大数据日志收集框架之Flume入门
2016-02-29 00:00
381 查看
Flume是Cloudrea公司开源的一款优秀的日志收集框架,主要经历了两个大的版本,分别是
Flume-OG
Flume-NG
OG是0.9.x的版本,依赖zookeeper,角色职责不够单一,
NG是新版本指1.x的版本,官网解释它更轻量级,更小,角色职责更单一,利用点到点进行容错,当然这也是以后的趋势,
要理解Flume,就首先理解它的架构,下面看下,官网的一张拓扑图:
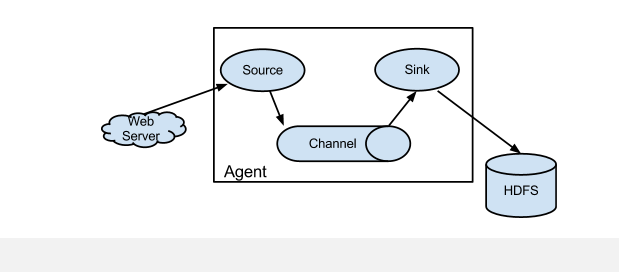
名词解释:
Source:泛指所有的日志收集源,可以是web页面,log文件,数据库,端口,卡口信息等
Channel:提供中转的临时存储区,可以是本地文件,redis,kakfa,数据库,内存等
Sink:指日志最终落地的存储区,可以是数据库,HDFS,Hbase,Hive,本地文件等
Agent:指上面三者组合后的一个完整的数据收集代理,有了这个代理,我们把它安装任何机器上进行收集日志,当然前提是这个Agent符合这个机器上的业务。
下面看下,安装实战例子:
首先下载flume-ng的安装包:
wget http://archive.apache.org/dist/flume/1.6.0/apache-flume-1.6.0-bin.tar.gz
解压
tar -zxvf apache-flume-1.6.0-bin.tar.gz
将根目录下的conf下的一些模板文件,重命名成正常文件
如果没有配置JAVA_HOME为环境变量的话,
则需要在flume-env.sh里面配置jdk的地址
1,然后新建一个first.properties的文件,加入以下配置:
Java代码

[webmaster@Hadoop -0-187 conf]$ cat first.properties
# example.conf: A single-node Flume configuration
# Name the components on this agent
#datasource
a1.sources = r1
#store
a1.sinks = k1
#transfer
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
配置例子2:收集本地日志到hadoop里面
hdfs的sink目前支持三种文件类型:
(1)SequenceFile 文本不可见
(2)DataStream 设置hdfs.writeFormat=Text,文本可见
(3)CompressedStream 设置hdfs.codeC=gzip, bzip2, lzo, lzop, snappy,其中一种,后面三个需要编译hadoop时支持才能设置。
默认是SequenceFile,以文本方式写进入的数据,是不可见的,除非改变类型为DataStream ,
然后设置hdfs.writeFormat=Text即可,这个选项默认是Writable
Java代码
a.sources=exec-source
a.sinks=hdfs-sink
a.channels=ch1
#####source conf
a.sources.exec-source.type=exec
a.sources.exec-source.command=tail -F /ROOT/server/flume/v.log
#####sink conf
a.sinks.hdfs-sink.type=hdfs
a.sinks.hdfs-sink.hdfs.path=hdfs://h1:9000/flume/events
a.sinks.hdfs-sink.hdfs.filePrefix=search
a.sinks.hdfs-sink.hdfs.rollInterval=10
a.sinks.hdfs-sink.hdfs.rollSize=0
#不设置压缩,指定文本方式加入hdfs
#a.sinks.hdfs-sink.hdfs.fileType=DataStream
#a.sinks.hdfs-sink.hdfs.writeFormat=Text
#设置压缩lzo或者snappy
a.sinks.hdfs-sink.hdfs.fileType=CompressedStream
#a.sinks.hdfs-sink.hdfs.codeC=snappy
#a.sinks.hdfs-sink.hdfs.codeC=lzo
#a.sinks.hdfs-sink.hdfs.codeC=lzop
#a.sinks.hdfs-sink.hdfs.codeC=gzip
a.sinks.hdfs-sink.hdfs.codeC=bzip2
####channels conf
a.channels.ch1.type=memory
a.channels.ch1.capacity=1000
a.sources.exec-source.channels=ch1
a.sinks.hdfs-sink.channel=ch1
启动命令: 最后的a与配置文件里面的agent的name必须一致
bin/flume-ng agent --conf conf --conf-file conf/to_hdfs.properties --name a
下面是一个按年月日时分,收集的日志:
Java代码
a.sources=exec-source
a.sinks=hdfs-sink
a.channels=ch1
#####source conf
a.sources.exec-source.type=exec
a.sources.exec-source.command=tail -F /ROOT/server/flume/v.log
#####sink conf
a.sinks.hdfs-sink.type=hdfs
a.sinks.hdfs-sink.hdfs.path=hdfs://h1:9000/flume/events/%Y/%m/%d/%H/%M
a.sinks.hdfs-sink.hdfs.filePrefix=search
a.sinks.hdfs-sink.hdfs.rollInterval=10
a.sinks.hdfs-sink.hdfs.rollSize=0
a.sinks.hdfs-sink.hdfs.useLocalTimeStamp=true
#不设置压缩
#a.sinks.hdfs-sink.hdfs.fileType=DataStream
#a.sinks.hdfs-sink.hdfs.writeFormat=Text
#设置压缩lzo或者snappy
a.sinks.hdfs-sink.hdfs.fileType=CompressedStream
#a.sinks.hdfs-sink.hdfs.codeC=snappy
#a.sinks.hdfs-sink.hdfs.codeC=lzo
#a.sinks.hdfs-sink.hdfs.codeC=lzop
#a.sinks.hdfs-sink.hdfs.codeC=gzip
a.sinks.hdfs-sink.hdfs.codeC=bzip2
####channels conf
a.channels.ch1.type=memory
a.channels.ch1.capacity=1000
a.sources.exec-source.channels=ch1
a.sinks.hdfs-sink.channel=ch1
最后看下,配置flume监听linux的rsyslog的日志:
可用nc模拟telent发送数据到5140端口
echo "<1>hello via syslog" | nc -t localhost 5140
配置/etc/rsyslog.conf
在最后一行,加入tcp转发端口:
Java代码
*.* @@localhost :5140
如果不生效,可考虑:取消注释,使下面的生效:
Java代码
# Provides TCP syslog reception
#$ModLoad imtcp
#$InputTCPServerRun 5140
改完之后,重启rsyslog
Java代码
sudo service rsyslog restart
然后配置flume
flume监听rsyslog,或者syslog
Java代码
a.sources=exec-source
a.sinks=hdfs-sink
a.channels=ch1
#####source conf rsyslog
a.sources.exec-source.type=syslogtcp
a.sources.exec-source.port=5140
a.sources.exec-source.host=0.0.0.0
#####sink conf
a.sinks.hdfs-sink.type=hdfs
a.sinks.hdfs-sink.hdfs.path=hdfs://h1:9000/flume/events/%Y/%m/%d/%H/%M
a.sinks.hdfs-sink.hdfs.filePrefix=search
a.sinks.hdfs-sink.hdfs.rollInterval=10
a.sinks.hdfs-sink.hdfs.rollSize=0
a.sinks.hdfs-sink.hdfs.useLocalTimeStamp=true
#不设置压缩
#a.sinks.hdfs-sink.hdfs.fileType=DataStream
#a.sinks.hdfs-sink.hdfs.writeFormat=Text
#设置压缩lzo或者snappy
a.sinks.hdfs-sink.hdfs.fileType=CompressedStream
#a.sinks.hdfs-sink.hdfs.codeC=snappy
#a.sinks.hdfs-sink.hdfs.codeC=lzo
#a.sinks.hdfs-sink.hdfs.codeC=lzop
#a.sinks.hdfs-sink.hdfs.codeC=gzip
a.sinks.hdfs-sink.hdfs.codeC=bzip2
####channels conf
a.channels.ch1.type=memory
a.channels.ch1.capacity=1000
a.sources.exec-source.channels=ch1
a.sinks.hdfs-sink.channel=ch1
配置完成启动:
然后看flume的log再次登陆终端,推出终端,sudo命令执行失败,flume都会采集转发到hdfs上存储起来
总结:
Flume不愧是大数据平台的一个标准组件,与Hadoop能非常完美的结合,当然,除了与hadoop结合外,还支持Hbase,Hive等, 相比Logstash+ElasticSearch+Kibana的ELK里面的Logstash,flume比较适合结构化的日志收集,存储,而Logstasch则还可以非常方便的解析,清洗数据,虽然flume通过扩展jar也能支持,但logstash使用的是Jruby语法,相比java,则比较简单。这也是ELK都能够快速部署的原因,当然flume也支持向elasticsearch推送索引数据,通过扩展的jar,几乎大部分功能都能轻松实现,所以,没有谁最好用,谁最不好用,只有谁最适合业务,才是最好的!
Flume-OG
Flume-NG
OG是0.9.x的版本,依赖zookeeper,角色职责不够单一,
NG是新版本指1.x的版本,官网解释它更轻量级,更小,角色职责更单一,利用点到点进行容错,当然这也是以后的趋势,
要理解Flume,就首先理解它的架构,下面看下,官网的一张拓扑图:
名词解释:
Source:泛指所有的日志收集源,可以是web页面,log文件,数据库,端口,卡口信息等
Channel:提供中转的临时存储区,可以是本地文件,redis,kakfa,数据库,内存等
Sink:指日志最终落地的存储区,可以是数据库,HDFS,Hbase,Hive,本地文件等
Agent:指上面三者组合后的一个完整的数据收集代理,有了这个代理,我们把它安装任何机器上进行收集日志,当然前提是这个Agent符合这个机器上的业务。
下面看下,安装实战例子:
首先下载flume-ng的安装包:
wget http://archive.apache.org/dist/flume/1.6.0/apache-flume-1.6.0-bin.tar.gz
解压
tar -zxvf apache-flume-1.6.0-bin.tar.gz
将根目录下的conf下的一些模板文件,重命名成正常文件
如果没有配置JAVA_HOME为环境变量的话,
则需要在flume-env.sh里面配置jdk的地址
1,然后新建一个first.properties的文件,加入以下配置:
Java代码
[webmaster@Hadoop -0-187 conf]$ cat first.properties
# example.conf: A single-node Flume configuration
# Name the components on this agent
#datasource
a1.sources = r1
#store
a1.sinks = k1
#transfer
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
配置例子2:收集本地日志到hadoop里面
hdfs的sink目前支持三种文件类型:
(1)SequenceFile 文本不可见
(2)DataStream 设置hdfs.writeFormat=Text,文本可见
(3)CompressedStream 设置hdfs.codeC=gzip, bzip2, lzo, lzop, snappy,其中一种,后面三个需要编译hadoop时支持才能设置。
默认是SequenceFile,以文本方式写进入的数据,是不可见的,除非改变类型为DataStream ,
然后设置hdfs.writeFormat=Text即可,这个选项默认是Writable
Java代码
a.sources=exec-source
a.sinks=hdfs-sink
a.channels=ch1
#####source conf
a.sources.exec-source.type=exec
a.sources.exec-source.command=tail -F /ROOT/server/flume/v.log
#####sink conf
a.sinks.hdfs-sink.type=hdfs
a.sinks.hdfs-sink.hdfs.path=hdfs://h1:9000/flume/events
a.sinks.hdfs-sink.hdfs.filePrefix=search
a.sinks.hdfs-sink.hdfs.rollInterval=10
a.sinks.hdfs-sink.hdfs.rollSize=0
#不设置压缩,指定文本方式加入hdfs
#a.sinks.hdfs-sink.hdfs.fileType=DataStream
#a.sinks.hdfs-sink.hdfs.writeFormat=Text
#设置压缩lzo或者snappy
a.sinks.hdfs-sink.hdfs.fileType=CompressedStream
#a.sinks.hdfs-sink.hdfs.codeC=snappy
#a.sinks.hdfs-sink.hdfs.codeC=lzo
#a.sinks.hdfs-sink.hdfs.codeC=lzop
#a.sinks.hdfs-sink.hdfs.codeC=gzip
a.sinks.hdfs-sink.hdfs.codeC=bzip2
####channels conf
a.channels.ch1.type=memory
a.channels.ch1.capacity=1000
a.sources.exec-source.channels=ch1
a.sinks.hdfs-sink.channel=ch1
启动命令: 最后的a与配置文件里面的agent的name必须一致
bin/flume-ng agent --conf conf --conf-file conf/to_hdfs.properties --name a
下面是一个按年月日时分,收集的日志:
Java代码
a.sources=exec-source
a.sinks=hdfs-sink
a.channels=ch1
#####source conf
a.sources.exec-source.type=exec
a.sources.exec-source.command=tail -F /ROOT/server/flume/v.log
#####sink conf
a.sinks.hdfs-sink.type=hdfs
a.sinks.hdfs-sink.hdfs.path=hdfs://h1:9000/flume/events/%Y/%m/%d/%H/%M
a.sinks.hdfs-sink.hdfs.filePrefix=search
a.sinks.hdfs-sink.hdfs.rollInterval=10
a.sinks.hdfs-sink.hdfs.rollSize=0
a.sinks.hdfs-sink.hdfs.useLocalTimeStamp=true
#不设置压缩
#a.sinks.hdfs-sink.hdfs.fileType=DataStream
#a.sinks.hdfs-sink.hdfs.writeFormat=Text
#设置压缩lzo或者snappy
a.sinks.hdfs-sink.hdfs.fileType=CompressedStream
#a.sinks.hdfs-sink.hdfs.codeC=snappy
#a.sinks.hdfs-sink.hdfs.codeC=lzo
#a.sinks.hdfs-sink.hdfs.codeC=lzop
#a.sinks.hdfs-sink.hdfs.codeC=gzip
a.sinks.hdfs-sink.hdfs.codeC=bzip2
####channels conf
a.channels.ch1.type=memory
a.channels.ch1.capacity=1000
a.sources.exec-source.channels=ch1
a.sinks.hdfs-sink.channel=ch1
最后看下,配置flume监听linux的rsyslog的日志:
可用nc模拟telent发送数据到5140端口
echo "<1>hello via syslog" | nc -t localhost 5140
配置/etc/rsyslog.conf
在最后一行,加入tcp转发端口:
Java代码
*.* @@localhost :5140
如果不生效,可考虑:取消注释,使下面的生效:
Java代码
# Provides TCP syslog reception
#$ModLoad imtcp
#$InputTCPServerRun 5140
改完之后,重启rsyslog
Java代码
sudo service rsyslog restart
然后配置flume
flume监听rsyslog,或者syslog
Java代码
a.sources=exec-source
a.sinks=hdfs-sink
a.channels=ch1
#####source conf rsyslog
a.sources.exec-source.type=syslogtcp
a.sources.exec-source.port=5140
a.sources.exec-source.host=0.0.0.0
#####sink conf
a.sinks.hdfs-sink.type=hdfs
a.sinks.hdfs-sink.hdfs.path=hdfs://h1:9000/flume/events/%Y/%m/%d/%H/%M
a.sinks.hdfs-sink.hdfs.filePrefix=search
a.sinks.hdfs-sink.hdfs.rollInterval=10
a.sinks.hdfs-sink.hdfs.rollSize=0
a.sinks.hdfs-sink.hdfs.useLocalTimeStamp=true
#不设置压缩
#a.sinks.hdfs-sink.hdfs.fileType=DataStream
#a.sinks.hdfs-sink.hdfs.writeFormat=Text
#设置压缩lzo或者snappy
a.sinks.hdfs-sink.hdfs.fileType=CompressedStream
#a.sinks.hdfs-sink.hdfs.codeC=snappy
#a.sinks.hdfs-sink.hdfs.codeC=lzo
#a.sinks.hdfs-sink.hdfs.codeC=lzop
#a.sinks.hdfs-sink.hdfs.codeC=gzip
a.sinks.hdfs-sink.hdfs.codeC=bzip2
####channels conf
a.channels.ch1.type=memory
a.channels.ch1.capacity=1000
a.sources.exec-source.channels=ch1
a.sinks.hdfs-sink.channel=ch1
配置完成启动:
然后看flume的log再次登陆终端,推出终端,sudo命令执行失败,flume都会采集转发到hdfs上存储起来
总结:
Flume不愧是大数据平台的一个标准组件,与Hadoop能非常完美的结合,当然,除了与hadoop结合外,还支持Hbase,Hive等, 相比Logstash+ElasticSearch+Kibana的ELK里面的Logstash,flume比较适合结构化的日志收集,存储,而Logstasch则还可以非常方便的解析,清洗数据,虽然flume通过扩展jar也能支持,但logstash使用的是Jruby语法,相比java,则比较简单。这也是ELK都能够快速部署的原因,当然flume也支持向elasticsearch推送索引数据,通过扩展的jar,几乎大部分功能都能轻松实现,所以,没有谁最好用,谁最不好用,只有谁最适合业务,才是最好的!

相关文章推荐
- 详解HDFS Short Circuit Local Reads
- Hadoop_2.1.0 MapReduce序列图
- 使用Hadoop搭建现代电信企业架构
- 单机版搭建Hadoop环境图文教程详解
- hadoop常见错误以及处理方法详解
- hadoop 单机安装配置教程
- hadoop的hdfs文件操作实现上传文件到hdfs
- hadoop实现grep示例分享
- Flume环境部署和配置详解及案例大全
- Apache Hadoop版本详解
- linux下搭建hadoop环境步骤分享
- hadoop client与datanode的通信协议分析
- hadoop中一些常用的命令介绍
- Hadoop单机版和全分布式(集群)安装
- 用PHP和Shell写Hadoop的MapReduce程序
- hadoop map-reduce中的文件并发操作
- Hadoop1.2中配置伪分布式的实例
- java结合HADOOP集群文件上传下载
- 让python在hadoop上跑起来
- 用python + hadoop streaming 分布式编程(一) -- 原理介绍,样例程序与本地调试