Study Notes: Lua language for Torch
2016-01-28 19:05
639 查看
Content are from: https://github.com/soumith/cvpr2015/blob/master/Deep%20Learning%20with%20Torch.ipynbLua Data types: Lua has two data structure built-in, a table: 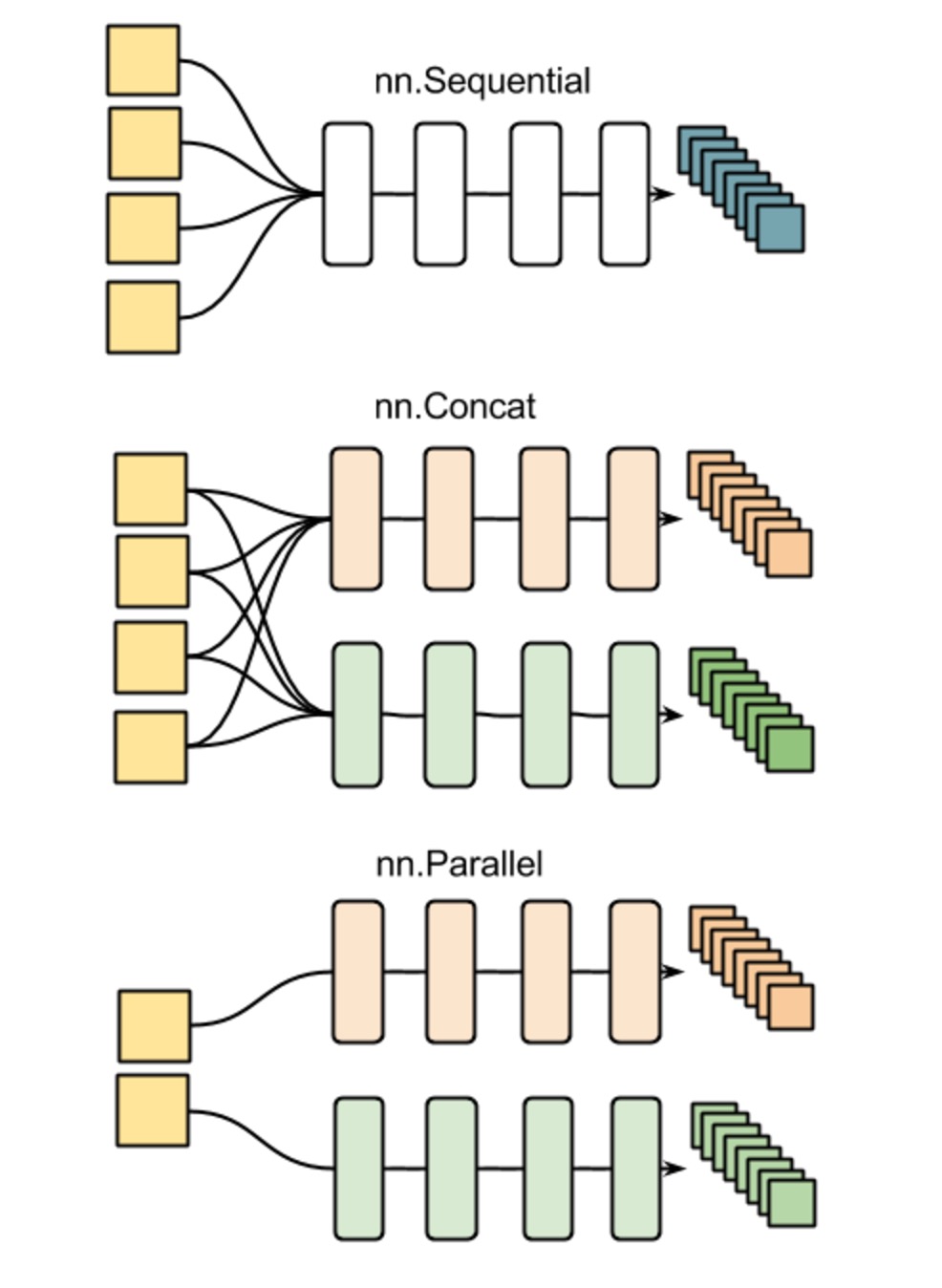 All these can be used nn.Sequential(); nn.Parallel() or nn.Concat() to realize. It must be declared in the beginning of code. Here is the example:
All these can be used nn.Sequential(); nn.Parallel() or nn.Concat() to realize. It must be declared in the beginning of code. Here is the example:
{}
and tensor(matrix). Also there are Strings,numbers. String use '' : a = 'hello'# is the length operator in LuaLike: :
for i=1,#b do -- the # operator is the length operator in Lua print(b[i]) endTensor in Lua is like matrix in matlab:
a = torch.Tensor(5,3) -- construct a 5x3 matrix, uninitializedThere are three syntax of matrix multiply of Lua:
-- matrix-matrix multiplication: syntax 1 a*b
-- matrix-matrix multiplication: syntax 2 torch.mm(a,b)--matrix-matrixmultiplication:syntax3c=torch.Tensor(5,4)c:mm(a,b)--storetheresultofa*bincTensor can use : to call some useful tools like the example above:
require 'cutorch'; -- like import a = a:cuda() -- call cuda b = b:cuda() c = c:cuda() c:mm(a,b) -- done on GPUConstruct Neural Networks (use 'nn'): Constructing neural network in torch needs 'require 'nn'' at first.There are three kinds of nn in torch:
All these can be used nn.Sequential(); nn.Parallel() or nn.Concat() to realize. It must be declared in the beginning of code. Here is the example:net = nn.Sequential() net:add(nn.SpatialConvolution(1, 6, 5, 5)) -- 1 input image channel, 6 output channels, 5x5 convolution kernel net:add(nn.Sigmoid()) -- non-linearity net:add(nn.SpatialMaxPooling(2,2,2,2)) -- A max-pooling operation that looks at 2x2 windows and finds the max. net:add(nn.SpatialConvolution(6, 16, 5, 5)) net:add(nn.Sigmoid()) -- non-linearity net:add(nn.SpatialMaxPooling(2,2,2,2))It defines the first two convolution layers of the network. Every neural networkmodule in torch has automatic differentiation. It has a
:forward(input)functionthat computes the output for a given input, flowing the input through the network. and it has a
:backward(input, gradient)functionthat will differentiate each neuron in the network w.r.t. the gradient that is passed in. In the networkI mentioned above, the convolution layer can let it's convolution kernels to learn if it adapt the input data and the problem beingsolved. So the parameters of this layer are learnable. However,the max-pooling layer has no learnable parameters. It only finds the max of local windows.Forlearnable parameters, we can use the .weight to see what parameters does this layer have.
m = nn.SpatialConvolution(1,3,2,2) -- learn 3 2x2 kernels print(m.weight) -- initially, the weights are randomly initializedThereare also two other important fields in a learnable layer. The gradWeight and gradBias. The gradWeight accumulates the gradients w.r.t. each weight in the layer, and the gradBias, w.r.t. each bias in the layer. We can use .gradWeight and .gradBias to see them. By the way, gradWeight is the usual gradient we are talking about.
Use Criterion to define a loss function
In torch, loss functions are implemented just like neural network modules, and have automatic differentiation.They have two functions -forward(input, target),
backward(input, target)
criterion = nn.ClassNLLCriterion() -- a negative log-likelihood criterion for multi-class classificationcriterion:forward(output, 3) -- let's say the groundtruth was class number: 3gradients = criterion:backward(output, 3)Then we can perform gradient descent in back propagation:
gradInput = net:backward(input, gradients)
Use :train(training-set) to train the network
For the network to adjust itself, it typically does this operation (if you do Stochastic Gradient Descent):weight = weight + learningRate * gradWeight If we use thesimple SGD trainer for example (more details in https://github.com/torch/nn/blob/master/doc/training.md#stochasticgradientmodule-criterion): It has a function :train(dataset) that takes a given dataset and simply trains your network by showing different samples fromyour dataset to the network.
相关文章推荐
- 详解Lua中的表的概念及其相关操作方法
- Lua编程示例(二):面向对象、metatable对表进行扩展
- 把Lua编译进nginx步骤方法
- Lua脚本自动生成APK包
- Lua中的元表(metatable)、元方法(metamethod)详解
- Lua中的metatable介绍
- Lua中ipair和pair的区别
- Lua中的函数精讲笔记
- 浅谈Lua的面向对象特性
- 详解Lua中的变量相关知识点
- Lua脚本语言入门笔记
- Lua脚本调用外部脚本
- 详解Lua中的if语句的使用方法
- Lua中调用函数使用点号和冒号的区别
- Lua中的闭合函数、非全局函数与函数的尾调用详解
- Lua中强大的元方法__index详解
- Lua中调用C++函数示例
- Lua面向对象之类和继承浅析
- Lua性能优化技巧(一):前言
- Lua中获取table长度问题探讨