coursera 公开课 文本挖掘和分析(text mining and analytics) week 1 笔记
2016-03-03 23:40
309 查看
一、课程简介:
text mining and analytics 是一门在coursera上的公开课,由美国伊利诺伊大学香槟分校(UIUC)计算机系教授 chengxiang zhai 讲授,公开课链接:https://class.coursera.org/textanalytics-001/wiki/view?page=Programming_Assignments_Overview。
二、课程大纲:
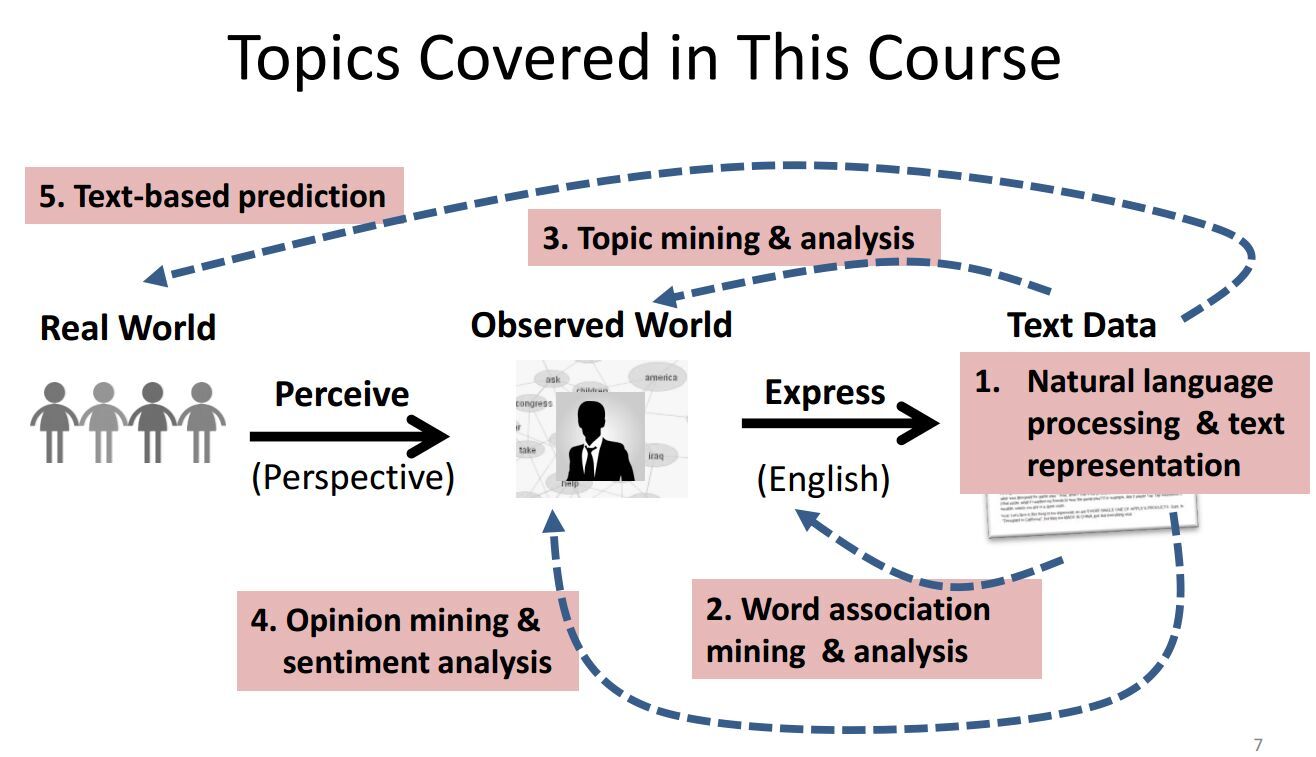
三、课程主要内容
3.1 Text representation
可以从以下几个方面来对文本进行表示:
lexicon analysis 词汇分析
syntactic analysis 句法分析
semantic analysis 语义分析
pragmatic analysis 实用性分析
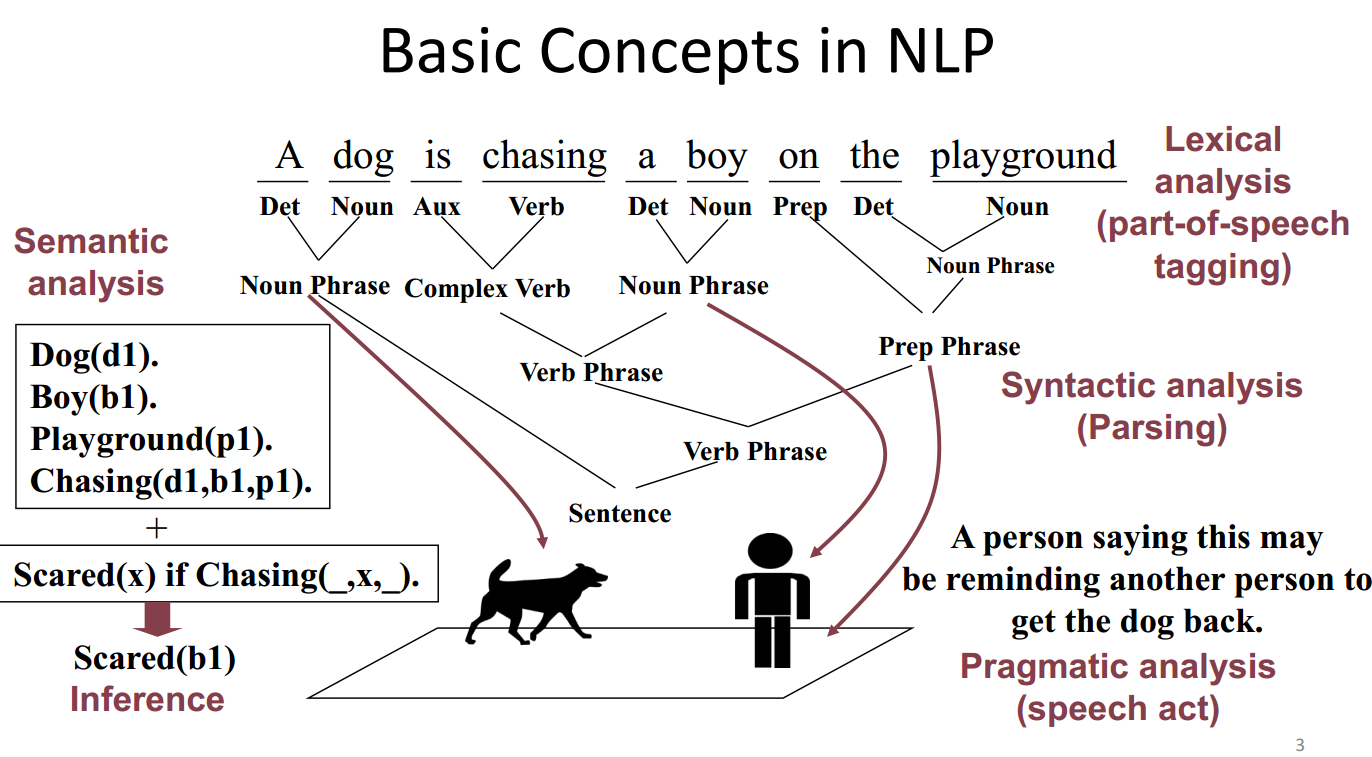
文本表示有很多种方法:Multiple ways of representing text are possible
string, words, syntactic structures, entity-relation graphs, predicates…
这门公开课中,主要讨论word 层面的文本表示方法,word relation analysis,topic analysis,sentiment analysis.
3.2 word association mining and analysis
(1)word 之间有两种基本关系:Paradigmatic vs. Syntagmatic
Paradigmatic (词形没有变化)E.g., “cat” and “dog”; “Monday” and “Tuesday”
Syntagmatic:(组合关系) E.g., “cat” and “sit”; “car” and “drive”
这两种关系的研究在很多NLP任务中都有重要的意义,如:位置标注,语法分析(parsing),实体识别,词汇拓展。
(2)对这两种关系的挖掘方法:
Paradigmatic ,文本内容的相似性
Syntagmatic,文本同时出现的概率

(3)分别介绍下两种关系挖掘的方法
Paradigmatic Relation Discovery,相似词的发现
word context 表示:bag of word、vector space model (VSM)
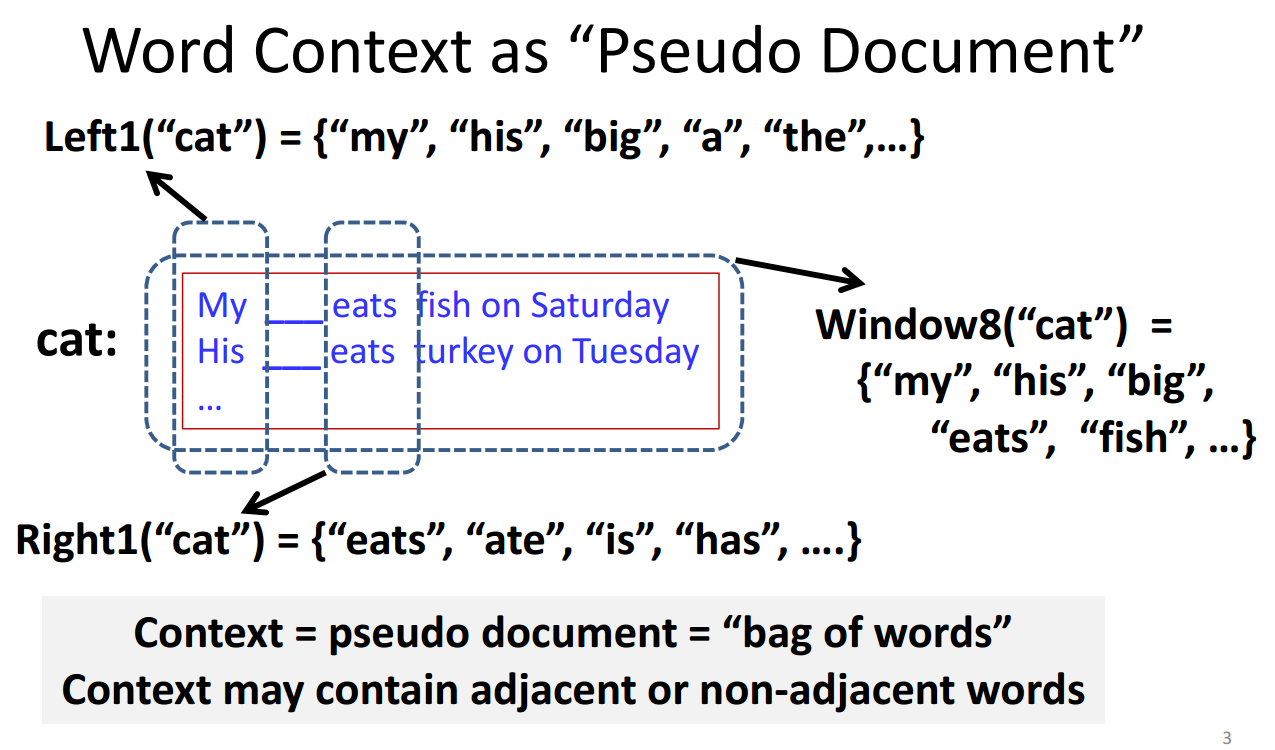
计算向量之间的相似度:(EOWC)

总结:相似词的计算,步骤如下:
从文档中表示两个词的相关词袋;计算相关词袋向量的相似度;选取相似度最高的词。
在表示词向量的方法中,BM25+IDF是the state of art.
Syntagmatic Relation Discovery: Entropy,组合关系的发现
熵:衡量变量X的随机性
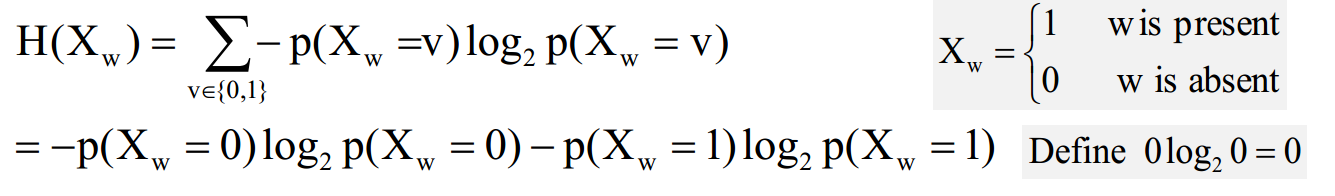
条件熵:
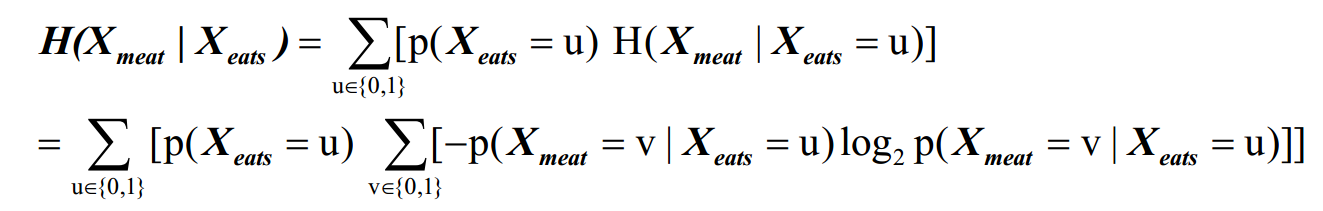
升序排列取top-k生成候选集
互信息 mutual information :I(X; Y)= H(X) – H(X|Y) = H(Y)-H(Y|X),倒序取top-k生成候选集
KL-divergence :KL散度( Kullback–Leibler divergence),又称相对熵(relative entropy),是描述两个概率分布P和Q差异的一种方法。在信息论中,D(P||Q)表示当用概率分布Q来拟合真实分布P时,产生的信息损耗,其中P表示真实分布,Q表示P的拟合分布。
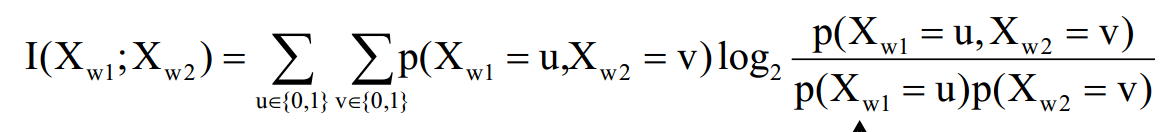

text mining and analytics 是一门在coursera上的公开课,由美国伊利诺伊大学香槟分校(UIUC)计算机系教授 chengxiang zhai 讲授,公开课链接:https://class.coursera.org/textanalytics-001/wiki/view?page=Programming_Assignments_Overview。
二、课程大纲:
三、课程主要内容
3.1 Text representation
可以从以下几个方面来对文本进行表示:
lexicon analysis 词汇分析
syntactic analysis 句法分析
semantic analysis 语义分析
pragmatic analysis 实用性分析
文本表示有很多种方法:Multiple ways of representing text are possible
string, words, syntactic structures, entity-relation graphs, predicates…
这门公开课中,主要讨论word 层面的文本表示方法,word relation analysis,topic analysis,sentiment analysis.
3.2 word association mining and analysis
(1)word 之间有两种基本关系:Paradigmatic vs. Syntagmatic
Paradigmatic (词形没有变化)E.g., “cat” and “dog”; “Monday” and “Tuesday”
Syntagmatic:(组合关系) E.g., “cat” and “sit”; “car” and “drive”
这两种关系的研究在很多NLP任务中都有重要的意义,如:位置标注,语法分析(parsing),实体识别,词汇拓展。
(2)对这两种关系的挖掘方法:
Paradigmatic ,文本内容的相似性
Syntagmatic,文本同时出现的概率
(3)分别介绍下两种关系挖掘的方法
Paradigmatic Relation Discovery,相似词的发现
word context 表示:bag of word、vector space model (VSM)
计算向量之间的相似度:(EOWC)
总结:相似词的计算,步骤如下:
从文档中表示两个词的相关词袋;计算相关词袋向量的相似度;选取相似度最高的词。
在表示词向量的方法中,BM25+IDF是the state of art.
Syntagmatic Relation Discovery: Entropy,组合关系的发现
熵:衡量变量X的随机性
条件熵:
升序排列取top-k生成候选集
互信息 mutual information :I(X; Y)= H(X) – H(X|Y) = H(Y)-H(Y|X),倒序取top-k生成候选集
KL-divergence :KL散度( Kullback–Leibler divergence),又称相对熵(relative entropy),是描述两个概率分布P和Q差异的一种方法。在信息论中,D(P||Q)表示当用概率分布Q来拟合真实分布P时,产生的信息损耗,其中P表示真实分布,Q表示P的拟合分布。

相关文章推荐
- 第6章 面向对象(高级篇)
- HTTP Live Streaming直播(iOS直播)技术分析与实现
- fragment与viewPager的结合
- 今天在php中把==写成了=
- Java Servlet 简介
- 双向链表的C++实现
- day08—SQL高级查询
- 2016第9周四
- js和jquery的DOM事件大全
- AngularJS 常用模块书写建议
- JS学习笔记:JavaScript匿名函数与闭包(closure)
- C# 文件操作类集合(一) 路径
- 占座
- 继承中的“虚方法,抽象类,接口”使用场景
- Elasticsearch-4种内置分析器
- ubuntu下软件包安装故障解决方案(深入剖析专治疑难)
- C++中关于类(封装、继承、多态)区别于结构体的理解
- linux生产服务器有关网络状态的优化措施
- 程序员十大编程算法
- 51nod 1066 Bash游戏