Linux 源码系列之可变参数列表实现
2016-02-14 17:54
525 查看
背景
从事 android 开发四年有余,应用开发做得越久,就越有“知其然不知其所以然”的感觉,于是乎,过去的大半年,我几乎一有时间就去啃《Linux内核完全剖析-基于0.12内核》,接近1000页的 linux 系统源码,读的过程可谓是五味杂陈,终于在2016春节跟它作了一个了断。虽不能说对 linux 的底层实现已了然于心,但阅读这本书确实起到了醍醐灌顶的功效,在很大程度上打通了我在技术上的任督二脉。有人会问,为什么是0.12版本?
答案很简单:
麻雀虽小,五脏俱全。
恕我才疏学浅,就像我更喜欢看 2.3版本的 android framework 源码一样,就是因为简单。linux 发展至今20余年,历经茫茫多的版本迭代,但其中的设计思想却是历久弥新,跟动辄几百万行的最新版本源码相比,先选一个软柿子捏捏,何乐而不为呢。
接下来我会把书上看到的知识点结合我自己的理解,写成一个系列发布出来,也算是对自己过去一段时间学习成果的整理和总结。
可变参数列表的使用
可变参数列表在很多语言中都有对应的语法支持,比如Java、
python。C 语言虽然是一门低级语言, 但是也支持可变参数列表, 而且它的可变参数列表实现得简单又不失巧妙,其中最著名的就是几个用来格式化字符串输出的 C 标准函数:
printf, 直接把输出送到标准输出句柄
stdout
cprintf, 把输出送到控制台
fprintf, 把输出送到文件句柄
sprintf, 把输出送到以
null结尾的字符串中
可变参数列表的实现
下面就以sprintf函数说明在 C 标准库函数中是如何实现可变参数列表的。在说明
sprintf的实现之前,非常有必要温习一下 C 函数调用在操作系统中是如何实现的,后面你们就知道为什么这里说这个很重要了。
C 函数调用机制
学过计算机的人都有一个模糊的印象(如果能把这里的事情说明白,那你基础一定很扎实),函数调用是通过栈来实现的,基本上就是一个入栈出栈的过程。大家可能又知道,C 的函数调用是传值调用,意思就是说 C 函数中用到的参数只是函数调用时传入参数的一个副本,所以要修改某个变量,就必须传入对应变量的地址指针。那么为什么是这样的?且看下面这幅图
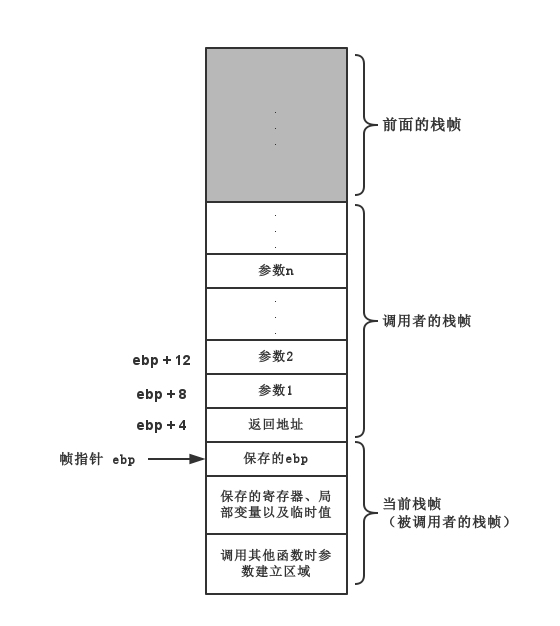
上面这幅图描绘了一个典型的函数调用栈内存结构,其中栈帧是指单个函数调用所使用的内存部分。每个栈帧的起始位置保存在寄存器
ebp中。当在 C 程序中做函数调用的时候,比如函数 A 调用函数 B,在 A 的代码逻辑中会把 B 函数用到的实参压入栈中,实参所在的内存部分实则属于 A 函数的栈帧部分(参数1到参数n),所以图中参数1到参数n部分其实是在函数 B 被调用之前被复制到内存中的,即所谓的副本。
问题来了,我们知道C 程序里仅仅是一个简单的函数调用,那么这部分工作是由谁来完成的呢?
答案是编译器,编译器会把要用的参数以准确的顺序和准确的大小压入内存中。被调用函数在使用参数时,编译器会把指定的参数引用转化成相对于
ebp寄存器的偏移值,就是图中形如
ebp + 4的部分。 编译器会在参数设置完成后调用特定 CPU 的函数调用(
CALL)指令,而 CPU 会在处理函数调用指令时把函数返回地址和调用者的栈帧地址压入内存,同时调整
ebp寄存器指向新的栈帧起始位置。
OK,说了那么多,可能有些抽象,让我们看一个简单的函数调用的例子。
C 函数调用举例
让我们来看一个简单的例子,示例代码如下:void swap(int *a, int *b) {
int c;
c = *a;
*a = *b;
*b = *c;
}
int main() {
int a, b;
a = 16;
b = 32;
swap(&a, &b);
return (a - b);
}代码逻辑很简单,就是在
main函数中调用
swap函数,完成两个整型变量的数值交换。代码逻辑不是我们关注的重点,我们要关注的是在操作系统底层是如何完成这次函数调用的。来看一下函数调用的栈帧结构。
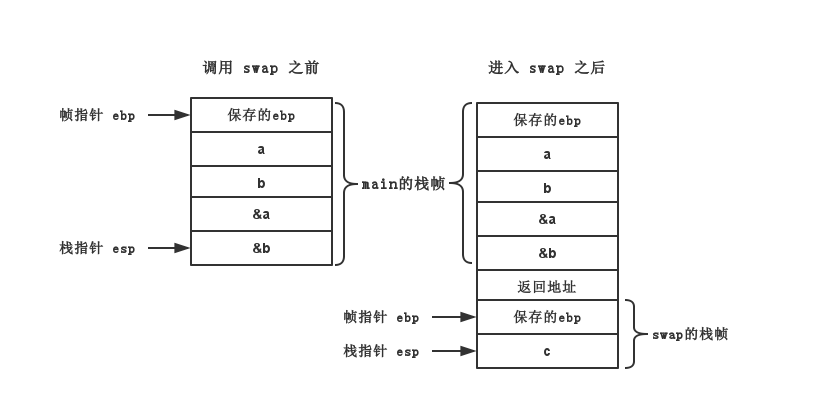
图中左边部分和右边的上半部分是
main函数的栈帧结构,可以看到在调用
swap函数之前,
main函数会先取变量
a和
b的地址,并压入栈中(属于自己的栈帧部分) ,然后再跳转到
swap函数中执行,执行过程中用到的本地变量(这里是
c)也会压入栈里。这里函数
swap要用到参数
*a和
*b时,就通过寄存器
ebp所指向的地址分别向上偏移8和12个字节地址来实现。
这里有一个关键的问题需要明确一下,编译器如何知道被调用函数的参数在内存的什么地方?约定,约定,约定。
编译器会把被调用函数用到的参数按照参数顺序逆序压入栈中,然后再压入函数返回地址,所以对于上面这个例子而言,
ebp + 8一定是第一个参数
*a的内存地址处,依此类推。明确了这一点,我们就可以来看看
sprintf是如何实现可变参数列表了。
sprintf
可变参数列表的实现
还是要先贴一下关键代码static int sprintf(char * str, const char *fmt, ...)
{
va_list args;
int i;
va_start(args, fmt);
i = vsprintf(str, fmt, args);
va_end(args);
return i;
}上面这段代码相当简单,直觉告诉我们,这里面比较关键是这几个点:
va_list是什么
va_start是什么
vsprintf实现了什么
我们来一一解答。
va_list是什么?
typedef char *va_list;
从声明来看,
va_list就是一个字节指针,更确切地说它表示一个内存地址
va_start是什么?
/* Amount of space required in an argument list for an arg of type TYPE. TYPE may alternatively be an expression whose type is used. */ #define __va_rounded_size(TYPE) \ (((sizeof (TYPE) + sizeof (int) - 1) / sizeof (int)) * sizeof (int)) #ifndef __sparc__ #define va_start(AP, LASTARG) \ (AP = ((char *) &(LASTARG) + __va_rounded_size (LASTARG))) #else #define va_start(AP, LASTARG) \ (__builtin_saveregs (), \ AP = ((char *) &(LASTARG) + __va_rounded_size (LASTARG))) #endif #define va_arg(AP, TYPE) \ (AP += __va_rounded_size (TYPE), \ *((TYPE *) (AP - __va_rounded_size (TYPE))))
va_start是一个宏定义,套入
va_start(args, fmt)后得到
args = (char *) &(fmt) + __va_rounded_size(fmt)
根据注释,
__va_ro a27b unded_size(fmt)是求得
fmt所需要的内存空间,并且补齐到4字节边界。 综上所述,
va_start的作用就是调整
args到
fmt后面的内存地址处。至于为什么这么处理,我们还得看
vsprintf的实现。
vsprintf实现了什么?
vsprintf的实现代码很长,大部分是处理格式化字符串的逻辑,我们只摘取其中涉及可变参数列表的部分。
...
switch (*fmt) {
case 'c':
...
*str++ = (unsigned char) va_arg(args, int);
...
break;
case 's':
s = va_arg(args, char *);
...
break;
case 'o':
str = number(str, va_arg(args, unsigned long), 8,
field_width, precision, flags);
break;
case 'p':
...
str = number(str,
(unsigned long) va_arg(args, void *), 16,
field_width, precision, flags);
break;
...
}
...这段逻辑是该函数的重点,简单的说,在扫描
fmt的过程中,如果遇到特殊字符,就从参数中获取对应类型的值。如何获取?可以看出,在每个分支中都会有
va_arg的调用,就是通过这个宏取得对应类型的值。我们找一个例子来说明一下。
把
va_arg(args, unsigned long)通过宏转换之后,得到如下语句:
(args += __va_rounded_size(unsigned long), *((unsigned long *)(args - __va_rounded_size(unsigned long))));
乍一看是个挺复杂的语句, 其实它做了两件事,一是从
args当前所表示的内存处取出对应类型的值,二就是让
args指向所取值后面的内存地址处。
弄清楚了几个关键点之后,我们再回过头来看看。
sprintf的典型调用如下所示:
sprintf(buf, "This is only a test %d, %s", 1, "hello");
结合 C 函数调用的机制,所有的参数都会在函数调用前按照一定的顺序被压入栈中, 只要通过
va_start设置好参数的内存起始位置,就可以通过
va_arg取得所有对应类型的参数,而具体要取得什么类型的参数,则是由格式字符串中的特殊字符决定的。
或许有人会问,如果我传入的实参和格式化字符串里指定的类型不一样,程序会挂吗?
我可以很负责任地告诉你,程序会照常运行,但是可能得不到你想要的结果,具体为什么,你自己去想吧,这就是 C 的精妙之处。

相关文章推荐
- Linux socket 初步
- Linux Kernel 4.0 RC5 发布!
- 从源码安装Mysql/Percona 5.5
- linux lsof详解
- linux 文件权限
- Linux 执行数学运算
- 10 篇对初学者和专家都有用的 Linux 命令教程
- Linux 与 Windows 对UNICODE 的处理方式
- Ubuntu12.04下QQ完美走起啊!走起啊!有木有啊!
- 解決Linux下Android开发真机调试设备不被识别问题
- 运维入门
- 运维提升
- Linux 自检和 SystemTap
- Ubuntu Linux使用体验
- c语言实现hashmap(转载)
- Linux 信号signal处理机制
- linux下mysql添加用户
- Scientific Linux 5.5 图形安装教程