Hadoop 1.x 伪分布式安装部署
2016-02-24 21:04
441 查看
1、介绍
Hadoop将所有进程运行于同一台主机上,此时Hadoop将使用分布式文件系统,而且各jobs也是由JobTracker服务管理的独立进程。伪分布式的Hadoop集群只有一个节点,因此HDFS的块复制将限制为单个副本,其secondary-master和slaves也将运行于本地主机。
2、安装准备
a) 关闭防火墙和禁用SELinuxi. 防火墙:service iptables stop
ii. SELinux:vim /etc/sysconfig/selinux,设置SELINUX=disabled
b) 设置静态IP
设置:vim /etc/sysconfig/network-scripts/ifcfg-eth0
c) 设置hostname
设置:vim /etc/sysconfig/network
d) 设置IP与hostname绑定
设置:vim /etc/hosts
127.0.0.1 localhost
192.168.1.180hadoop-master.dragon.org hadoop-master
e) 设置SSH自动登录
所有守护进程彼此通过SSH协议进行通信。
ssh-keygen -t rsa cp ~/.ssh/id_rsa.pub~/.ssh/authorized_keys进行验证
ssh localhost结果会在.ssh目录下产生known_hosts文件,如下图:
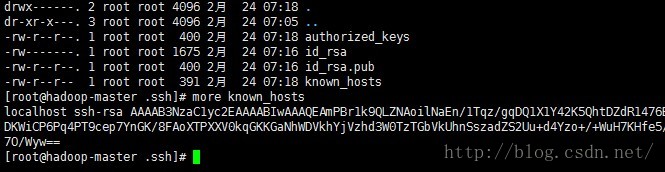
ssh hadoop-master

查看known_hosts,如下图,多了部分内容:
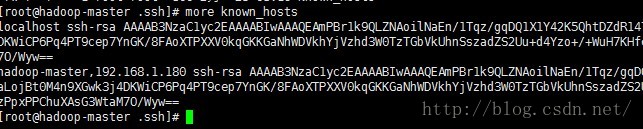
ssh hadoop-master.dragon.org
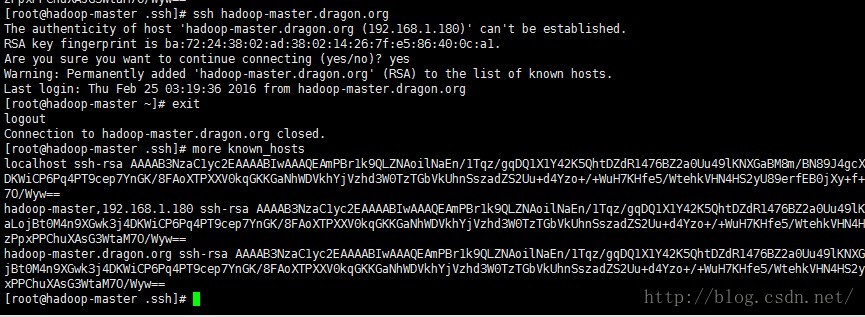
f) 安装jdk
略,见单机版部署
g) 安装hadoop
略,见单机版部署
3、修改配置文件
所有的配置文件,均在目录/opt/modules/hadoop-1.2.1/conf下。a) 配置文件hadoop-env.sh
配置Hadoop的JDK,见单机版部署
b) 配置文件core-site.xml(NameNode)
指定NameNode主机名和端口号
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>fs.default.name</name> <value>hdfs://hadoop-master.dragon.org:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/data/tmp</value> </property> </configuration>
c) 配置文件hdfs-site.xml
设置HDFS的副本数
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration>
d) 配置文件mapred-site.xml
配置JobTracker的主机与端口号
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>mapred.job.tracker</name> <value>hadoop-master.dragon.org:9001</value> </property> </configuration>
e) 配置文件slaves
指定DataNode和TaskTracker的位置
hadoop-master.dragon.org
f) 配置文件masters
指定SecondaryNameNode位置
hadoop-master.dragon.org
4、格式化
进入目录/opt/modules/hadoop-1.2.1/bin执行命令:./hadoop namenode –format
如下图:

5、启动
a) 启动start-dfs.shb) 查看进程jps

可通过页面:http://192.168.1.180:50070/dfshealth.jsp访问
c) 启动MapReduce
执行命令start-mapred.sh

可通过页面http://192.168.1.180:50030/jobtracker.jsp访问。
经过上述步骤,完成了部署,并且NameNode、SecondaryNameNode、DataNode、JobTracker、TaskTracker等进程启动完毕。

相关文章推荐
- 详解HDFS Short Circuit Local Reads
- Hadoop_2.1.0 MapReduce序列图
- 使用Hadoop搭建现代电信企业架构
- 单机版搭建Hadoop环境图文教程详解
- hadoop常见错误以及处理方法详解
- hadoop 单机安装配置教程
- hadoop的hdfs文件操作实现上传文件到hdfs
- hadoop实现grep示例分享
- Apache Hadoop版本详解
- linux下搭建hadoop环境步骤分享
- hadoop client与datanode的通信协议分析
- hadoop中一些常用的命令介绍
- Hadoop单机版和全分布式(集群)安装
- 用PHP和Shell写Hadoop的MapReduce程序
- hadoop map-reduce中的文件并发操作
- Hadoop1.2中配置伪分布式的实例
- java结合HADOOP集群文件上传下载
- 让python在hadoop上跑起来
- 用python + hadoop streaming 分布式编程(一) -- 原理介绍,样例程序与本地调试
- Hadoop安装感悟