Hadoop完全分布式集群安装(Ubuntu)
2016-02-14 11:58
363 查看
本文只是在Ubuntu下Hadoop环境的搭建步骤,不涉及原理。供自己下次搭建时能有个参考。
自己配备U盘一个。
a)首先,在mirrors.163.com(或者mirrors.sohu.com)找到服务器版的Ubuntu,如下图:

我们需要的是ubuntu-14.04.1-server-amd64.iso,下载到本地计算机。
b)下载并安装UltraISO,将Ubuntu系统镜像安装到U盘,具体步骤可以参考百度经验。
c)开启计算机,按F12(联想电脑)进入BIOS设置,找到start up选项,找到Boot Model,将原先的Auto改为UEFI。这个问了大牛,大牛说硬盘容量超过2T就需要这样修改,否则系统是安装不成功的,不超过2T就不需要修改。然后保存并退出。
d)这样就可以进入选择安装界面(如果出现让你选择U盘启动项的话,选择UEFI启动)。
- 选择Install Ubuntu Server;
- 然后语言,地区,键盘都选择默认;
- 下面就是主机名,用户名和密码的设置;
- 设置完了然后会提示Encrypt your home directory?是否加密你的home目录,这里为了简单起见,选择no;
- 然后就是设置时区,这里默认;
- 然后进入硬盘分区,提示Unmount partitions that in use?选择Yes;
- 然后选择分区方式,选择Guided-use entire disk;
- 一路回车,提示是否将这样的分区写入磁盘,选择Yes;
- 然后HTTP proxy information选择为空,继续;
- 这时就进入Configuration apt,此过程比较长,如果等不及可以按下回车取消配置,等到以后再说;
- 然后进入系统更新选项,选择Install Security updates automatically;
- 选择OpenSSH server;最后弹出提示finish installation,确认并拔掉U盘。
e)计算机重启就可以进入Ubuntu啦!安装完成!
d)其余计算机的安装相同,此处略去。
10.1.40.53 master
10.1.40.58 node1
10.1.40.54 node2
10.1.40.57 snode
修改/etc/hosts文件的内容,按照上述各式写入。
b)按照上面为4台计算机更改主机名,其中master将来运行nameNode和jobTracker,node1和node2分别运行dataNode和taskTracker,snode作为secondaryNameNode。
c)确保4台计算机的防火墙都关闭:
d)在master上输入
e)在此目录下复制公钥为authorized_keys:
f)进行单机回环ssh免密码登录测试:
g)依次输入
h)系统重启后在进行单机回环ssh免密码登录测试,此时就可以成功了!
i)所有4台计算机都通过单机回环ssh免密码登录测试后,就需要联通了。我们需要master可以无密码的通过ssh登录node1和node2,在node1机器上将master机器上的公钥复制过来然后将其内容增加至自己的authorized_keys文件中:
(此时处在node1的home/.ssh文件夹目录下)
对于node2进行相同的操作,此时,在master上ssh node1或者ssh node2都可以登录了。
b)首先进入root权限,在media下面创建目录sdb4;查看所有磁盘
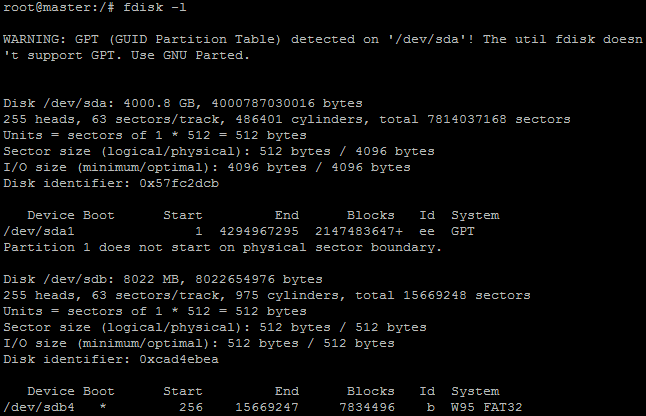
其中/dev/sdb4就是U盘的分区了。然后我们需要挂载U盘分区到/media/sdb4,使用命令:
如此,U盘上的东西就可以在/media/sdb4中访问到了。
c)进入/media/sdb4目录,查看当前目录下的内容(即U盘中的内容),有hadoop.tar.gz和jdk.gz,此处将这两个文件拷贝到/usr/local目录下,然后进行解压缩,分别将解压缩后的文件夹重命名为jdk和hadoop。
d)配置环境变量,
然后保存退出,
e)修改hadoop配置文件,主要修改core-site.xml、hdfs-site.xml和mapred-site.xml。这三个文件都在/usr/local/hadoop/conf文件夹下面。
core-site.xml内容修改如下:
hdfs-site.xml内容修改如下:
mapred-site.xml内容修改如下:
f)修改hadoop-env.sh文件,将第九行的
改为
g)将masters文件中名字修改为master,将slaves文件中的名字修改为node1(回车)node2。
h)接下来将配置好的jdk和hadoop文件拷贝到node1,node2和snode上面,拷贝有2种方式:
一是放在U盘里面一个一个拷贝;
二是通过登录node1,切换到root@node1,然后远程拷贝文件夹到node1的/usr/local目录下:
i)将其余节点的环境变量修改完成(参照master的环境变量修改)。
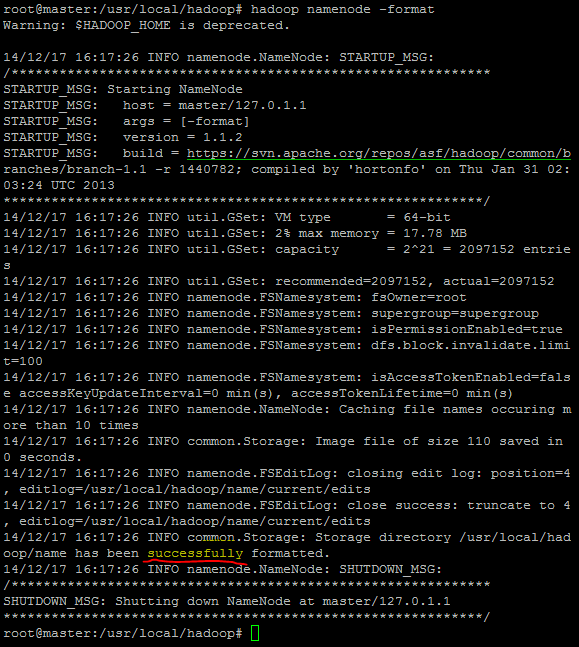
j)在master上对nameNode进行格式化:
1.硬件装备
最近公司开始需要搭建完全分布式hadoop环境,为此提供的硬件设备有4台全新联想电脑,配置为:64位CPU,32G内存,4T硬盘。要求采用Linux系统。自己配备U盘一个。
2.安装Linux系统(Ubuntu14.04-server)
考虑到hadoop环境只要能运行就行了,所以我们准备安装服务器版的Ubuntu。a)首先,在mirrors.163.com(或者mirrors.sohu.com)找到服务器版的Ubuntu,如下图:
我们需要的是ubuntu-14.04.1-server-amd64.iso,下载到本地计算机。
b)下载并安装UltraISO,将Ubuntu系统镜像安装到U盘,具体步骤可以参考百度经验。
c)开启计算机,按F12(联想电脑)进入BIOS设置,找到start up选项,找到Boot Model,将原先的Auto改为UEFI。这个问了大牛,大牛说硬盘容量超过2T就需要这样修改,否则系统是安装不成功的,不超过2T就不需要修改。然后保存并退出。
d)这样就可以进入选择安装界面(如果出现让你选择U盘启动项的话,选择UEFI启动)。
- 选择Install Ubuntu Server;
- 然后语言,地区,键盘都选择默认;
- 下面就是主机名,用户名和密码的设置;
- 设置完了然后会提示Encrypt your home directory?是否加密你的home目录,这里为了简单起见,选择no;
- 然后就是设置时区,这里默认;
- 然后进入硬盘分区,提示Unmount partitions that in use?选择Yes;
- 然后选择分区方式,选择Guided-use entire disk;
- 一路回车,提示是否将这样的分区写入磁盘,选择Yes;
- 然后HTTP proxy information选择为空,继续;
- 这时就进入Configuration apt,此过程比较长,如果等不及可以按下回车取消配置,等到以后再说;
- 然后进入系统更新选项,选择Install Security updates automatically;
- 选择OpenSSH server;最后弹出提示finish installation,确认并拔掉U盘。
e)计算机重启就可以进入Ubuntu啦!安装完成!
d)其余计算机的安装相同,此处略去。
3.更改计算机名称并分配角色
a)查询得到4台计算机IP地址后分配如下:10.1.40.53 master
10.1.40.58 node1
10.1.40.54 node2
10.1.40.57 snode
修改/etc/hosts文件的内容,按照上述各式写入。
b)按照上面为4台计算机更改主机名,其中master将来运行nameNode和jobTracker,node1和node2分别运行dataNode和taskTracker,snode作为secondaryNameNode。
c)确保4台计算机的防火墙都关闭:
sudo ufw status查看防火墙状态
sudo ufw disable关闭防火墙
d)在master上输入
ssh-keygen -t rsa然后一路回车,此时在home目录下会多出.ssh的隐藏文件,进入该目录里面有id_rsa和id_rsa.pub,前者为私钥,后者为公钥。
e)在此目录下复制公钥为authorized_keys:
cp id_rsa.pub authorized_keys
f)进行单机回环ssh免密码登录测试:
ssh localhost,如果此过程不通,那是由于在先前装Ubuntu系统时我们跳过了很多系统软件的安装,此时需要把它们都安装起来。
g)依次输入
apt-get install,
apt-get upgrade,
apt-get install ‘openssh-server’三条命令,此过程比较长!
h)系统重启后在进行单机回环ssh免密码登录测试,此时就可以成功了!
i)所有4台计算机都通过单机回环ssh免密码登录测试后,就需要联通了。我们需要master可以无密码的通过ssh登录node1和node2,在node1机器上将master机器上的公钥复制过来然后将其内容增加至自己的authorized_keys文件中:
scp siti@master:~/.ssh/id_rsa.pub ./master_rsa.pub
(此时处在node1的home/.ssh文件夹目录下)
cat master_rsa.pub >> authorized_keys
对于node2进行相同的操作,此时,在master上ssh node1或者ssh node2都可以登录了。
4.环境的搭建
a)将hadoop.tar.gz和jdk.gz拷贝到U盘上,插到Linux机器上。b)首先进入root权限,在media下面创建目录sdb4;查看所有磁盘
fdisk -l,然后会列出所有的磁盘项目,如下图所示:
其中/dev/sdb4就是U盘的分区了。然后我们需要挂载U盘分区到/media/sdb4,使用命令:
mount /dev/sdb4 -o iocharset=utf8 /media/sdb4
如此,U盘上的东西就可以在/media/sdb4中访问到了。
c)进入/media/sdb4目录,查看当前目录下的内容(即U盘中的内容),有hadoop.tar.gz和jdk.gz,此处将这两个文件拷贝到/usr/local目录下,然后进行解压缩,分别将解压缩后的文件夹重命名为jdk和hadoop。
d)配置环境变量,
vi /etc/profile,在最下面加上如下内容:
export JAVA_HOME=/usr/local/jdk export HADOOP_HOME=/usr/local/hadoop export PATH=.:$HADOOP_HOME/bin:$JAVA_HOME/bin:$PATH
然后保存退出,
source /etc/profile立即生效,输入
java -version发现jdk安装成功!
e)修改hadoop配置文件,主要修改core-site.xml、hdfs-site.xml和mapred-site.xml。这三个文件都在/usr/local/hadoop/conf文件夹下面。
core-site.xml内容修改如下:
<configuration> <property> <name>fs.default.name</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/tmp</value> </property> </configuration>
hdfs-site.xml内容修改如下:
<configuration> <property> <name>dfs.name.dir</name> <value>/usr/local/hadoop/name</value> </property> <property> <name>dfs.data.dir</name> <value>/usr/local/hadoop/data</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> </configuration>
mapred-site.xml内容修改如下:
<configuration> <property> <name>mapred.job.tracker</name> <value>master:9001</value> </property> </configuration>
f)修改hadoop-env.sh文件,将第九行的
# export JAVA_HOME=/usr/lib/j2sdk1.5-sun
改为
export JAVA_HOME=/usr/local/jdk
g)将masters文件中名字修改为master,将slaves文件中的名字修改为node1(回车)node2。
h)接下来将配置好的jdk和hadoop文件拷贝到node1,node2和snode上面,拷贝有2种方式:
一是放在U盘里面一个一个拷贝;
二是通过登录node1,切换到root@node1,然后远程拷贝文件夹到node1的/usr/local目录下:
root@node1:/usr/local# scp -r siti@master:/usr/local/hadoop .
root@node1:/usr/local# scp -r siti@master:/usr/local/jdk .
i)将其余节点的环境变量修改完成(参照master的环境变量修改)。
j)在master上对nameNode进行格式化:
hadoop namenode -format。如果此步骤失败,可以进入到/usr/local/hadoop目录下执行
rm tmp,将tmp删除,再在此目录下执行格式化。
5.启动
在master上启动hadoop:start-all.sh,在浏览器中访问http://192.168.1.100:50030和http://192.168.1.100:50070访问成功即可。
6.结束
Ubuntu安装总是出现各种各样的问题,建议使用CentOS安装。
相关文章推荐
- Ubuntu 默认壁纸历代记
- Ubuntu Remix Cinnamon 20.04 评测:Ubuntu 与 Cinnamon 的完美融合
- 关于Ubuntu 11.10启动提示waiting for the network configuration的问题
- 在 Ubuntu 桌面中使用文件和文件夹
- ubuntu下chrome无法同步问题解决
- 详解HDFS Short Circuit Local Reads
- Ubuntu Linux使用体验
- 使用 GNOME 优化工具自定义 Linux 桌面的 10 种方法
- 以Ubuntu 9.04为例 将工作环境迁移到 Linux
- Hadoop_2.1.0 MapReduce序列图
- 使用Hadoop搭建现代电信企业架构
- VirtualBox虚拟机XP与宿主机Ubuntu互访共享文件夹
- 从USB安装Ubuntu Server 10.04.3 图文详解
- Ubuntu 15.04 正式版发布下载
- Linux-Ubuntu 10.04安装Cadence-ic610 方法总结图解
- Ubuntu 12.04和Windows 7双系统安装图解
- 开机出现:grub rescue的修复方法
- Ubuntu连接Android真机调试
- 分布式版本管理git入门指南使用资料汇总及文章推荐
- 你应该选择 Ubuntu 还是 Fedora?