Python高级爬虫(三):数据存储以及多线程
2016-03-01 11:01
871 查看
*原创作者:VillanCh
目的:通常我们需要对爬虫捕捉的数据进行分析,处理,再次利用或者格式化,显然我们不能只是把爬虫捕捉到的数据在内存中处理,然后打印在屏幕上。在本章,我将介绍几种主流的数据存储方法。爬虫处理数据的能力往往是决定爬虫价值的决定性因素,同时一个稳定的存储数据的方法也绝对是一个爬虫的价值体现。
另外,采用多开线程的爬虫,创造多个并行线程协调工作也绝对是提高爬虫效率,降低失败率的好办法。
1、 存储索引或者直接下载数据
2、CSV
3、MySQL
关于线程:
如果读者并不会python的线程处理,可以参考这篇文章。
分为函数式和类包装,这两个方法进行线程处理。
步骤1:了解网站结构
步骤2:编写脚本
步骤3:测试
首先我们需要了解一下我们的目标(为了避免广告嫌疑,这里还是以freebuf作为目标吧)
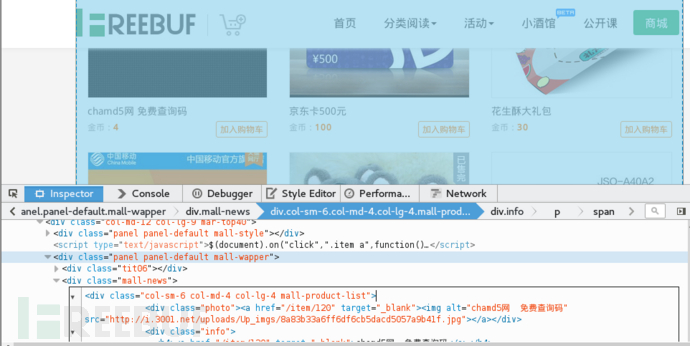
审查元素发现下面的div标签包含了单个的商品信息,
这样我们就轻松加愉快地找到了img所在的地方,那么根据这些,我们可以指定简单的方案:获取商品的所在的标签,然后由于商品标签的一致性,我们可以一层一层索引下去找到图片的位置,当然有个不保险的办法就是,获取的直接获取img,(幸运的是,在这个例子中只存在一个img标签),我们测试从简,节约时间,那么一两分钟我们就写出了自己的脚本:
这样我们就在自己的debug I/O看到了打印出的九个img标签:

然后我们用以前学到的技能,就足够把这些图片dump下来了,
完善脚本!
为了适配图片的格式,我们这里这样处理。
不过不是绝对的,某些时候这样做就不合适:
urlretrieve这个方法是我们以前接触过的,用于下载图片,还可以下载整个页面:
然后我们可以看一下成果,这样做的好处就是避免下来一大堆无关的图片,(有些时候我们下载整站,然后提取图片会发现各种图片混在一起了,那样确实烦得很):
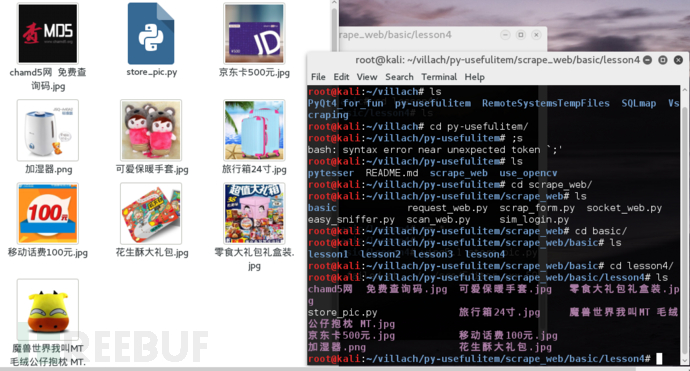
效果可以说是还不错吧,当然我懒并没有把图片建立文件夹存起来。
Fruit,cost
Apple,1.00
Banana,0.30
Pear,1.25
看起来就是表格的压缩版,其实真的没有什么奇怪的,这个很简单的对吧?当然,大家都能想到这种方法存储表格再好不过了。不过笔者在这里建议:如果你只有一个table要处理,复制粘贴应该是比这样快,如果一堆table要处理,或者是要从各种数据中挑选出表格,然后组合成一张新表,这样无疑可以加快你的速度。
那么我们就举一个例子来介绍一个下我们下一个例子。一定是一个有趣的体验:
作为上一个例子的拓展:我们腰身成一个.csv文件,存储每个商品的名称和需要的金币数。
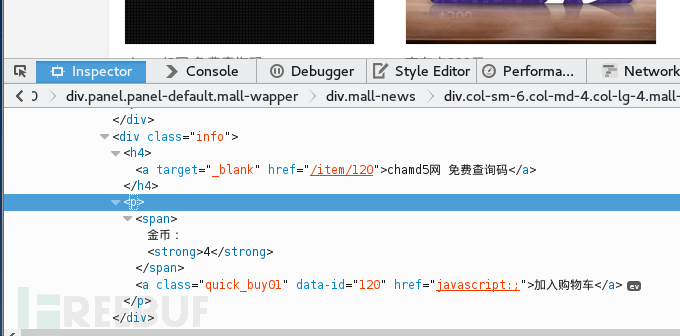
我们观察一下具体的金币位置,商品信息都在哪里?笔者相信大家已经看到了,那么接下来我们得先整理一下获取info的办法:
仅仅一步我们就可以得到信息位置。
Div(class=info)->h4->商品信息
Div(class=info)->p->strong->商品价格
那么我们这就很简单了,对不对?
在使用csv模块时,打开一个文件然后把文件描述符传入csv的writer然后写入row,但是由于我们这里存在中文,要注意要utf-8处理一下,否则报错或者是中文没法正常显示:
那么最后我们得到了.csv文件,这个文件可以被excel打开的,在我的linux中,已经被识别成了csv:

但是这里要注意中文编码问题。具体的解决办法限于篇幅我就不介绍了。
0、提前建立好数据库scraping,建立好表items
1、引入pymysql库
2、通过数据库参数建立一个链接conn,
3、Cur.conn.cursor()
4、Cur.execute(query)
5、如果需要的话还需要使用Cur.commit()
6、Cur.close()
7、Conn.close()
数据库建立:CREATE DATABASE `scraping` DEFAULTCHARACTER SET utf8 COLLATE utf8_general_ci;
创建表:CREATE TABLE item(namevarchar(255),price int(11));
插入:INSERT INTO item (name,price) VALUES(‘test’,4);
删除:DELETE FROM item WHRER name=’test’
稍微修改一下上面的代码就可以简单适配MySQL了。
当然上面的代码只是展示最简单的用法而已,我们还需要弄清楚的是编码问题,数据库还需要配置,要知道毕竟数据库的使用如果处理不好的话,也是一个不大不小的问题。
BDB是oracle的一个轻量型嵌入式数据库,只支持key-value数据形式存储,介于内存数据库和硬盘数据库之间,是单写入多读取的相当好的解决方案。
BDB的python接口,bsddb模块,可以把BDB的数据库读写操作作为一个数组来进行。查阅python2手册可以找到这个模块,非常易于使用。
笔者在这里建议,使用BDB来存储url。笔者可以提出一个比较可行的方案,一个url的md5值作为key,url的值作为value,读写直接操作数据库,简化url管理。
1、同步问题
2、线程池管理
……
高效稳定的线程管理是编写多线程程序或者脚本的基础。
Python自制线程池:线程池是解决并发问题的有力武器,在多线程爬虫设计中,我们仍然可以使用这样的方法改装一下
然后根据这样的需求,我们初步设计一下这个多线程爬虫系统应该是怎么样的。
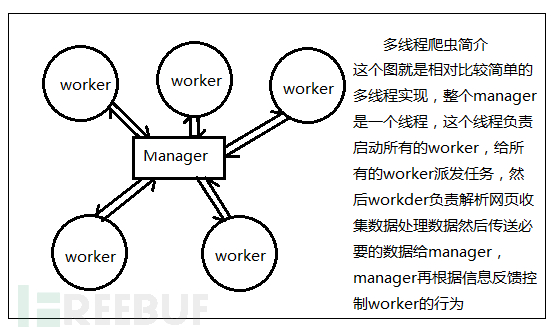
在开始之前,我们首先需要明白一个manager的最基础职能:
1、维护任务队列
2、派发任务
3、处理子线程返回的数据
这样我们可以初步设想一下,再主线程的循环中进行所有的操作。那么,我们就意识到了这个manager的重要性了。那么就按照我们现在的想法,我们来整理以下这个多线程爬虫的设计思路:
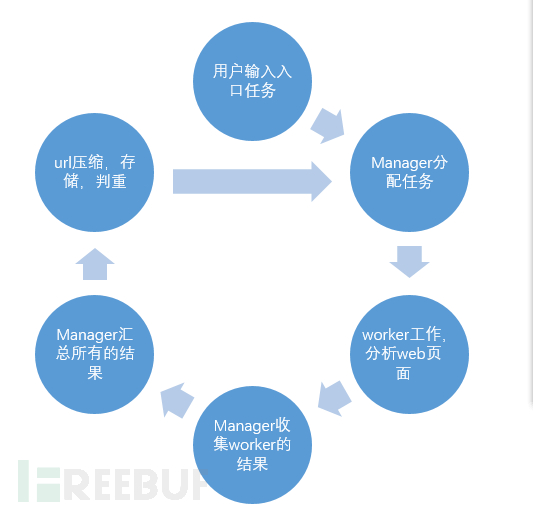
按着这个思路,笔者实现了两套多线程爬虫,一套是简易,不稳定的版本,一套是相对稳定的版本。为什么不是直接看第二套比较完整的呢?显然第一个版本简易不稳定,但是易于大家理解架构,第二个版本相对稳定,但是读起来可能有点痛苦。
具体的代码在Github。
因为单个脚本太长了300+行。
第二个版本,为了项目管理方便也为了贴合我自己的习惯,我就使用了vs13作为开发和管理工具,然后代码现在托管在github上,项目目录如下:
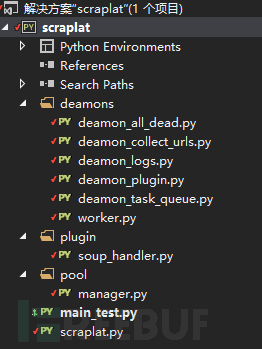
参见Github链接,如果读者喜欢这个项目可以随意fork或者赏star,笔者将会更有力气维护这个多线程爬虫。当然这是一个未完成的项目,但是现在功能基本是完整的,可以实现自己自定义线程数稳定爬取固定域名下的网站sitemap,如果需要爬取内容的话,需要使用者自己去定义worker的分析部分,url处理我已经替大家基本写完了,这个项目的目的实际就是作为一个scraper
platform存在,因此取名scraplat,但是笔者真的水平有限,赶着这篇文章之前完成了基本功能,在今后的一段时间内这个项目还会不断完善,实现动态网页爬取,自动化网页测试等高级接口。如果对爬虫技术感兴趣的读者可以长期关注以下这个项目,也欢迎大家在留言区写下自己想要实现的功能。
但是这还是不够,直到现在为止,我们只能处理静态的网页,如果想要处理动态加载的网页,(不知道有没有好事的读者曾经试过爬取淘宝商品页面,试过的朋友会发现传统的方案是没有办法处理淘宝商品页面的)。还有我们有时候希望我们的爬虫能真正的进入互联网,自由爬行,这些都是我们渴望解决的问题。
在下一章中,我们将学习下面的内容:
1、为爬虫添加代理
2、动态页面爬取的解决方案讨论
*原创作者:VillanCh,本文属FreeBuf原创奖励计划文章,未经作者本人及FreeBuf许可,切勿私自转载
0×00 介绍
本文我们就两个方面来讨论如何改进我们的爬虫:数据存储和多线程,当然我承认这是为我们以后要讨论的一些东西做铺垫。目的:通常我们需要对爬虫捕捉的数据进行分析,处理,再次利用或者格式化,显然我们不能只是把爬虫捕捉到的数据在内存中处理,然后打印在屏幕上。在本章,我将介绍几种主流的数据存储方法。爬虫处理数据的能力往往是决定爬虫价值的决定性因素,同时一个稳定的存储数据的方法也绝对是一个爬虫的价值体现。
另外,采用多开线程的爬虫,创造多个并行线程协调工作也绝对是提高爬虫效率,降低失败率的好办法。
0×01 引导
我们就接下来要讲的部分做一个简单的引导,关于数据存储方式:1、 存储索引或者直接下载数据
2、CSV
3、MySQL
关于线程:
如果读者并不会python的线程处理,可以参考这篇文章。
分为函数式和类包装,这两个方法进行线程处理。
0×02 数据存储:存储索引或者直接下载数据
关于这一点我觉得没有必要做深入的解释,因为这一点我们在前几篇文章中或多或少都有接触:比如制作sitemap:这里存储了整个网站你需要的链接,比如抓取freebuff文章生成.docx文档的这一节,这些其实都属于本节所说的数据存储方式。那么就本节而言,我再介绍一个例子,爬取一个freebuf商品列表区域所有的图片(听起来还是挺有趣的吧!?)步骤1:了解网站结构
步骤2:编写脚本
步骤3:测试
首先我们需要了解一下我们的目标(为了避免广告嫌疑,这里还是以freebuf作为目标吧)
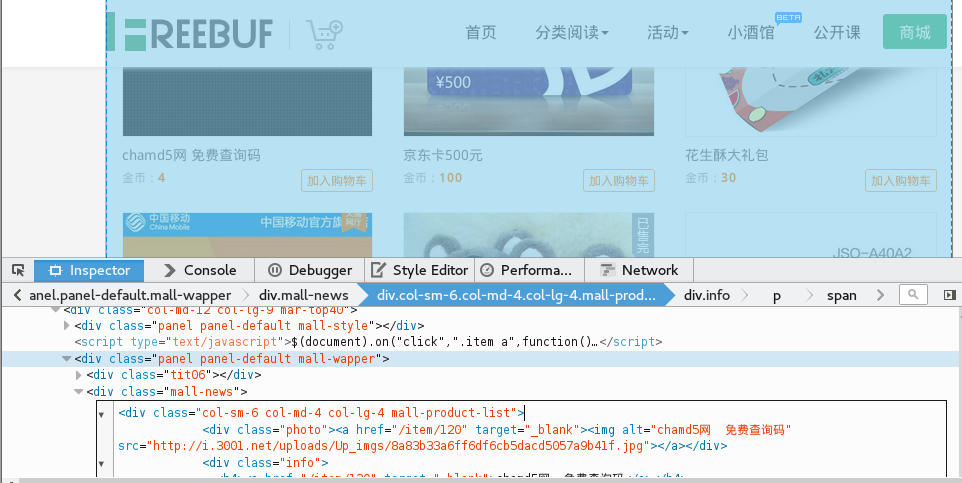
审查元素发现下面的div标签包含了单个的商品信息,
Div(class=nall-news)->div(class=col-sm6col-md-lg-4 mall-product-list)->div(class=photo)->a->img
这样我们就轻松加愉快地找到了img所在的地方,那么根据这些,我们可以指定简单的方案:获取商品的所在的标签,然后由于商品标签的一致性,我们可以一层一层索引下去找到图片的位置,当然有个不保险的办法就是,获取的直接获取img,(幸运的是,在这个例子中只存在一个img标签),我们测试从简,节约时间,那么一两分钟我们就写出了自己的脚本:
import urllib
from bs4 import BeautifulSoup
import re
url = 'http://shop.freebuf.com/'
print "prepare&reading to read theweb"
data = urllib.urlopen(url).read()
print data
print "parsing ... ... ... "
soup = BeautifulSoup(data)
#<div class="col-sm-6 col-md-4col-lg-4 mall-product-list">
itemlist =soup.findAll(name='div',attrs={'class':'col-sm-6 col-md-4 col-lg-4mall-product-list'})
for item in itemlist:
print item.img这样我们就在自己的debug I/O看到了打印出的九个img标签:

然后我们用以前学到的技能,就足够把这些图片dump下来了,
完善脚本!
import urllib
from bs4 import BeautifulSoup
import re
url = 'http://shop.freebuf.com/'
print "prepare&reading to read theweb"
data = urllib.urlopen(url).read()
print data
print "parsing ... ... ... "
soup = BeautifulSoup(data)
#<div class="col-sm-6 col-md-4col-lg-4 mall-product-list">
itemlist = soup.findAll(name='div',attrs={'class':'col-sm-6col-md-4 col-lg-4 mall-product-list'})
for item in itemlist:
"""为了适配图片的格式,我们这里这样处理。
不过不是绝对的,某些时候这样做就不合适:
""" print item.img['src'][-4:] """
urlretrieve这个方法是我们以前接触过的,用于下载图片,还可以下载整个页面:
""" urllib.urlretrieve(url=item.img['src'],filename=item.img['alt']+item.img['src'][-4:])
然后我们可以看一下成果,这样做的好处就是避免下来一大堆无关的图片,(有些时候我们下载整站,然后提取图片会发现各种图片混在一起了,那样确实烦得很):
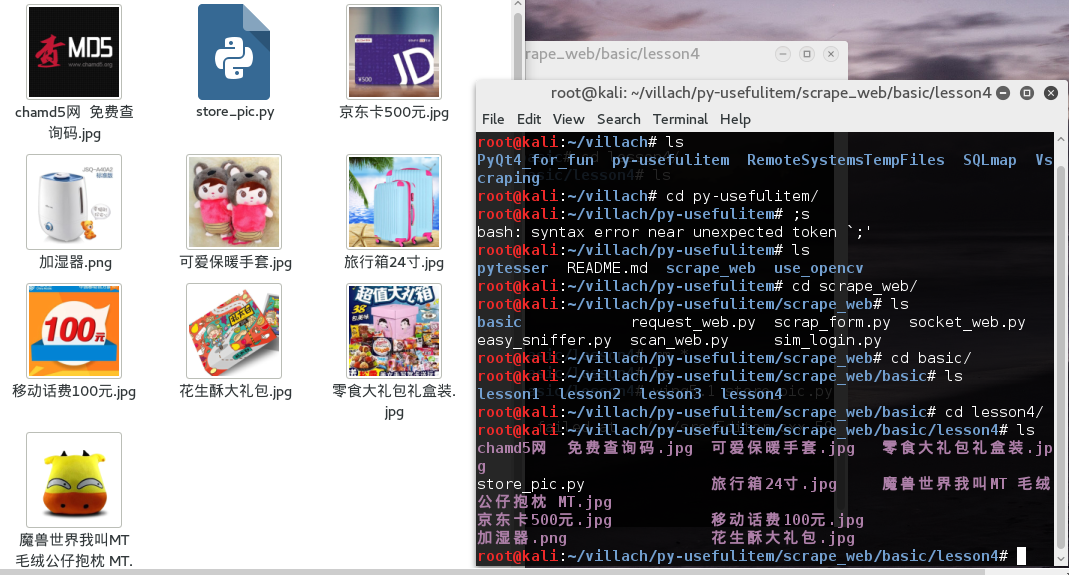
效果可以说是还不错吧,当然我懒并没有把图片建立文件夹存起来。
0×03 数据存储:CSV
CSV(comma-separated values),是目前比较流行的一种文件存储格式。被Excel和很多的应用程序支持。CSV文件存储的例子如下:Fruit,cost
Apple,1.00
Banana,0.30
Pear,1.25
看起来就是表格的压缩版,其实真的没有什么奇怪的,这个很简单的对吧?当然,大家都能想到这种方法存储表格再好不过了。不过笔者在这里建议:如果你只有一个table要处理,复制粘贴应该是比这样快,如果一堆table要处理,或者是要从各种数据中挑选出表格,然后组合成一张新表,这样无疑可以加快你的速度。
那么我们就举一个例子来介绍一个下我们下一个例子。一定是一个有趣的体验:
作为上一个例子的拓展:我们腰身成一个.csv文件,存储每个商品的名称和需要的金币数。
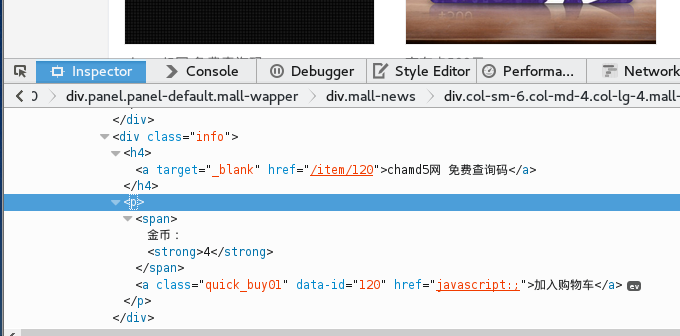
我们观察一下具体的金币位置,商品信息都在哪里?笔者相信大家已经看到了,那么接下来我们得先整理一下获取info的办法:
<div class="col-sm-6 col-md-4col-lg-4 mall-product-list">->div(class=info)
仅仅一步我们就可以得到信息位置。
Div(class=info)->h4->商品信息
Div(class=info)->p->strong->商品价格
那么我们这就很简单了,对不对?
在使用csv模块时,打开一个文件然后把文件描述符传入csv的writer然后写入row,但是由于我们这里存在中文,要注意要utf-8处理一下,否则报错或者是中文没法正常显示:
import urllib
from bs4 import BeautifulSoup
import csv
csvFile = open('items.csv','w+')
url = 'http://shop.freebuf.com/'
print "prepare&reading to read theweb"
data = urllib.urlopen(url).read()
print data
print "parsing ... ... ... "
soup = BeautifulSoup(data)
#<div class="col-sm-6 col-md-4col-lg-4 mall-product-list">
itemlist =soup.findAll(name='div',attrs={'class':'col-sm-6 col-md-4 col-lg-4mall-product-list'})
writer = csv.writer(csvFile)
writer.writerow(('name','price'))
for item in itemlist:
#name
#print item.find(name="h4").string
name = item.find(name='h4').string
#price
#print item.find(name='strong').string
price = item.find(name='strong').string
writer.writerow((name.encode('utf-8','ignore'),price.encode('utf-8','ignore')))
csvFile.close()
print "success to create the csvfile"那么最后我们得到了.csv文件,这个文件可以被excel打开的,在我的linux中,已经被识别成了csv:
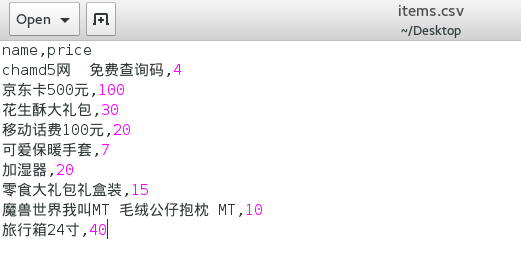
但是这里要注意中文编码问题。具体的解决办法限于篇幅我就不介绍了。
0×04 MySQL
我们在这一部分改造上面的例子,把MySQL整合在爬虫中,至于MySQL的安装配置我就不再解释了,我们简要梳理一下MySQL的py使用过程:0、提前建立好数据库scraping,建立好表items
1、引入pymysql库
2、通过数据库参数建立一个链接conn,
3、Cur.conn.cursor()
4、Cur.execute(query)
5、如果需要的话还需要使用Cur.commit()
6、Cur.close()
7、Conn.close()
数据库建立:CREATE DATABASE `scraping` DEFAULTCHARACTER SET utf8 COLLATE utf8_general_ci;
创建表:CREATE TABLE item(namevarchar(255),price int(11));
插入:INSERT INTO item (name,price) VALUES(‘test’,4);
删除:DELETE FROM item WHRER name=’test’
稍微修改一下上面的代码就可以简单适配MySQL了。
import urllib
from bs4 import BeautifulSoup
import pymysql
conn =pymysql.connect(host="127.0.0.1",user='root',passwd='toor',db='mysql')
cur = conn.cursor()
cur.execute('USE scraping')
url = 'http://shop.freebuf.com/'
print "prepare&reading to read theweb"
data = urllib.urlopen(url).read()
print data
print "parsing ... ... ... "
soup = BeautifulSoup(data)
#<div class="col-sm-6 col-md-4col-lg-4 mall-product-list">
itemlist =soup.findAll(name='div',attrs={'class':'col-sm-6 col-md-4 col-lg-4mall-product-list'})
for item in itemlist:
#name
#print item.find(name="h4").string
name = item.find(name='h4').string
#price
#print item.find(name='strong').string
price = item.find(name='strong').string
query = 'insert item(name,price) value('+ "\'" +name.encode('utf-8','ignore') + "\'," +price.encode('utf-8','ignore') +');'
cur.execute(query)
conn.commit()
print "success to update thedatabase"
print "preparing to read the data fromdatabase!"
query = "Select * from item where1;"
cur.execute(query)
print cur.fetchall()
cur.close()
conn.close()当然上面的代码只是展示最简单的用法而已,我们还需要弄清楚的是编码问题,数据库还需要配置,要知道毕竟数据库的使用如果处理不好的话,也是一个不大不小的问题。
0×06 嵌入式数据库BerkeleyDB(BDB)
关于介绍我不想太官方,那么简单来说,笔者对BDB的认识如下:BDB是oracle的一个轻量型嵌入式数据库,只支持key-value数据形式存储,介于内存数据库和硬盘数据库之间,是单写入多读取的相当好的解决方案。
BDB的python接口,bsddb模块,可以把BDB的数据库读写操作作为一个数组来进行。查阅python2手册可以找到这个模块,非常易于使用。
笔者在这里建议,使用BDB来存储url。笔者可以提出一个比较可行的方案,一个url的md5值作为key,url的值作为value,读写直接操作数据库,简化url管理。
0×05 多线程
我们回顾sitemap爬虫的时候,我们发现,爬取一个相对比较小的网站(一百页左右)的时候大概用了2分40秒(加上为了避免频繁请求设置的延时),显然对于我们来说这是不够的,我们当然有很多办法来加速,但是笔者在这里并不建议修改源代码中的url请求等待时间。我们仅仅多开线程执行就可以达到我们预期的效果,这是基本所有类似程序都会采用的方法,但是实际的使用的时候,可能会有各种问题:1、同步问题
2、线程池管理
……
高效稳定的线程管理是编写多线程程序或者脚本的基础。
预备知识:
Python的线程模块Threading模块,【链接】Python自制线程池:线程池是解决并发问题的有力武器,在多线程爬虫设计中,我们仍然可以使用这样的方法改装一下
理论:
我们采用多线程爬虫的时候,要清楚这个过程:每个爬虫爬到的数据都要汇总到一起,然后处理,然后再分配新任务到空闲的爬虫。然后根据这样的过程我们可以想到这样的过程好像和master-slave模式类似,如果大家没有接触过这个东西也没关系,简单来说,就是包工头和工人的关系,包工头负责整个小项目的统筹和任务派发,工人负责埋头苦干。然后根据这样的需求,我们初步设计一下这个多线程爬虫系统应该是怎么样的。
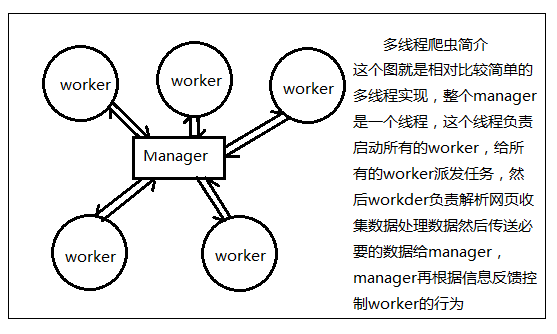
在开始之前,我们首先需要明白一个manager的最基础职能:
1、维护任务队列
2、派发任务
3、处理子线程返回的数据
这样我们可以初步设想一下,再主线程的循环中进行所有的操作。那么,我们就意识到了这个manager的重要性了。那么就按照我们现在的想法,我们来整理以下这个多线程爬虫的设计思路:
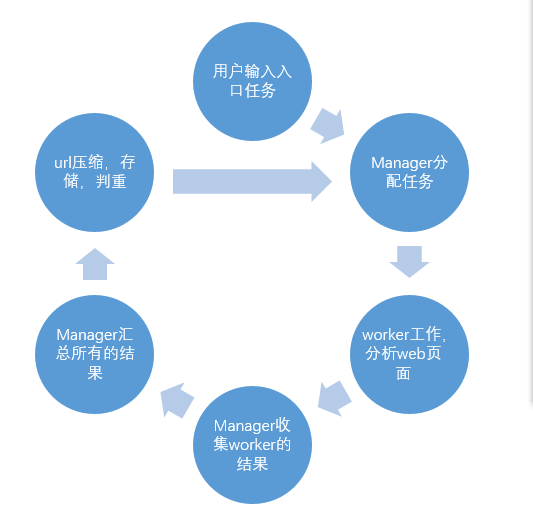
按着这个思路,笔者实现了两套多线程爬虫,一套是简易,不稳定的版本,一套是相对稳定的版本。为什么不是直接看第二套比较完整的呢?显然第一个版本简易不稳定,但是易于大家理解架构,第二个版本相对稳定,但是读起来可能有点痛苦。
具体的代码在Github。
因为单个脚本太长了300+行。
第二个版本,为了项目管理方便也为了贴合我自己的习惯,我就使用了vs13作为开发和管理工具,然后代码现在托管在github上,项目目录如下:
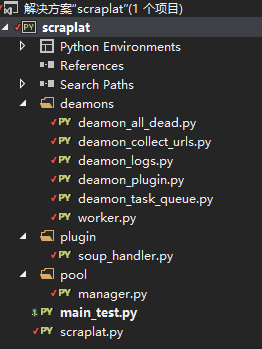
参见Github链接,如果读者喜欢这个项目可以随意fork或者赏star,笔者将会更有力气维护这个多线程爬虫。当然这是一个未完成的项目,但是现在功能基本是完整的,可以实现自己自定义线程数稳定爬取固定域名下的网站sitemap,如果需要爬取内容的话,需要使用者自己去定义worker的分析部分,url处理我已经替大家基本写完了,这个项目的目的实际就是作为一个scraper
platform存在,因此取名scraplat,但是笔者真的水平有限,赶着这篇文章之前完成了基本功能,在今后的一段时间内这个项目还会不断完善,实现动态网页爬取,自动化网页测试等高级接口。如果对爬虫技术感兴趣的读者可以长期关注以下这个项目,也欢迎大家在留言区写下自己想要实现的功能。
0×06 总结与下章预告
本章我们讨论了数据存储和多线程爬虫的实现,如果大家明白原理以后,就可以自己设计出自己的多线程爬虫甚至是分布式爬虫。到现在位置,我们手中的爬虫才算是像模像样。但是这还是不够,直到现在为止,我们只能处理静态的网页,如果想要处理动态加载的网页,(不知道有没有好事的读者曾经试过爬取淘宝商品页面,试过的朋友会发现传统的方案是没有办法处理淘宝商品页面的)。还有我们有时候希望我们的爬虫能真正的进入互联网,自由爬行,这些都是我们渴望解决的问题。
在下一章中,我们将学习下面的内容:
1、为爬虫添加代理
2、动态页面爬取的解决方案讨论
*原创作者:VillanCh,本文属FreeBuf原创奖励计划文章,未经作者本人及FreeBuf许可,切勿私自转载

相关文章推荐
- Python练习(1):递归和动态规划的简单应用
- Python迭代器和生成器
- python将时间修改成本地的TIME ZONE
- python学习常用网站
- learn python the hard way(笨办法学python) 练习50
- Python 的方法重载
- python之面向对象
- Python 2.7 因为少写括号导致的 SyntaxError 错误
- python编码规范
- Python字符串的格式化
- Python学习笔记,基础2
- python文本处理常用工具代码(一)
- Python与机器学习(四)决策树
- python中print的嚣技巧
- 转 Python 字符串操作(string替换、删除、截取、复制、连接、比较、查找、包含、大小写转换、分割等)
- Python_Python遍历列表的四种方法
- Python 30 行代码实现小型多线程任务队列
- Windows 8.1 (企业版64bits) 上安装Python3.5失败解决
- 面向对象_python
- Python解析json文件相关知识学习