z a b c d ... z
LANG=zh_CN时:0 1 2 3 4 ... a A b B c C d D ... z Z
从上面的编码的顺序很容易看出两种编码的差别。所以同一个正则表达式在两种编码下就会存在差异:
[A-Z] 在LANG=C时,是正常的意思,在LANG=zh_CN时,代表A b B c C d D ... z Z,就会出现并不是我们想要的字符。
所以我们可以使用下面一些特殊字符来表示意思。
这里只列出几个常用的就行:
[:alnum:] 代表英文大小写字符,及数字
[:alpha:] 代表任何英文字符 a-z A-Z
[:upper:] 代表大写字母 A-Z
[:lower:] 代表小写字母 a-z
[:digit:] 代表数字 0-9
3.接下来是grep的一些高级参数
grep可以使用正则表达式来筛选自己需要的字段。
(1)使用"[]"来查找集合字符
如果我想要查找test和tast这两个单词,可以使用正则表达式如下:
# grep -n 't[ae]st' file
如上所示,根据这两个单词的共同点,把不同的地方用"[]"字符集合表示。
集合可以使用反向选择符等一些符号来丰富命令。
比如:
#使用方向选择符,和a-z表示所有的小写字母 # grep '[^a-z]oo' file #也可以变为之前跟编码无关的符号 [:lower:],如下 # grep '[^[:lower:]]oo' file
(2)行首符号"^"和行尾符号"$"
这里注意区分行首符号与反向选择符号的区别,区别在于是否在中括号[]中,在中括号的是反向选择符号,没有在的是行首符号
比如我们选择行首有"the"的
# grep -n '^the' file # 下面写一个既有反向选择又有行首的grep # grep -n '^[^[a-zA-Z]]' file
#行尾的例子:找出行尾为"."结束的,因为"."在这里有特殊的含义,所以需要使用转义字符 # grep -n '\.$' file #寻找空白行 # grep -n '^$' file #只有行首和行尾的就是空白行
(3)任意一个字符"." 与重复字符"*"
"." 小数点:代表一定有一个任意字符的意思。
"*"星号:代表重复前一个字符0到无穷大次。 (请特别注意这里,它是可以重复0次的)
如下:
# grep -n 'g..d' file #可以匹配到 good glad 等一些字符串 # grep -n 'o*' file #执行这一句你会发现,打印出了所有的行。因为可以是0个“o”
那么当我们需要重复某个字符至少多次可以像这样写,"ooo*" 这代表至少重复两次以上。
(4)限定字符范围 {}
因为{}在shell中是有特殊用途的,所有在使用的时候需要加上转义符号"\",使其变为一般的{}
# grep -n 'o\{2\}' file #两个o的字符
# grep -n 'go\{2,5\}gle' #代表后面接2-5个o字符
# grep -n 'gp\{2,\}g' file #代表两个以上参考boke:
每天一个linux命令(39):grep 命令
如何使用Unix/Linux grep命令——磨刀不误砍柴工系列grep命令

相关文章推荐
- OS系统的虚拟机下Linux/ubuntu关机卡死解决方案
- Linux文件系统相关
- linux之sed
- linux rpm命令
- CentOS 下编译安装PHP
- CentOS 下编译安装MySQL
- linux沙箱
- 从mykernel分析linux任务调度
- Linux(一)——文本模式指令
- Linux基础知识(四)
- linux下mysql自动备份和自动删除文件功能实现
- Linux第二周学习总结——操作系统是如何工作的
- NAT: How To Mangle The Packets
- LINUX之----启程(centos 6.5)
- linux下查看和添加PATH环境变量
- 关于linux异步通知signal 和QT的信号槽
- Linux Mint 17.2 文本编辑器中文乱码问题
- Linux内核分析 实验二:完成一个简单的时间片轮转多道程序内核代码
- 【解决】在Linux系统下,使用cat查看含有中文的文本文件正常,但是使用vim打开却是乱码的解决方法
- Linux Mint 17.2 输入法安装