系统学习机器学习之增强学习(未完待续)
2016-02-16 10:14
190 查看
参考:
/article/2081386.html
/content/4665912.html
在之前的讨论中,我们总是给定一个样本x,然后给或者不给label y。之后对样本进行拟合、分类、聚类或者降维等操作。然而对于很多序列决策或者控制问题,很难有这么规则的样本。比如,四足机器人的控制问题,刚开始都不知道应该让其动那条腿,在移动过程中,也不知道怎么让机器人自动找到合适的前进方向。
另外如要设计一个下象棋的AI,每走一步实际上也是一个决策过程,虽然对于简单的棋有A*的启发式方法,但在局势复杂时,仍然要让机器向后面多考虑几步后才能决定走哪一步比较好,因此需要更好的决策方法。
对于这种控制决策问题,有这么一种解决思路。我们设计一个回报函数(reward function),如果learning agent(如上面的四足机器人、象棋AI程序)在决定一步后,获得了较好的结果,那么我们给agent一些回报(比如回报函数结果为正),得到较差的结果,那么回报函数为负。比如,四足机器人,如果他向前走了一步(接近目标),那么回报函数为正,后退为负。如果我们能够对每一步进行评价,得到相应的回报函数,那么就好办了,我们只需要找到一条回报值最大的路径(每步的回报之和最大),就认为是最佳的路径。
增强学习在很多领域已经获得成功应用,比如自动直升机,机器人控制,手机网络路由,市场决策,工业控制,高效网页索引等。
补充:
马尔可夫模型的几类子模型
大家应该还记得马尔科夫链(Markov Chain),了解机器学习的也都知道隐马尔可夫模型(Hidden Markov Model,HMM)。它们具有的一个共同性质就是马尔可夫性(无后效性),也就是指系统的下个状态只与当前状态信息有关,而与更早之前的状态无关。
马尔可夫决策过程(Markov Decision Process, MDP)也具有马尔可夫性,与上面不同的是MDP考虑了动作,即系统下个状态不仅和当前的状态有关,也和当前采取的动作有关。还是举下棋的例子,当我们在某个局面(状态s)走了一步(动作a),这时对手的选择(导致下个状态s’)我们是不能确定的,但是他的选择只和s和a有关,而不用考虑更早之前的状态和动作,即s’是根据s和a随机生成的。
我们用一个二维表格表示一下,各种马尔可夫子模型的关系就很清楚了:
接下来,先介绍一下马尔科夫决策过程(MDP,Markov decision processes)。
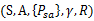
* S表示状态集(states)。(比如,在自动直升机系统中,直升机当前位置坐标组成状态集)
* A表示一组动作(actions)。(比如,使用控制杆操纵的直升机飞行方向,让其向前,向后等)
*
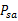
是状态转移概率。S中的一个状态到另一个状态的转变,需要A来参与。
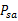
表示的是在当前
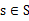
状态下,经过
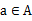
作用后,会转移到的其他状态的概率分布情况(当前状态执行a后可能跳转到很多状态)。
*
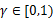
是阻尼系数(discount
factor)
*
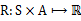
,R是回报函数(reward
function),回报函数经常写作S的函数(只与S有关),这样的话,R重新写作
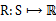
。
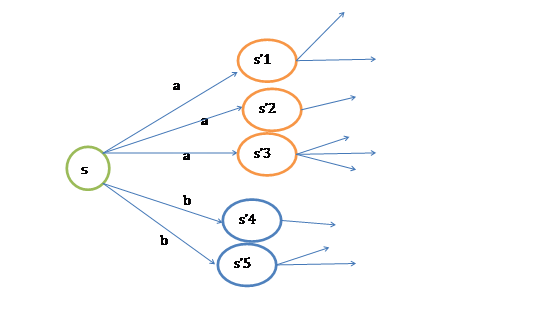
MDP的动态过程如下:某个agent的初始状态为
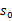
,然后从A中挑选一个动作
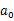
执行,执行后,agent按
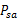
概率随机转移到了下一个
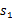
状态,
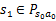
。然后再执行一个动作
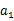
,就转移到了
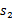
,接下来再执行

…,我们可以用下面的图表示整个过程
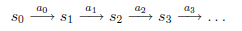
如果对HMM有了解的话,理解起来比较轻松。
我们定义经过上面转移路径后,得到的回报函数之和如下
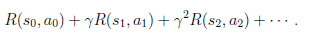
如果R只和S有关,那么上式可以写作
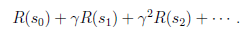
我们的目标是选择一组最佳的action,使得全部的回报加权和期望最大。
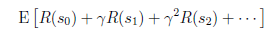
从上式可以发现,在t时刻的回报值被打了
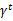
的折扣,是一个逐步衰减的过程,越靠后的状态对回报和影响越小。最大化期望值也就是要将大的
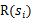
尽量放到前面,小的尽量放到后面。
已经处于某个状态s时,我们会以一定策略
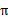
来选择下一个动作a执行,然后转换到另一个状态s’。我们将这个动作的选择过程称为策略(policy),每一个policy其实就是一个状态到动作的映射函数
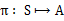
。给定
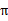
也就给定了
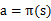
,也就是说,知道了
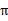
就知道了每个状态下一步应该执行的动作。
我们为了区分不同
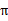
的好坏,并定义在当前状态下,执行某个策略
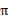
后,出现的结果的好坏,需要定义值函数(value
function)也叫折算累积回报(discounted cumulative reward)
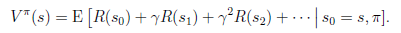
可以看到,在当前状态s下,选择好policy后,值函数是回报加权和期望。这个其实很容易理解,给定
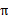
也就给定了一条未来的行动方案,这个行动方案会经过一个个的状态,而到达每个状态都会有一定回报值,距离当前状态越近的其他状态对方案的影响越大,权重越高。这和下象棋差不多,在当前棋局
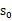
下,不同的走子方案是
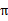
,我们评价每个方案依靠对未来局势(
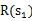
,
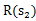
,…)的判断。一般情况下,我们会在头脑中多考虑几步,但是我们会更看重下一步的局势。
从递推的角度上考虑,当期状态s的值函数V,其实可以看作是当前状态的回报R(s)和下一状态的值函数V’之和,也就是将上式变为:
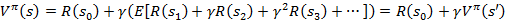
然而,我们需要注意的是虽然给定
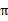
后,在给定状态s下,a是唯一的,但
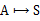
可能不是多到一的映射。比如你选择a为向前投掷一个骰子,那么下一个状态可能有6种。再由Bellman等式,从上式得到
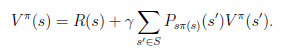
s’表示下一个状态。
前面的R(s)称为立即回报(immediate reward),就是R(当前状态)。第二项也可以写作
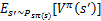
,是下一状态值函数的期望值,下一状态s’符合
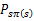
分布。
可以想象,当状态个数有限时,我们可以通过上式来求出每一个s的V(终结状态没有第二项V(s’))。如果列出线性方程组的话,也就是|S|个方程,|S|个未知数,直接求解即可。
当然,我们求V的目的就是想找到一个当前状态s下,最优的行动策略
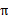
,定义最优的V*如下:
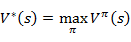
就是从可选的策略
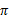
中挑选一个最优的策略(discounted
rewards最大)。
上式的Bellman等式形式如下:
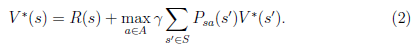
第一项与
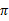
无关,所以不变。第二项是一个
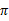
就决定了每个状态s的下一步动作a,执行a后,s’按概率分布的回报概率和的期望。
如果上式还不好理解的话,可以参考下图:
定义了最优的V*,我们再定义最优的策略
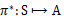
如下:
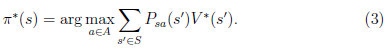
选择最优的
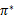
,也就确定了每个状态s的下一步最优动作a。
根据以上式子,我们可以知道
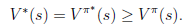
解释一下就是当前状态的最优的值函数V*,是由采用最优执行策略
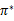
的情况下得出的,采用最优执行方案的回报显然要比采用其他的执行策略
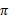
要好。
这里需要注意的是,如果我们能够求得每个s下最优的a,那么从全局来看,
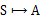
的映射即可生成,而生成的这个映射是最优映射,称为
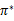
。
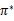
针对全局的s,确定了每一个s的下一个行动a,不会因为初始状态s选取的不同而不同。
补充:
3. 值函数(value function)
上篇我们提到增强学习学到的是一个从环境状态到动作的映射(即行为策略),记为策略π: S→A。而增强学习往往又具有延迟回报的特点: 如果在第n步输掉了棋,那么只有状态sn和动作an获得了立即回报r(sn,an)=-1,前面的所有状态立即回报均为0。所以对于之前的任意状态s和动作a,立即回报函数r(s,a)无法说明策略的好坏。因而需要定义值函数(value
function,又叫效用函数)来表明当前状态下策略π的长期影响。
用Vπ(s)表示策略π下,状态s的值函数。ri表示未来第i步的立即回报,常见的值函数有以下三种:
a)

b)

c)

其中:
a)是采用策略π的情况下未来有限h步的期望立即回报总和;
b)是采用策略π的情况下期望的平均回报;
c)是值函数最常见的形式,式中γ∈[0,1]称为折合因子,表明了未来的回报相对于当前回报的重要程度。特别的,γ=0时,相当于只考虑立即不考虑长期回报,γ=1时,将长期回报和立即回报看得同等重要。接下来我们只讨论第三种形式,
现在将值函数的第三种形式展开,其中ri表示未来第i步回报,s'表示下一步状态,则有:

给定策略π和初始状态s,则动作a=π(s),下个时刻将以概率p(s'|s,a)转向下个状态s',那么上式的期望可以拆开,可以重写为:

上面提到的值函数称为状态值函数(state value function),需要注意的是,在Vπ(s)中,π和初始状态s是我们给定的,而初始动作a是由策略π和状态s决定的,即a=π(s)。
定义动作值函数(action value functionQ函数)如下:

给定当前状态s和当前动作a,在未来遵循策略π,那么系统将以概率p(s'|s,a)转向下个状态s',上式可以重写为:

在Qπ(s,a)中,不仅策略π和初始状态s是我们给定的,当前的动作a也是我们给定的,这是Qπ(s,a)和Vπ(a)的主要区别。
知道值函数的概念后,一个MDP的最优策略可以由下式表示:

即我们寻找的是在任意初始条件s下,能够最大化值函数的策略π*。
4. 值函数与Q函数计算的例子
上面的概念可能描述得不够清晰,接下来我们实际计算一下,如图所示是一个格子世界,我们假设agent从左下角的start点出发,右上角为目标位置,称为吸收状态(Absorbing state),对于进入吸收态的动作,我们给予立即回报100,对其他动作则给予0回报,折合因子γ的值我们选择0.9。
为了方便描述,记第i行,第j列的状态为sij, 在每个状态,有四种上下左右四种可选的动作,分别记为au,ad,al,ar。(up,down,left,right首字母),并认为状态按动作a选择的方向转移的概率为1。

1.由于状态转移概率是1,每组(s,a)对应了唯一的s'。回报函数r(s'|s,a)可以简记为r(s,a)
如下所示,每个格子代表一个状态s,箭头则代表动作a,旁边的数字代表立即回报,可以看到只有进入目标位置的动作获得了回报100,其他动作都获得了0回报。 即r(s12,ar) = r(s23,au) =100。

2. 一个策略π如图所示:

3. 值函数Vπ(s)如下所示

根据Vπ的表达式,立即回报,和策略π,有
Vπ(s12) = r(s12,ar) = r(s13|s12,ar) = 100
Vπ(s11)= r(s11,ar)+γ*Vπ(s12) = 0+0.9*100 = 90
Vπ(s23) = r(s23,au) = 100
Vπ(s22)= r(s22,ar)+γ*Vπ(s23) = 90
Vπ(s21)= r(s21,ar)+γ*Vπ(s22) = 81
4. Q(s,a)值如下所示

有了策略π和立即回报函数r(s,a), Qπ(s,a)如何得到的呢?
对s11计算Q函数(用到了上面Vπ的结果)如下:
Qπ(s11,ar)=r(s11,ar)+ γ *Vπ(s12) =0+0.9*100 = 90
Qπ(s11,ad)=r(s11,ad)+ γ *Vπ(s21) = 72
至此我们了解了马尔可夫决策过程的基本概念,知道了增强学习的目标(获得任意初始条件下,使Vπ值最大的策略π*)。
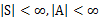
。
* 值迭代法
值迭代策略利用了上节中公式(2)
内循环的实现有两种策略:
1、 同步迭代法
拿初始化后的第一次迭代来说吧,初始状态所有的V(s)都为0。然后对所有的s都计算新的V(s)=R(s)+0=R(s)。在计算每一个状态时,得到新的V(s)后,先存下来,不立即更新。待所有的s的新值V(s)都计算完毕后,再统一更新。
这样,第一次迭代后,V(s)=R(s)。
2、 异步迭代法
与同步迭代对应的就是异步迭代了,对每一个状态s,得到新的V(s)后,不存储,直接更新。这样,第一次迭代后,大部分V(s)>R(s)。
不管使用这两种的哪一种,最终V(s)会收敛到V*(s)。知道了V*后,我们再使用公式(3)来求出相应的最优策略

,当然
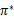
可以在求V*的过程中求出。
* 策略迭代法
值迭代法使V值收敛到V*,而策略迭代法关注
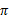
,使
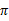
收敛到
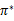
。
(a)步中的V可以通过之前的Bellman等式求得
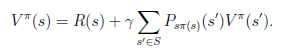
这一步会求出所有状态s的
。
(b)步实际上就是根据(a)步的结果挑选出当前状态s下,最优的a,然后对
做更新。
对于值迭代和策略迭代很难说哪种方法好,哪种不好。对于规模比较小的MDP来说,策略一般能够更快地收敛。但是对于规模很大(状态很多)的MDP来说,值迭代比较容易(不用求线性方程组)。
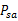
和回报函数R(s)的。但在很多实际问题中,这些参数不能显式得到,我们需要从数据中估计出这些参数(通常S、A和
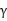
是已知的)。
假设我们已知很多条状态转移路径如下:
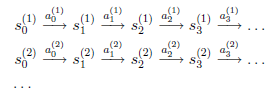
其中,
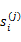
是i时刻,第j条转移路径对应的状态,
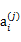
是
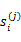
状态时要执行的动作。每个转移路径中状态数是有限的,在实际操作过程中,每个转移链要么进入终结状态,要么达到规定的步数就会终结。
如果我们获得了很多上面类似的转移链(相当于有了样本),那么我们就可以使用最大似然估计来估计状态转移概率。

分子是从s状态执行动作a后到达s’的次数,分母是在状态s时,执行a的次数。两者相除就是在s状态下执行a后,会转移到s’的概率。
为了避免分母为0的情况,我们需要做平滑。如果分母为0,则令
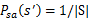
,也就是说当样本中没有出现过在s状态下执行a的样例时,我们认为转移概率均分。
上面这种估计方法是从历史数据中估计,这个公式同样适用于在线更新。比如我们新得到了一些转移路径,那么对上面的公式进行分子分母的修正(加上新得到的count)即可。修正过后,转移概率有所改变,按照改变后的概率,可能出现更多的新的转移路径,这样
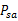
会越来越准。
同样,如果回报函数未知,那么我们认为R(s)为在s状态下已经观测到的回报均值。
当转移概率和回报函数估计出之后,我们可以使用值迭代或者策略迭代来解决MDP问题。比如,我们将参数估计和值迭代结合起来(在不知道状态转移概率情况下)的流程如下:
在(b)步中我们要做值更新,也是一个循环迭代的过程,在上节中,我们通过将V初始化为0,然后进行迭代来求解V。嵌套到上面的过程后,如果每次初始化V为0,然后迭代更新,就会很慢。一个加快速度的方法是每次将V初始化为上一次大循环中得到的V。也就是说V的初值衔接了上次的结果。
x(在铁轨上的位置)
theta(杆的角度)
x’(铁轨上的速度)
thata'(角速度)
/////////////////离散化///////////////////////////
也就是把连续的值分成多个区间,这是很自然的一个想法,比如一个二维的连续区间可以分成如下的离散值:

但是这样做的效果并不好,因为用一个离散的去表示连续空间毕竟是有限的离散值。
离散值不好的另一个原因是因为curse of dimension(维度灾难),因为连续值离散值后会有多个离散值,这样如果维度很大就会造成有非常多状态
从而使需要更多计算,这是随着dimension以指数增长的
//////////////////////simulator方法///////////////////////////////
也就是说假设我们有一个simulator,输入一个状态s和一个操作a可以输出下一个状态,并且下一个状态是服从MDP中的概率Psa的分布,即:

这样我们就把状态变成连续的了,但是如何得到这样一个simulator呢?
①:根据客观事实
比如说上面的inverted pendulum问题,action就是作用在小车上的水平力,根据物理上的知识,完全可以解出这个加速度对状态的影响
也就是算出该力对于小车的水平加速度和杆的角加速度,再去一个比较小的时间间隔,就可以得到S(t+1)了
②:学习一个simulator
这个部分,首先你可以自己尝试控制小车,得到一系列的数据,假设力是线性的或者非线性的,将S(t+1)看作关于S(t)和a(t)的一个函数
得到这些数据之后,你可以通过一个supervised learning来得到这个函数,其实就是得到了simulator了。
比如我们假设这是一个线性的函数:

在inverted pendulum问题中,A就是一个4*4的矩阵,B就是一个4维向量,再加上一点噪音,就变成了:其中噪音服从


我们的任务就是要学习到A和B
(这里只是假设线性的,更具体的,如果我们假设是非线性的,比如说加一个feature是速度和角速度的乘积,或者平方,或者其他,上式还可以写作:)

这样就是非线性的了,我们的任务就是得到A和B,用一个supervised learning分别拟合每个参数就可以了
在之前我们的value iteration算法中,我们有:

这里使用了期望的定义而转化。fitted value(Q) iteration算法的主要思想就是用一个参数去逼近右边的这个式子
也就是说:令

其中

是一些基于s的参数,我们需要去得到系数

的值,先给出算法步骤再一步步解释吧:

算法步骤其实很简单,最主要的其实就是他的思想:
在对于action的那个循环里,我们尝试得到这个action所对应的

,记作q(a)
这里的q(a)都是对应第i个样例的情况
然后i=1……m的那个循环是得到是最优的action对应的Value值,记作y(i),然后用y(i)拿去做supervised learning,大概就是这样一个思路
至于reward函数就比较简单了,比如说在inverted pendulum问题中,杆子比较直立就是给高reward,这个可以很直观地从状态得到衡量奖励的方法
在有了之上的东西之后,我们就可以去算我们的policy了:

如果在一个确定性模型中,其实是一个简化的问题,得到的样例简化了,计算也简化了
也就是说一个对于一个状态和一个动作,只能到达另一个状态,而不是多个,特例就不细讲了
开始讲了如何求解含有T时间的策略方程。知道V*(T)是容易的,让后通过逆推的动态规划函数就可以解出。但是,有时间的策略方程,因为是有关于st和s(t+1)之间关系的,因此,也需要进行线性拟合,这个在之前已经讲过,这里不再赘述。有s(t+1)=As(t)+Balpha(t)。但是,这里的逆推在一些特殊情况下将会有非常高的效率。
1.reward函数的选取,假设可以表示为Rt+1(st,at)=-st'utst-at'vtat的形式等等,那么最终,可以迅速通过公式得到时间t状态下应该对应的策略。
实际上,就是假设:
,其中噪声项服从高斯分布,不是很重要。
但同时假设了边界时间,二次奖励函数。
那么如何求解最优策略呢?基本的解法有三种:
动态规划法(dynamic programming methods)
蒙特卡罗方法(Monte Carlo methods)
时间差分法(temporal difference)。
动态规划法是其中最基本的算法,也是理解后续算法的基础,因此本文先介绍动态规划法求解MDP。本文假设拥有MDP模型M=(S, A, Psa, R)的完整知识。
1. 贝尔曼方程(Bellman Equation)
上一篇我们得到了Vπ和Qπ的表达式,并且写成了如下的形式

在动态规划中,上面两个式子称为贝尔曼方程,它表明了当前状态的值函数与下个状态的值函数的关系。
优化目标π*可以表示为:

分别记最优策略π*对应的状态值函数和行为值函数为V*(s)和Q*(s, a),由它们的定义容易知道,V*(s)和Q*(s, a)存在如下关系:

状态值函数和行为值函数分别满足如下贝尔曼最优性方程(Bellman optimality equation):


有了贝尔曼方程和贝尔曼最优性方程后,我们就可以用动态规划来求解MDP了。
2. 策略估计(Policy Evaluation)
首先,对于任意的策略π,我们如何计算其状态值函数Vπ(s)?这个问题被称作策略估计,
前面讲到对于确定性策略,值函数

现在扩展到更一般的情况,如果在某策略π下,π(s)对应的动作a有多种可能,每种可能记为π(a|s),则状态值函数定义如下:

一般采用迭代的方法更新状态值函数,首先将所有Vπ(s)的初值赋为0(其他状态也可以赋为任意值,不过吸收态必须赋0值),然后采用如下式子更新所有状态s的值函数(第k+1次迭代):

对于Vπ(s),有两种更新方法,
第一种:将第k次迭代的各状态值函数[Vk(s1),Vk(s2),Vk(s3)..]保存在一个数组中,第k+1次的Vπ(s)采用第k次的Vπ(s')来计算,并将结果保存在第二个数组中。
第二种:即仅用一个数组保存各状态值函数,每当得到一个新值,就将旧的值覆盖,形如[Vk+1(s1),Vk+1(s2),Vk(s3)..],第k+1次迭代的Vπ(s)可能用到第k+1次迭代得到的Vπ(s')。
通常情况下,我们采用第二种方法更新数据,因为它及时利用了新值,能更快的收敛。整个策略估计算法如下图所示:

3. 策略改进(Policy Improvement)
上一节中进行策略估计的目的,是为了寻找更好的策略,这个过程叫做策略改进(Policy Improvement)。
假设我们有一个策略π,并且确定了它的所有状态的值函数Vπ(s)。对于某状态s,有动作a0=π(s)。 那么如果我们在状态s下不采用动作a0,而采用其他动作a≠π(s)是否会更好呢?要判断好坏就需要我们计算行为值函数Qπ(s,a),公式我们前面已经说过:

评判标准是:Qπ(s,a)是否大于Vπ(s)。如果Qπ(s,a)> Vπ(s),那么至少说明新策略【仅在状态s下采用动作a,其他状态下遵循策略π】比旧策略【所有状态下都遵循策略π】整体上要更好。
策略改进定理(policy improvement theorem):π和π'是两个确定的策略,如果对所有状态s∈S有Qπ(s,π'(s))≥Vπ(s),那么策略π'必然比策略π更好,或者至少一样好。其中的不等式等价于Vπ'(s)≥Vπ(s)。
有了在某状态s上改进策略的方法和策略改进定理,我们可以遍历所有状态和所有可能的动作a,并采用贪心策略来获得新策略π'。即对所有的s∈S, 采用下式更新策略:

这种采用关于值函数的贪心策略获得新策略,改进旧策略的过程,称为策略改进(Policy Improvement)
最后大家可能会疑惑,贪心策略能否收敛到最优策略,这里我们假设策略改进过程已经收敛,即对所有的s,Vπ'(s)等于Vπ(s)。那么根据上面的策略更新的式子,可以知道对于所有的s∈S下式成立:

可是这个式子正好就是我们在1中所说的Bellman optimality equation,所以π和π'都必然是最优策略!神奇吧!
4. 策略迭代(Policy Iteration)
策略迭代算法就是上面两节内容的组合。假设我们有一个策略π,那么我们可以用policy evaluation获得它的值函数Vπ(s),然后根据policy improvement得到更好的策略π',接着再计算Vπ'(s),再获得更好的策略π'',整个过程顺序进行如下图所示:

完整的算法如下图所示:

5. 值迭代(Value Iteration)
从上面我们可以看到,策略迭代算法包含了一个策略估计的过程,而策略估计则需要扫描(sweep)所有的状态若干次,其中巨大的计算量直接影响了策略迭代算法的效率。我们必须要获得精确的Vπ值吗?事实上不必,有几种方法可以在保证算法收敛的情况下,缩短策略估计的过程。
值迭代(Value Iteration)就是其中非常重要的一种。它的每次迭代只扫描(sweep)了每个状态一次。值迭代的每次迭代对所有的s∈S按照下列公式更新:

即在值迭代的第k+1次迭代时,直接将能获得的最大的Vπ(s)值赋给Vk+1。值迭代算法直接用可能转到的下一步s'的V(s')来更新当前的V(s),算法甚至都不需要存储策略π。而实际上这种更新方式同时却改变了策略πk和V(s)的估值Vk(s)。 直到算法结束后,我们再通过V值来获得最优的π。
此外,值迭代还可以理解成是采用迭代的方式逼近1中所示的贝尔曼最优方程。
值迭代完整的算法如图所示:

由上面的算法可知,值迭代的最后一步,我们才根据V*(s),获得最优策略π*。
一般来说值迭代和策略迭代都需要经过无数轮迭代才能精确的收敛到V*和π*, 而实践中,我们往往设定一个阈值来作为中止条件,即当Vπ(s)值改变很小时,我们就近似的认为获得了最优策略。在折扣回报的有限MDP(discounted finite MDPs)中,进过有限次迭代,两种算法都能收敛到最优策略π*。
至此我们了解了马尔可夫决策过程的动态规划解法,动态规划的优点在于它有很好的数学上的解释,但是动态要求一个完全已知的环境模型,这在现实中是很难做到的。另外,当状态数量较大的时候,动态规划法的效率也将是一个问题。下一篇介绍蒙特卡罗方法,它的优点在于不需要完整的环境模型。
PS: 如果什么没讲清楚的地方,欢迎提出,我会补充说明...
参考资料:
[1] R.Sutton et al. Reinforcement learning: An introduction , 1998
[2] 徐昕,增强学习及其在移动机器人导航与控制中的应用研究[D],2002
1. 蒙特卡罗方法的基本思想
蒙特卡罗方法又叫统计模拟方法,它使用随机数(或伪随机数)来解决计算的问题,是一类重要的数值计算方法。该方法的名字来源于世界著名的赌城蒙特卡罗,而蒙特卡罗方法正是以概率为基础的方法。
一个简单的例子可以解释蒙特卡罗方法,假设我们需要计算一个不规则图形的面积,那么图形的不规则程度和分析性计算(比如积分)的复杂程度是成正比的。而采用蒙特卡罗方法是怎么计算的呢?首先你把图形放到一个已知面积的方框内,然后假想你有一些豆子,把豆子均匀地朝这个方框内撒,散好后数这个图形之中有多少颗豆子,再根据图形内外豆子的比例来计算面积。当你的豆子越小,撒的越多的时候,结果就越精确。
2. 增强学习中的蒙特卡罗方法
现在我们开始讲解增强学习中的蒙特卡罗方法,与上篇的DP不同的是,这里不需要对环境的完整知识。蒙特卡罗方法仅仅需要经验就可以求解最优策略,这些经验可以在线获得或者根据某种模拟机制获得。
要注意的是,我们仅将蒙特卡罗方法定义在episode task上,所谓的episode task就是指不管采取哪种策略π,都会在有限时间内到达终止状态并获得回报的任务。比如玩棋类游戏,在有限步数以后总能达到输赢或者平局的结果并获得相应回报。
那么什么是经验呢?经验其实就是训练样本。比如在初始状态s,遵循策略π,最终获得了总回报R,这就是一个样本。如果我们有许多这样的样本,就可以估计在状态s下,遵循策略π的期望回报,也就是状态值函数Vπ(s)了。蒙特卡罗方法就是依靠样本的平均回报来解决增强学习问题的。
尽管蒙特卡罗方法和动态规划方法存在诸多不同,但是蒙特卡罗方法借鉴了很多动态规划中的思想。在动态规划中我们首先进行策略估计,计算特定策略π对应的Vπ和Qπ,然后进行策略改进,最终形成策略迭代。这些想法同样在蒙特卡罗方法中应用。
3. 蒙特卡罗策略估计(Monte Carlo Policy evalution)
首先考虑用蒙特卡罗方法来学习状态值函数Vπ(s)。如上所述,估计Vπ(s)的一个明显的方法是对于所有到达过该状态的回报取平均值。这里又分为first-visit MC methods和every-visit MC methods。这里,我们只考虑first MC methods,即在一个episode内,我们只记录s的第一次访问,并对它取平均回报。
现在我们假设有如下一些样本,取折扣因子γ=1,即直接计算累积回报,则有

根据first MC methods,对出现过状态s的episode的累积回报取均值,有Vπ(s)≈ (2 + 1 – 5 + 4)/4 = 0.5
容易知道,当我们经过无穷多的episode后,Vπ(s)的估计值将收敛于其真实值。
4. 动作值函数的MC估计(Mote Carlo Estimation of Action Values)
在状态转移概率p(s'|a,s)已知的情况下,策略估计后有了新的值函数,我们就可以进行策略改进了,只需要看哪个动作能获得最大的期望累积回报就可以。然而在没有准确的状态转移概率的情况下这是不可行的。为此,我们需要估计动作值函数Qπ(s,a)。Qπ(s,a)的估计方法前面类似,即在状态s下采用动作a,后续遵循策略π获得的期望累积回报即为Qπ(s,a),依然用平均回报来估计它。有了Q值,就可以进行策略改进了

5. 持续探索(Maintaining Exploration)
下面我们来探讨一下Maintaining Exploration的问题。前面我们讲到,我们通过一些样本来估计Q和V,并且在未来执行估值最大的动作。这里就存在一个问题,假设在某个确定状态s0下,能执行a0, a1, a2这三个动作,如果智能体已经估计了两个Q函数值,如Q(s0,a0), Q(s0,a1),且Q(s0,a0)>Q(s0,a1),那么它在未来将只会执行一个确定的动作a0。这样我们就无法更新Q(s0,a1)的估值和获得Q(s0,a2)的估值了。这样的后果是,我们无法保证Q(s0,a0)就是s0下最大的Q函数。
Maintaining Exploration的思想很简单,就是用soft policies来替换确定性策略,使所有的动作都有可能被执行。比如其中的一种方法是ε-greedy policy,即在所有的状态下,用1-ε的概率来执行当前的最优动作a0,ε的概率来执行其他动作a1, a2。这样我们就可以获得所有动作的估计值,然后通过慢慢减少ε值,最终使算法收敛,并得到最优策略。简单起见,在下面MC控制中,我们使用exploring
start,即仅在第一步令所有的a都有一个非零的概率被选中。
6. 蒙特卡罗控制(Mote Carlo Control)
我们看下MC版本的策略迭代过程:

根据前面的说法,值函数Qπ(s,a)的估计值需要在无穷多episode后才能收敛到其真实值。这样的话策略迭代必然是低效的。在上一篇DP中,我们了值迭代算法,即每次都不用完整的策略估计,而仅仅使用值函数的近似值进行迭代,这里也用到了类似的思想。每次策略的近似值,然后用这个近似值来更新得到一个近似的策略,并最终收敛到最优策略。这个思想称为广义策略迭代。

具体到MC control,就是在每个episode后都重新估计下动作值函数(尽管不是真实值),然后根据近似的动作值函数,进行策略更新。这是一个episode by episode的过程。
一个采用exploring starts的Monte Carlo control算法,如下图所示,称为Monte Carlo ES。而对于所有状态都采用soft policy的版本,这里不再讨论。

7. 小结
Monte Carlo方法的一个显而易见的好处就是我们不需要环境模型了,可以从经验中直接学到策略。它的另一个好处是,它对所有状态s的估计都是独立的,而不依赖与其他状态的值函数。在很多时候,我们不需要对所有状态值进行估计,这种情况下蒙特卡罗方法就十分适用。
不过,现在增强学习中,直接使用MC方法的情况比较少,而较多的采用TD算法族。但是如同DP一样,MC方法也是增强学习的基础之一,因此依然有学习的必要。
参考资料:
[1] R.Sutton et al. Reinforcement learning: An introduction, 1998
[2] Wikipedia,蒙特卡罗方法
整个吴恩达机器学习视频的学习,到此为一个节点,由于强化学习部分,跟当前工作无关,因此,理解的不够透彻,后面几节课,都是跳着看的。以后有机会进入机器人算法研究再深入理解。
截止目前,整合网上各位大神的笔记,以及《机器学习导论》,吴恩达《机器学习课程》视频等资料,算是对机器学习算法的一个系统入门吧。接下来,针对工作内容,在相关领域做深入研究,时刻记住,自己是一位工程师,解决实际问题,才是硬道理。
OK
2016/2/17
/article/2081386.html
/content/4665912.html
在之前的讨论中,我们总是给定一个样本x,然后给或者不给label y。之后对样本进行拟合、分类、聚类或者降维等操作。然而对于很多序列决策或者控制问题,很难有这么规则的样本。比如,四足机器人的控制问题,刚开始都不知道应该让其动那条腿,在移动过程中,也不知道怎么让机器人自动找到合适的前进方向。
另外如要设计一个下象棋的AI,每走一步实际上也是一个决策过程,虽然对于简单的棋有A*的启发式方法,但在局势复杂时,仍然要让机器向后面多考虑几步后才能决定走哪一步比较好,因此需要更好的决策方法。
对于这种控制决策问题,有这么一种解决思路。我们设计一个回报函数(reward function),如果learning agent(如上面的四足机器人、象棋AI程序)在决定一步后,获得了较好的结果,那么我们给agent一些回报(比如回报函数结果为正),得到较差的结果,那么回报函数为负。比如,四足机器人,如果他向前走了一步(接近目标),那么回报函数为正,后退为负。如果我们能够对每一步进行评价,得到相应的回报函数,那么就好办了,我们只需要找到一条回报值最大的路径(每步的回报之和最大),就认为是最佳的路径。
增强学习在很多领域已经获得成功应用,比如自动直升机,机器人控制,手机网络路由,市场决策,工业控制,高效网页索引等。
补充:
马尔可夫模型的几类子模型
大家应该还记得马尔科夫链(Markov Chain),了解机器学习的也都知道隐马尔可夫模型(Hidden Markov Model,HMM)。它们具有的一个共同性质就是马尔可夫性(无后效性),也就是指系统的下个状态只与当前状态信息有关,而与更早之前的状态无关。
马尔可夫决策过程(Markov Decision Process, MDP)也具有马尔可夫性,与上面不同的是MDP考虑了动作,即系统下个状态不仅和当前的状态有关,也和当前采取的动作有关。还是举下棋的例子,当我们在某个局面(状态s)走了一步(动作a),这时对手的选择(导致下个状态s’)我们是不能确定的,但是他的选择只和s和a有关,而不用考虑更早之前的状态和动作,即s’是根据s和a随机生成的。
我们用一个二维表格表示一下,各种马尔可夫子模型的关系就很清楚了:
| 不考虑动作 | 考虑动作 | |
| 状态完全可见 | 马尔科夫链(MC) | 马尔可夫决策过程(MDP) |
| 状态不完全可见 | 隐马尔可夫模型(HMM) | 不完全可观察马尔可夫决策过程(POMDP) |
1. 马尔科夫决策过程
一个马尔科夫决策过程由一个五元组构成
* S表示状态集(states)。(比如,在自动直升机系统中,直升机当前位置坐标组成状态集)
* A表示一组动作(actions)。(比如,使用控制杆操纵的直升机飞行方向,让其向前,向后等)
*
是状态转移概率。S中的一个状态到另一个状态的转变,需要A来参与。

表示的是在当前
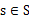
状态下,经过
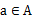
作用后,会转移到的其他状态的概率分布情况(当前状态执行a后可能跳转到很多状态)。
*
是阻尼系数(discount
factor)
*
,R是回报函数(reward
function),回报函数经常写作S的函数(只与S有关),这样的话,R重新写作

。
MDP的动态过程如下:某个agent的初始状态为

,然后从A中挑选一个动作
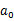
执行,执行后,agent按
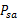
概率随机转移到了下一个
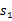
状态,
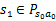
。然后再执行一个动作
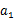
,就转移到了

,接下来再执行

…,我们可以用下面的图表示整个过程
如果对HMM有了解的话,理解起来比较轻松。
我们定义经过上面转移路径后,得到的回报函数之和如下
如果R只和S有关,那么上式可以写作
我们的目标是选择一组最佳的action,使得全部的回报加权和期望最大。
从上式可以发现,在t时刻的回报值被打了
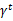
的折扣,是一个逐步衰减的过程,越靠后的状态对回报和影响越小。最大化期望值也就是要将大的
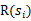
尽量放到前面,小的尽量放到后面。
已经处于某个状态s时,我们会以一定策略

来选择下一个动作a执行,然后转换到另一个状态s’。我们将这个动作的选择过程称为策略(policy),每一个policy其实就是一个状态到动作的映射函数

。给定

也就给定了
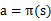
,也就是说,知道了
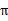
就知道了每个状态下一步应该执行的动作。
我们为了区分不同
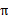
的好坏,并定义在当前状态下,执行某个策略
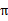
后,出现的结果的好坏,需要定义值函数(value
function)也叫折算累积回报(discounted cumulative reward)
可以看到,在当前状态s下,选择好policy后,值函数是回报加权和期望。这个其实很容易理解,给定
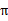
也就给定了一条未来的行动方案,这个行动方案会经过一个个的状态,而到达每个状态都会有一定回报值,距离当前状态越近的其他状态对方案的影响越大,权重越高。这和下象棋差不多,在当前棋局
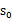
下,不同的走子方案是

,我们评价每个方案依靠对未来局势(

,
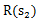
,…)的判断。一般情况下,我们会在头脑中多考虑几步,但是我们会更看重下一步的局势。
从递推的角度上考虑,当期状态s的值函数V,其实可以看作是当前状态的回报R(s)和下一状态的值函数V’之和,也就是将上式变为:
然而,我们需要注意的是虽然给定
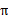
后,在给定状态s下,a是唯一的,但
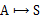
可能不是多到一的映射。比如你选择a为向前投掷一个骰子,那么下一个状态可能有6种。再由Bellman等式,从上式得到
s’表示下一个状态。
前面的R(s)称为立即回报(immediate reward),就是R(当前状态)。第二项也可以写作
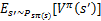
,是下一状态值函数的期望值,下一状态s’符合
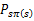
分布。
可以想象,当状态个数有限时,我们可以通过上式来求出每一个s的V(终结状态没有第二项V(s’))。如果列出线性方程组的话,也就是|S|个方程,|S|个未知数,直接求解即可。
当然,我们求V的目的就是想找到一个当前状态s下,最优的行动策略

,定义最优的V*如下:
就是从可选的策略
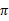
中挑选一个最优的策略(discounted
rewards最大)。
上式的Bellman等式形式如下:
第一项与

无关,所以不变。第二项是一个
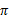
就决定了每个状态s的下一步动作a,执行a后,s’按概率分布的回报概率和的期望。
如果上式还不好理解的话,可以参考下图:
定义了最优的V*,我们再定义最优的策略
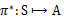
如下:
选择最优的
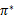
,也就确定了每个状态s的下一步最优动作a。
根据以上式子,我们可以知道
解释一下就是当前状态的最优的值函数V*,是由采用最优执行策略
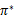
的情况下得出的,采用最优执行方案的回报显然要比采用其他的执行策略
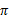
要好。
这里需要注意的是,如果我们能够求得每个s下最优的a,那么从全局来看,
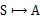
的映射即可生成,而生成的这个映射是最优映射,称为

。
针对全局的s,确定了每一个s的下一个行动a,不会因为初始状态s选取的不同而不同。
补充:
3. 值函数(value function)
上篇我们提到增强学习学到的是一个从环境状态到动作的映射(即行为策略),记为策略π: S→A。而增强学习往往又具有延迟回报的特点: 如果在第n步输掉了棋,那么只有状态sn和动作an获得了立即回报r(sn,an)=-1,前面的所有状态立即回报均为0。所以对于之前的任意状态s和动作a,立即回报函数r(s,a)无法说明策略的好坏。因而需要定义值函数(value
function,又叫效用函数)来表明当前状态下策略π的长期影响。
用Vπ(s)表示策略π下,状态s的值函数。ri表示未来第i步的立即回报,常见的值函数有以下三种:
a)
b)
c)
其中:
a)是采用策略π的情况下未来有限h步的期望立即回报总和;
b)是采用策略π的情况下期望的平均回报;
c)是值函数最常见的形式,式中γ∈[0,1]称为折合因子,表明了未来的回报相对于当前回报的重要程度。特别的,γ=0时,相当于只考虑立即不考虑长期回报,γ=1时,将长期回报和立即回报看得同等重要。接下来我们只讨论第三种形式,
现在将值函数的第三种形式展开,其中ri表示未来第i步回报,s'表示下一步状态,则有:
给定策略π和初始状态s,则动作a=π(s),下个时刻将以概率p(s'|s,a)转向下个状态s',那么上式的期望可以拆开,可以重写为:
上面提到的值函数称为状态值函数(state value function),需要注意的是,在Vπ(s)中,π和初始状态s是我们给定的,而初始动作a是由策略π和状态s决定的,即a=π(s)。
定义动作值函数(action value functionQ函数)如下:
给定当前状态s和当前动作a,在未来遵循策略π,那么系统将以概率p(s'|s,a)转向下个状态s',上式可以重写为:
在Qπ(s,a)中,不仅策略π和初始状态s是我们给定的,当前的动作a也是我们给定的,这是Qπ(s,a)和Vπ(a)的主要区别。
知道值函数的概念后,一个MDP的最优策略可以由下式表示:
即我们寻找的是在任意初始条件s下,能够最大化值函数的策略π*。
4. 值函数与Q函数计算的例子
上面的概念可能描述得不够清晰,接下来我们实际计算一下,如图所示是一个格子世界,我们假设agent从左下角的start点出发,右上角为目标位置,称为吸收状态(Absorbing state),对于进入吸收态的动作,我们给予立即回报100,对其他动作则给予0回报,折合因子γ的值我们选择0.9。
为了方便描述,记第i行,第j列的状态为sij, 在每个状态,有四种上下左右四种可选的动作,分别记为au,ad,al,ar。(up,down,left,right首字母),并认为状态按动作a选择的方向转移的概率为1。
1.由于状态转移概率是1,每组(s,a)对应了唯一的s'。回报函数r(s'|s,a)可以简记为r(s,a)
如下所示,每个格子代表一个状态s,箭头则代表动作a,旁边的数字代表立即回报,可以看到只有进入目标位置的动作获得了回报100,其他动作都获得了0回报。 即r(s12,ar) = r(s23,au) =100。
2. 一个策略π如图所示:
3. 值函数Vπ(s)如下所示
根据Vπ的表达式,立即回报,和策略π,有
Vπ(s12) = r(s12,ar) = r(s13|s12,ar) = 100
Vπ(s11)= r(s11,ar)+γ*Vπ(s12) = 0+0.9*100 = 90
Vπ(s23) = r(s23,au) = 100
Vπ(s22)= r(s22,ar)+γ*Vπ(s23) = 90
Vπ(s21)= r(s21,ar)+γ*Vπ(s22) = 81
4. Q(s,a)值如下所示
有了策略π和立即回报函数r(s,a), Qπ(s,a)如何得到的呢?
对s11计算Q函数(用到了上面Vπ的结果)如下:
Qπ(s11,ar)=r(s11,ar)+ γ *Vπ(s12) =0+0.9*100 = 90
Qπ(s11,ad)=r(s11,ad)+ γ *Vπ(s21) = 72
至此我们了解了马尔可夫决策过程的基本概念,知道了增强学习的目标(获得任意初始条件下,使Vπ值最大的策略π*)。
2. 值迭代和策略迭代法
上节我们给出了迭代公式和优化目标,这节讨论两种求解有限状态MDP具体策略的有效算法。这里,我们只针对MDP是有限状态、有限动作的情况,
。
* 值迭代法
| 1、 将每一个s的V(s)初始化为0 2、 循环直到收敛 { 对于每一个状态s,对V(s)做更新  } |
内循环的实现有两种策略:
1、 同步迭代法
拿初始化后的第一次迭代来说吧,初始状态所有的V(s)都为0。然后对所有的s都计算新的V(s)=R(s)+0=R(s)。在计算每一个状态时,得到新的V(s)后,先存下来,不立即更新。待所有的s的新值V(s)都计算完毕后,再统一更新。
这样,第一次迭代后,V(s)=R(s)。
2、 异步迭代法
与同步迭代对应的就是异步迭代了,对每一个状态s,得到新的V(s)后,不存储,直接更新。这样,第一次迭代后,大部分V(s)>R(s)。
不管使用这两种的哪一种,最终V(s)会收敛到V*(s)。知道了V*后,我们再使用公式(3)来求出相应的最优策略
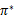
,当然

可以在求V*的过程中求出。
* 策略迭代法
值迭代法使V值收敛到V*,而策略迭代法关注
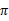
,使
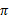
收敛到

。
1、 将随机指定一个S到A的映射 。 2、 循环直到收敛 { (a) 令 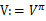 (b) 对于每一个状态s,对 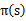 做更新 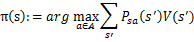 } |
这一步会求出所有状态s的

。
(b)步实际上就是根据(a)步的结果挑选出当前状态s下,最优的a,然后对
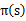
做更新。
对于值迭代和策略迭代很难说哪种方法好,哪种不好。对于规模比较小的MDP来说,策略一般能够更快地收敛。但是对于规模很大(状态很多)的MDP来说,值迭代比较容易(不用求线性方程组)。
3. MDP中的参数估计
在之前讨论的MDP中,我们是已知状态转移概率
和回报函数R(s)的。但在很多实际问题中,这些参数不能显式得到,我们需要从数据中估计出这些参数(通常S、A和
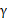
是已知的)。
假设我们已知很多条状态转移路径如下:
其中,
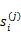
是i时刻,第j条转移路径对应的状态,
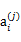
是
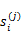
状态时要执行的动作。每个转移路径中状态数是有限的,在实际操作过程中,每个转移链要么进入终结状态,要么达到规定的步数就会终结。
如果我们获得了很多上面类似的转移链(相当于有了样本),那么我们就可以使用最大似然估计来估计状态转移概率。
分子是从s状态执行动作a后到达s’的次数,分母是在状态s时,执行a的次数。两者相除就是在s状态下执行a后,会转移到s’的概率。
为了避免分母为0的情况,我们需要做平滑。如果分母为0,则令
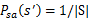
,也就是说当样本中没有出现过在s状态下执行a的样例时,我们认为转移概率均分。
上面这种估计方法是从历史数据中估计,这个公式同样适用于在线更新。比如我们新得到了一些转移路径,那么对上面的公式进行分子分母的修正(加上新得到的count)即可。修正过后,转移概率有所改变,按照改变后的概率,可能出现更多的新的转移路径,这样

会越来越准。
同样,如果回报函数未知,那么我们认为R(s)为在s状态下已经观测到的回报均值。
当转移概率和回报函数估计出之后,我们可以使用值迭代或者策略迭代来解决MDP问题。比如,我们将参数估计和值迭代结合起来(在不知道状态转移概率情况下)的流程如下:
1、 随机初始化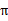 2、 循环直到收敛 { (a) 在样本上统计  中每个状态转移次数,用来更新  和R (b) 使用估计到的参数来更新V(使用上节的值迭代方法) (c) 根据更新的V来重新得出 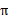 } |
4.连续状态的MDP
之前我们的状态都是离散的,如果状态是连续的,下面将用一个例子来予以说明,这个例子就是inverted pendulum问题,也就是一个铁轨小车上有一个长杆,要用计算机来让它保持平衡(其实就是我们平时玩杆子,放在手上让它一直保持竖直状态),这个问题需要的状态有:都是real的值x(在铁轨上的位置)
theta(杆的角度)
x’(铁轨上的速度)
thata'(角速度)
/////////////////离散化///////////////////////////
也就是把连续的值分成多个区间,这是很自然的一个想法,比如一个二维的连续区间可以分成如下的离散值:
但是这样做的效果并不好,因为用一个离散的去表示连续空间毕竟是有限的离散值。
离散值不好的另一个原因是因为curse of dimension(维度灾难),因为连续值离散值后会有多个离散值,这样如果维度很大就会造成有非常多状态
从而使需要更多计算,这是随着dimension以指数增长的
//////////////////////simulator方法///////////////////////////////
也就是说假设我们有一个simulator,输入一个状态s和一个操作a可以输出下一个状态,并且下一个状态是服从MDP中的概率Psa的分布,即:
这样我们就把状态变成连续的了,但是如何得到这样一个simulator呢?
①:根据客观事实
比如说上面的inverted pendulum问题,action就是作用在小车上的水平力,根据物理上的知识,完全可以解出这个加速度对状态的影响
也就是算出该力对于小车的水平加速度和杆的角加速度,再去一个比较小的时间间隔,就可以得到S(t+1)了
②:学习一个simulator
这个部分,首先你可以自己尝试控制小车,得到一系列的数据,假设力是线性的或者非线性的,将S(t+1)看作关于S(t)和a(t)的一个函数
得到这些数据之后,你可以通过一个supervised learning来得到这个函数,其实就是得到了simulator了。
比如我们假设这是一个线性的函数:
在inverted pendulum问题中,A就是一个4*4的矩阵,B就是一个4维向量,再加上一点噪音,就变成了:其中噪音服从
我们的任务就是要学习到A和B
(这里只是假设线性的,更具体的,如果我们假设是非线性的,比如说加一个feature是速度和角速度的乘积,或者平方,或者其他,上式还可以写作:)
这样就是非线性的了,我们的任务就是得到A和B,用一个supervised learning分别拟合每个参数就可以了
5.连续状态中得Value(Q)函数
这里介绍了一个fitted value(Q) iteration的算法在之前我们的value iteration算法中,我们有:
这里使用了期望的定义而转化。fitted value(Q) iteration算法的主要思想就是用一个参数去逼近右边的这个式子
也就是说:令
其中
是一些基于s的参数,我们需要去得到系数
的值,先给出算法步骤再一步步解释吧:
算法步骤其实很简单,最主要的其实就是他的思想:
在对于action的那个循环里,我们尝试得到这个action所对应的
,记作q(a)
这里的q(a)都是对应第i个样例的情况
然后i=1……m的那个循环是得到是最优的action对应的Value值,记作y(i),然后用y(i)拿去做supervised learning,大概就是这样一个思路
至于reward函数就比较简单了,比如说在inverted pendulum问题中,杆子比较直立就是给高reward,这个可以很直观地从状态得到衡量奖励的方法
在有了之上的东西之后,我们就可以去算我们的policy了:
6.确定性的模型
上面讲的连续状态的算法其实是针对一个非确定性的模型,即一个动作可能到达多个状态,有P在影响到达哪个状态如果在一个确定性模型中,其实是一个简化的问题,得到的样例简化了,计算也简化了
也就是说一个对于一个状态和一个动作,只能到达另一个状态,而不是多个,特例就不细讲了
7.控制MDP算法
前面重点讲的都是每个状态有个明确的奖励,并且没有时间的限制。但是在这里开始,我们的策略是有时间限制的,因此,我们的奖励最大值的计算,在到达时间T的时候就已经终结了。开始讲了如何求解含有T时间的策略方程。知道V*(T)是容易的,让后通过逆推的动态规划函数就可以解出。但是,有时间的策略方程,因为是有关于st和s(t+1)之间关系的,因此,也需要进行线性拟合,这个在之前已经讲过,这里不再赘述。有s(t+1)=As(t)+Balpha(t)。但是,这里的逆推在一些特殊情况下将会有非常高的效率。
1.reward函数的选取,假设可以表示为Rt+1(st,at)=-st'utst-at'vtat的形式等等,那么最终,可以迅速通过公式得到时间t状态下应该对应的策略。
实际上,就是假设:
,其中噪声项服从高斯分布,不是很重要。
但同时假设了边界时间,二次奖励函数。
8.微分动态规划
上一篇我们已经说到了,增强学习的目的就是求解马尔可夫决策过程(MDP)的最优策略,使其在任意初始状态下,都能获得最大的Vπ值。(本文不考虑非马尔可夫环境和不完全可观测马尔可夫决策过程(POMDP)中的增强学习)。那么如何求解最优策略呢?基本的解法有三种:
动态规划法(dynamic programming methods)
蒙特卡罗方法(Monte Carlo methods)
时间差分法(temporal difference)。
动态规划法是其中最基本的算法,也是理解后续算法的基础,因此本文先介绍动态规划法求解MDP。本文假设拥有MDP模型M=(S, A, Psa, R)的完整知识。
1. 贝尔曼方程(Bellman Equation)
上一篇我们得到了Vπ和Qπ的表达式,并且写成了如下的形式
在动态规划中,上面两个式子称为贝尔曼方程,它表明了当前状态的值函数与下个状态的值函数的关系。
优化目标π*可以表示为:
分别记最优策略π*对应的状态值函数和行为值函数为V*(s)和Q*(s, a),由它们的定义容易知道,V*(s)和Q*(s, a)存在如下关系:
状态值函数和行为值函数分别满足如下贝尔曼最优性方程(Bellman optimality equation):
有了贝尔曼方程和贝尔曼最优性方程后,我们就可以用动态规划来求解MDP了。
2. 策略估计(Policy Evaluation)
首先,对于任意的策略π,我们如何计算其状态值函数Vπ(s)?这个问题被称作策略估计,
前面讲到对于确定性策略,值函数
现在扩展到更一般的情况,如果在某策略π下,π(s)对应的动作a有多种可能,每种可能记为π(a|s),则状态值函数定义如下:
一般采用迭代的方法更新状态值函数,首先将所有Vπ(s)的初值赋为0(其他状态也可以赋为任意值,不过吸收态必须赋0值),然后采用如下式子更新所有状态s的值函数(第k+1次迭代):
对于Vπ(s),有两种更新方法,
第一种:将第k次迭代的各状态值函数[Vk(s1),Vk(s2),Vk(s3)..]保存在一个数组中,第k+1次的Vπ(s)采用第k次的Vπ(s')来计算,并将结果保存在第二个数组中。
第二种:即仅用一个数组保存各状态值函数,每当得到一个新值,就将旧的值覆盖,形如[Vk+1(s1),Vk+1(s2),Vk(s3)..],第k+1次迭代的Vπ(s)可能用到第k+1次迭代得到的Vπ(s')。
通常情况下,我们采用第二种方法更新数据,因为它及时利用了新值,能更快的收敛。整个策略估计算法如下图所示:
3. 策略改进(Policy Improvement)
上一节中进行策略估计的目的,是为了寻找更好的策略,这个过程叫做策略改进(Policy Improvement)。
假设我们有一个策略π,并且确定了它的所有状态的值函数Vπ(s)。对于某状态s,有动作a0=π(s)。 那么如果我们在状态s下不采用动作a0,而采用其他动作a≠π(s)是否会更好呢?要判断好坏就需要我们计算行为值函数Qπ(s,a),公式我们前面已经说过:
评判标准是:Qπ(s,a)是否大于Vπ(s)。如果Qπ(s,a)> Vπ(s),那么至少说明新策略【仅在状态s下采用动作a,其他状态下遵循策略π】比旧策略【所有状态下都遵循策略π】整体上要更好。
策略改进定理(policy improvement theorem):π和π'是两个确定的策略,如果对所有状态s∈S有Qπ(s,π'(s))≥Vπ(s),那么策略π'必然比策略π更好,或者至少一样好。其中的不等式等价于Vπ'(s)≥Vπ(s)。
有了在某状态s上改进策略的方法和策略改进定理,我们可以遍历所有状态和所有可能的动作a,并采用贪心策略来获得新策略π'。即对所有的s∈S, 采用下式更新策略:
这种采用关于值函数的贪心策略获得新策略,改进旧策略的过程,称为策略改进(Policy Improvement)
最后大家可能会疑惑,贪心策略能否收敛到最优策略,这里我们假设策略改进过程已经收敛,即对所有的s,Vπ'(s)等于Vπ(s)。那么根据上面的策略更新的式子,可以知道对于所有的s∈S下式成立:
可是这个式子正好就是我们在1中所说的Bellman optimality equation,所以π和π'都必然是最优策略!神奇吧!
4. 策略迭代(Policy Iteration)
策略迭代算法就是上面两节内容的组合。假设我们有一个策略π,那么我们可以用policy evaluation获得它的值函数Vπ(s),然后根据policy improvement得到更好的策略π',接着再计算Vπ'(s),再获得更好的策略π'',整个过程顺序进行如下图所示:
完整的算法如下图所示:
5. 值迭代(Value Iteration)
从上面我们可以看到,策略迭代算法包含了一个策略估计的过程,而策略估计则需要扫描(sweep)所有的状态若干次,其中巨大的计算量直接影响了策略迭代算法的效率。我们必须要获得精确的Vπ值吗?事实上不必,有几种方法可以在保证算法收敛的情况下,缩短策略估计的过程。
值迭代(Value Iteration)就是其中非常重要的一种。它的每次迭代只扫描(sweep)了每个状态一次。值迭代的每次迭代对所有的s∈S按照下列公式更新:
即在值迭代的第k+1次迭代时,直接将能获得的最大的Vπ(s)值赋给Vk+1。值迭代算法直接用可能转到的下一步s'的V(s')来更新当前的V(s),算法甚至都不需要存储策略π。而实际上这种更新方式同时却改变了策略πk和V(s)的估值Vk(s)。 直到算法结束后,我们再通过V值来获得最优的π。
此外,值迭代还可以理解成是采用迭代的方式逼近1中所示的贝尔曼最优方程。
值迭代完整的算法如图所示:
由上面的算法可知,值迭代的最后一步,我们才根据V*(s),获得最优策略π*。
一般来说值迭代和策略迭代都需要经过无数轮迭代才能精确的收敛到V*和π*, 而实践中,我们往往设定一个阈值来作为中止条件,即当Vπ(s)值改变很小时,我们就近似的认为获得了最优策略。在折扣回报的有限MDP(discounted finite MDPs)中,进过有限次迭代,两种算法都能收敛到最优策略π*。
至此我们了解了马尔可夫决策过程的动态规划解法,动态规划的优点在于它有很好的数学上的解释,但是动态要求一个完全已知的环境模型,这在现实中是很难做到的。另外,当状态数量较大的时候,动态规划法的效率也将是一个问题。下一篇介绍蒙特卡罗方法,它的优点在于不需要完整的环境模型。
PS: 如果什么没讲清楚的地方,欢迎提出,我会补充说明...
参考资料:
[1] R.Sutton et al. Reinforcement learning: An introduction , 1998
[2] 徐昕,增强学习及其在移动机器人导航与控制中的应用研究[D],2002
1. 蒙特卡罗方法的基本思想
蒙特卡罗方法又叫统计模拟方法,它使用随机数(或伪随机数)来解决计算的问题,是一类重要的数值计算方法。该方法的名字来源于世界著名的赌城蒙特卡罗,而蒙特卡罗方法正是以概率为基础的方法。
一个简单的例子可以解释蒙特卡罗方法,假设我们需要计算一个不规则图形的面积,那么图形的不规则程度和分析性计算(比如积分)的复杂程度是成正比的。而采用蒙特卡罗方法是怎么计算的呢?首先你把图形放到一个已知面积的方框内,然后假想你有一些豆子,把豆子均匀地朝这个方框内撒,散好后数这个图形之中有多少颗豆子,再根据图形内外豆子的比例来计算面积。当你的豆子越小,撒的越多的时候,结果就越精确。
2. 增强学习中的蒙特卡罗方法
现在我们开始讲解增强学习中的蒙特卡罗方法,与上篇的DP不同的是,这里不需要对环境的完整知识。蒙特卡罗方法仅仅需要经验就可以求解最优策略,这些经验可以在线获得或者根据某种模拟机制获得。
要注意的是,我们仅将蒙特卡罗方法定义在episode task上,所谓的episode task就是指不管采取哪种策略π,都会在有限时间内到达终止状态并获得回报的任务。比如玩棋类游戏,在有限步数以后总能达到输赢或者平局的结果并获得相应回报。
那么什么是经验呢?经验其实就是训练样本。比如在初始状态s,遵循策略π,最终获得了总回报R,这就是一个样本。如果我们有许多这样的样本,就可以估计在状态s下,遵循策略π的期望回报,也就是状态值函数Vπ(s)了。蒙特卡罗方法就是依靠样本的平均回报来解决增强学习问题的。
尽管蒙特卡罗方法和动态规划方法存在诸多不同,但是蒙特卡罗方法借鉴了很多动态规划中的思想。在动态规划中我们首先进行策略估计,计算特定策略π对应的Vπ和Qπ,然后进行策略改进,最终形成策略迭代。这些想法同样在蒙特卡罗方法中应用。
3. 蒙特卡罗策略估计(Monte Carlo Policy evalution)
首先考虑用蒙特卡罗方法来学习状态值函数Vπ(s)。如上所述,估计Vπ(s)的一个明显的方法是对于所有到达过该状态的回报取平均值。这里又分为first-visit MC methods和every-visit MC methods。这里,我们只考虑first MC methods,即在一个episode内,我们只记录s的第一次访问,并对它取平均回报。
现在我们假设有如下一些样本,取折扣因子γ=1,即直接计算累积回报,则有
根据first MC methods,对出现过状态s的episode的累积回报取均值,有Vπ(s)≈ (2 + 1 – 5 + 4)/4 = 0.5
容易知道,当我们经过无穷多的episode后,Vπ(s)的估计值将收敛于其真实值。
4. 动作值函数的MC估计(Mote Carlo Estimation of Action Values)
在状态转移概率p(s'|a,s)已知的情况下,策略估计后有了新的值函数,我们就可以进行策略改进了,只需要看哪个动作能获得最大的期望累积回报就可以。然而在没有准确的状态转移概率的情况下这是不可行的。为此,我们需要估计动作值函数Qπ(s,a)。Qπ(s,a)的估计方法前面类似,即在状态s下采用动作a,后续遵循策略π获得的期望累积回报即为Qπ(s,a),依然用平均回报来估计它。有了Q值,就可以进行策略改进了
5. 持续探索(Maintaining Exploration)
下面我们来探讨一下Maintaining Exploration的问题。前面我们讲到,我们通过一些样本来估计Q和V,并且在未来执行估值最大的动作。这里就存在一个问题,假设在某个确定状态s0下,能执行a0, a1, a2这三个动作,如果智能体已经估计了两个Q函数值,如Q(s0,a0), Q(s0,a1),且Q(s0,a0)>Q(s0,a1),那么它在未来将只会执行一个确定的动作a0。这样我们就无法更新Q(s0,a1)的估值和获得Q(s0,a2)的估值了。这样的后果是,我们无法保证Q(s0,a0)就是s0下最大的Q函数。
Maintaining Exploration的思想很简单,就是用soft policies来替换确定性策略,使所有的动作都有可能被执行。比如其中的一种方法是ε-greedy policy,即在所有的状态下,用1-ε的概率来执行当前的最优动作a0,ε的概率来执行其他动作a1, a2。这样我们就可以获得所有动作的估计值,然后通过慢慢减少ε值,最终使算法收敛,并得到最优策略。简单起见,在下面MC控制中,我们使用exploring
start,即仅在第一步令所有的a都有一个非零的概率被选中。
6. 蒙特卡罗控制(Mote Carlo Control)
我们看下MC版本的策略迭代过程:
根据前面的说法,值函数Qπ(s,a)的估计值需要在无穷多episode后才能收敛到其真实值。这样的话策略迭代必然是低效的。在上一篇DP中,我们了值迭代算法,即每次都不用完整的策略估计,而仅仅使用值函数的近似值进行迭代,这里也用到了类似的思想。每次策略的近似值,然后用这个近似值来更新得到一个近似的策略,并最终收敛到最优策略。这个思想称为广义策略迭代。
具体到MC control,就是在每个episode后都重新估计下动作值函数(尽管不是真实值),然后根据近似的动作值函数,进行策略更新。这是一个episode by episode的过程。
一个采用exploring starts的Monte Carlo control算法,如下图所示,称为Monte Carlo ES。而对于所有状态都采用soft policy的版本,这里不再讨论。
7. 小结
Monte Carlo方法的一个显而易见的好处就是我们不需要环境模型了,可以从经验中直接学到策略。它的另一个好处是,它对所有状态s的估计都是独立的,而不依赖与其他状态的值函数。在很多时候,我们不需要对所有状态值进行估计,这种情况下蒙特卡罗方法就十分适用。
不过,现在增强学习中,直接使用MC方法的情况比较少,而较多的采用TD算法族。但是如同DP一样,MC方法也是增强学习的基础之一,因此依然有学习的必要。
参考资料:
[1] R.Sutton et al. Reinforcement learning: An introduction, 1998
[2] Wikipedia,蒙特卡罗方法
7. 总结
首先我们这里讨论的MDP是非确定的马尔科夫决策过程,也就是回报函数和动作转换函数是有概率的。在状态s下,采取动作a后的转移到的下一状态s’也是有概率的。再次,在增强学习里有一个重要的概念是Q学习,本质是将与状态s有关的V(s)转换为与a有关的Q。强烈推荐Tom Mitchell的《机器学习》最后一章,里面介绍了Q学习和更多的内容。最后,里面提到了Bellman等式,在《算法导论》中有Bellman-Ford的动态规划算法,可以用来求解带负权重的图的最短路径,里面最值得探讨的是收敛性的证明,非常有价值。有学者仔细分析了增强学习和动态规划的关系。整个吴恩达机器学习视频的学习,到此为一个节点,由于强化学习部分,跟当前工作无关,因此,理解的不够透彻,后面几节课,都是跳着看的。以后有机会进入机器人算法研究再深入理解。
截止目前,整合网上各位大神的笔记,以及《机器学习导论》,吴恩达《机器学习课程》视频等资料,算是对机器学习算法的一个系统入门吧。接下来,针对工作内容,在相关领域做深入研究,时刻记住,自己是一位工程师,解决实际问题,才是硬道理。
OK
2016/2/17

相关文章推荐
- eclipse转android studio常遇到的问题
- python 矩阵随机生成
- ArrayList源码解析及简单自定义ArrayList
- WebView高危接口安全检测
- 造轮子:区分SQL Server关联查询之inner join,left join, right join, full outer join并图解
- 将 Shiro 作为应用的权限基础 五:SpringMVC+Apache Shiro+JPA(hibernate)整合配置
- eclipse启动时报告错误:Java was started but returned exit code=-805306369
- java对email的真实、有效性验证
- LeetCode 169. Majority Element
- 获取IP地址,判断是否开启热点
- phoenix 利用CsvBulkLoadTool 批量带入数据并自动创建索引
- CI框架获取post和get参数 CodeIgniter
- 解析sql语句中left_join、inner_join中的on与where的区别
- 配置在.properties文件中的常量,
- 安卓中IOC框架中所用的动态代理的应用。
- springMVC两种方式实现多文件上传及效率比较
- 面试题—链表操作2
- 网络安全领域最具代表性的75个安全工具
- Cron 表达式详解和案例
- crontab 相关