日志分析(二)jvm agent+kafka+es +kibana 的OLAP日志分析系统
2016-01-31 08:48
267 查看
摘要: 日志分析系统的一种弱组合,来实现数目不多主机或实例的web 日志分析的需求。
jvm agent+kafka+es +kibana
一般web业务的场景都包含了分布式,web事务的多应用间跳转,各层次间实现负载均衡等。日志分析OLAP的技术要求就需要跟踪夸web应用的多层次、多应用的链式请求,针对多应用。如果采用离线收集数据,又需要针对每个应用启动对应的日志收集实例比如 logstash的shipper或者flume 的agent等,颇为浪费;如果各个应用的日志格式或者日志路径不统一、样式复杂等,就需要针对性的去配置对应收集端的一些filter和采集路径。
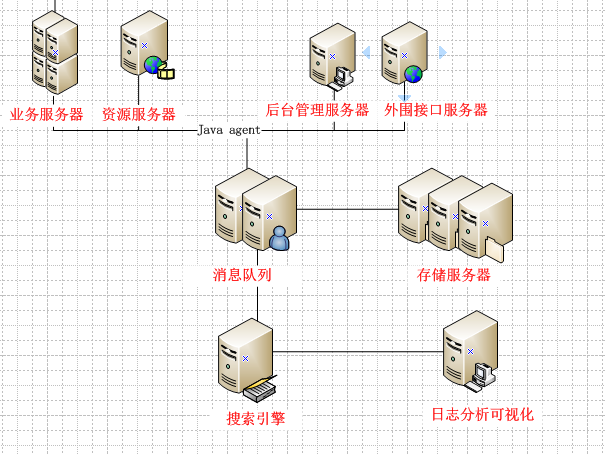
针对以上弊端,所以设计上采用各个应用日志采集采用主动push而非OLAP系统去pull。这样弊端应该是日志采集和主题业务的进程绑定,这个需要代码进行规避对主业务的影响。优点就是在日志格式上可以得到统一、减少io次数、避免数据聚合或者预预算次数等从而效率更优。热日志推送的概念,还需要降低对代码的侵入性以及日志埋点的可控。
综上,需要针对所有web业务应用做一个字节码的嵌入,实现指定埋点的日志收集工作。实现该操作目前有两种方式:动态编译 和 动态生成二进制字节码。动态编译是指在运行期前、类装载后,进行class读取后改造,并加载到classloader。有许多实现方式比如ASM、javassist、cglib等。
这几个的博客很多,都是比较成型的技术,各种利弊也就是asm 需要汇编语言,但是更为灵活,速度更快;cglib 在asm上进行了封装,效率比jdk自带的代理反射快了很多。具体对比看下:
http://stackoverflow.com/questions/2261947/are-there-alternatives-to-cglib
这部分选择了api简易的动态编译Jboss开源javassist包。实现原理是在jvm的运行期前,类加载器后,进行class的修改。逻辑类似dubbo的wrapper实现~~

源:http://jboss-javassist.github.io/javassist/
在类加载器时期,进行class的选择性动态编译,动态添加实现其输出日志的代码逻辑。
传输日志,使用了kafka 消息中间件,kafka的异步批量传输效率非常高而且比较稳定。kafka介绍现在较多:
http://kafka.apache.org/documentation.html
http://blog.csdn.net/lizhitao/article/details/39499283
https://github.com/abhioncbr/Kafka-Message-Server
kafka直接写入es。即kafka的producer是由javassist 的agent进行动态编译添加到所有应用中,然后consumer转写入es进行存储,建立实时索引。
elasticsearch-river-kafka实现源码:
https://github.com/xiaolongc/elasticsearch-river-kafka
日志分析olap系统,业务性能损耗和成本支出,可根据第一个博客里面提到的两种日志源分:冷日志文件处理,这种系统损耗在于日志的io输出到文件的过程会损耗业务代码的响应效率,大多系统在线上会省去部分日志代码节约响应时间和物理空间,如果有对应日志收集,就要有对输出的文件再次转化为io流,进行过滤、聚合等应用成本;热日志数据传输,这种数据损耗发生在日志的传输过程,因为这种对于日志的发送和正常业务调度是同步的,这部分损耗如果对异常、日志传输等进行优化,效率应该优于第一种,还有就是应用成本会降低。
综上,jvm agent+kafka+es +kibana 的OLAP日志分析系统有以下优点:成本较低、效率高、入侵性较低、可复用性强等。目前已经完成web事务traceid的方法级调用链跟踪、业务埋点的统计、应用异常的抓取等功能。后续会继续跟进。
------
补:Google的Dapper,淘宝的鹰眼,Twitter的ZipKin,京东商城的Hydra,eBay的Centralized Activity Logging (CAL),大众点评网的CAT~~~ 相同功能的架构体系。
jvm agent+kafka+es +kibana
一般web业务的场景都包含了分布式,web事务的多应用间跳转,各层次间实现负载均衡等。日志分析OLAP的技术要求就需要跟踪夸web应用的多层次、多应用的链式请求,针对多应用。如果采用离线收集数据,又需要针对每个应用启动对应的日志收集实例比如 logstash的shipper或者flume 的agent等,颇为浪费;如果各个应用的日志格式或者日志路径不统一、样式复杂等,就需要针对性的去配置对应收集端的一些filter和采集路径。
针对以上弊端,所以设计上采用各个应用日志采集采用主动push而非OLAP系统去pull。这样弊端应该是日志采集和主题业务的进程绑定,这个需要代码进行规避对主业务的影响。优点就是在日志格式上可以得到统一、减少io次数、避免数据聚合或者预预算次数等从而效率更优。热日志推送的概念,还需要降低对代码的侵入性以及日志埋点的可控。
综上,需要针对所有web业务应用做一个字节码的嵌入,实现指定埋点的日志收集工作。实现该操作目前有两种方式:动态编译 和 动态生成二进制字节码。动态编译是指在运行期前、类装载后,进行class读取后改造,并加载到classloader。有许多实现方式比如ASM、javassist、cglib等。
这几个的博客很多,都是比较成型的技术,各种利弊也就是asm 需要汇编语言,但是更为灵活,速度更快;cglib 在asm上进行了封装,效率比jdk自带的代理反射快了很多。具体对比看下:
http://stackoverflow.com/questions/2261947/are-there-alternatives-to-cglib
这部分选择了api简易的动态编译Jboss开源javassist包。实现原理是在jvm的运行期前,类加载器后,进行class的修改。逻辑类似dubbo的wrapper实现~~
源:http://jboss-javassist.github.io/javassist/
在类加载器时期,进行class的选择性动态编译,动态添加实现其输出日志的代码逻辑。
传输日志,使用了kafka 消息中间件,kafka的异步批量传输效率非常高而且比较稳定。kafka介绍现在较多:
http://kafka.apache.org/documentation.html
http://blog.csdn.net/lizhitao/article/details/39499283
https://github.com/abhioncbr/Kafka-Message-Server
kafka直接写入es。即kafka的producer是由javassist 的agent进行动态编译添加到所有应用中,然后consumer转写入es进行存储,建立实时索引。
elasticsearch-river-kafka实现源码:
https://github.com/xiaolongc/elasticsearch-river-kafka
日志分析olap系统,业务性能损耗和成本支出,可根据第一个博客里面提到的两种日志源分:冷日志文件处理,这种系统损耗在于日志的io输出到文件的过程会损耗业务代码的响应效率,大多系统在线上会省去部分日志代码节约响应时间和物理空间,如果有对应日志收集,就要有对输出的文件再次转化为io流,进行过滤、聚合等应用成本;热日志数据传输,这种数据损耗发生在日志的传输过程,因为这种对于日志的发送和正常业务调度是同步的,这部分损耗如果对异常、日志传输等进行优化,效率应该优于第一种,还有就是应用成本会降低。
综上,jvm agent+kafka+es +kibana 的OLAP日志分析系统有以下优点:成本较低、效率高、入侵性较低、可复用性强等。目前已经完成web事务traceid的方法级调用链跟踪、业务埋点的统计、应用异常的抓取等功能。后续会继续跟进。
------
补:Google的Dapper,淘宝的鹰眼,Twitter的ZipKin,京东商城的Hydra,eBay的Centralized Activity Logging (CAL),大众点评网的CAT~~~ 相同功能的架构体系。

相关文章推荐
- Redis源码解析:05跳跃表
- HDOJ 5615-Jam's math problem【数学】
- 分布式技术一周技术动态 2016.01.31
- Oracle单节点开启关闭归档日志
- 矩阵相乘
- C#中using的几种用法
- underscorejs-pluck学习
- 一起talk C栗子吧(第一百一十五回:C语言实例--线程同步之互斥量一)
- SpringAOP拦截Controller,Service实现日志管理(自定义注解的方式)
- 小蚂蚁学习数据结构(27)——题目——一个关于链表的题目
- HDU2896.病毒侵袭中【MLE和PE的原因】【AC自动机模板题】
- underscorejs-invoke学习
- Linux命令之find(一)
- 年初英语
- 月光微博客
- 昨日参加hackerrank一比赛总结
- 中科燕园GIS外包---地铁GIS项目
- 月光微博客
- MVC整个样例的源代码
- C++ DirectX 游戏开发初级视频教程 19 资源下载链接