字符串匹配的KMP算法
2016-01-27 16:43
176 查看
字符串匹配是计算机的基本任务之一。
举例来说,有一个字符串"BBC ABCDAB ABCDABCDABDE",我想知道,里面是否包含另一个字符串"ABCDABD"?

许多算法可以完成这个任务,Knuth-Morris-Pratt算法(简称KMP)是最常用的之一。它以三个发明者命名,起头的那个K就是著名科学家Donald Knuth。

这种算法不太容易理解,网上有很多解释,但读起来都很费劲。直到读到Jake
Boxer的文章,我才真正理解这种算法。下面,我用自己的语言,试图写一篇比较好懂的KMP算法解释。
1.

首先,字符串"BBC ABCDAB ABCDABCDABDE"的第一个字符与搜索词"ABCDABD"的第一个字符,进行比较。因为B与A不匹配,所以搜索词后移一位。
2.

因为B与A不匹配,搜索词再往后移。
3.

就这样,直到字符串有一个字符,与搜索词的第一个字符相同为止。
4.

接着比较字符串和搜索词的下一个字符,还是相同。
5.

直到字符串有一个字符,与搜索词对应的字符不相同为止。
6.

这时,最自然的反应是,将搜索词整个后移一位,再从头逐个比较。这样做虽然可行,但是效率很差,因为你要把"搜索位置"移到已经比较过的位置,重比一遍。
7.
一个基本事实是,当空格与D不匹配时,你其实知道前面六个字符是"ABCDAB"。KMP算法的想法是,设法利用这个已知信息,不要把"搜索位置"移回已经比较过的位置,继续把它向后移,这样就提高了效率。
8.

怎么做到这一点呢?可以针对搜索词,算出一张《部分匹配表》(Partial Match Table)。这张表是如何产生的,后面再介绍,这里只要会用就可以了。
9.
已知空格与D不匹配时,前面六个字符"ABCDAB"是匹配的。查表可知,最后一个匹配字符B对应的"部分匹配值"为2,因此按照下面的公式算出向后移动的位数:
移动位数 = 已匹配的字符数 - 对应的部分匹配值
因为 6 - 2 等于4,所以将搜索词向后移动4位。
10.

因为空格与C不匹配,搜索词还要继续往后移。这时,已匹配的字符数为2("AB"),对应的"部分匹配值"为0。所以,移动位数 = 2 - 0,结果为 2,于是将搜索词向后移2位。
11.
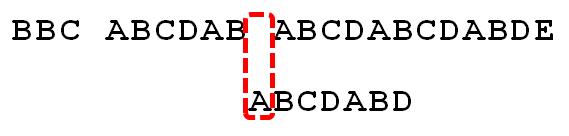
因为空格与A不匹配,继续后移一位。
12.

逐位比较,直到发现C与D不匹配。于是,移动位数 = 6 - 2,继续将搜索词向后移动4位。
13.

逐位比较,直到搜索词的最后一位,发现完全匹配,于是搜索完成。如果还要继续搜索(即找出全部匹配),移动位数 = 7 - 0,再将搜索词向后移动7位,这里就不再重复了。
14.

下面介绍《部分匹配表》是如何产生的。
首先,要了解两个概念:"前缀"和"后缀"。 "前缀"指除了最后一个字符以外,一个字符串的全部头部组合;"后缀"指除了第一个字符以外,一个字符串的全部尾部组合。
15.
"部分匹配值"就是"前缀"和"后缀"的最长的共有元素的长度。以"ABCDABD"为例,
16.
"部分匹配"的实质是,有时候,字符串头部和尾部会有重复。比如,"ABCDAB"之中有两个"AB",那么它的"部分匹配值"就是2("AB"的长度)。搜索词移动的时候,第一个"AB"向后移动4位(字符串长度-部分匹配值),就可以来到第二个"AB"的位置。
转载地址:http://developer.51cto.com/art/201305/392555_all.htm
二、
[b]1、传统的字符串匹配算法
2、[b]传统字符串匹配算法的性能问题[/b]
用模式串P去匹配字符串S,在i=6,j=4时发生失配:
i=6
S: a b a b c a d c a c b a b
P: a b c a c
j=4
此时,按照传统算法,应当将P的第 1 个字符 a(j=0) 滑动到与S中第4个字符 b(i=3) 对齐再进行匹配:
i=3
S: a b a b c a a d a c b a b
P: a b c a c
j=0
这个过程中,对字符串S的访问发生了“回朔”(从 i=6 移回到 i=3)。
我们不希望发生这样的回朔,而是试图通过尽可能的“向右滑动”模式串P,让P中index为 j 的字符对齐到S中 i=5 的字符,然后试图匹配S中 i=6 的字符与P中index为 j+1 的字符。
在这个测试用例中,我们直接将P向右滑动3个字符,使S中 i=5 的字符与P中 j=0 的字符对齐,再匹配S中 i=6 的字符与P中 j=1 的字符。
i=6
S: a b a b c a d c a c b a b
P: a
b c a c
j=0
3、kmp算法的一般性讨论
下面讨论在一般性的情况下,如何实现在“不回朔”访问S、仅依靠“滑动”P的前提下实现字符串匹配,即“kmp算法”。
i=6
S: a b a b c a d c a c b a b
P: a b c a c
k=1
i=6
S: a b a b c a d c a c b a b
P: a b c a c
j=4
对于任意的S和P,当S中index为 i 的字符和P中index为 j 的字符失配时,我们假定应当滑动P使其index为 k 的字符与S中index为 i 的字符“对齐”并继续比较。
那么,这个 k 是多少?
我们知道,所谓的对齐,就是要让S和P满足以下条件(上图中的蓝色字符):

……(1)
另一方面,在失配时我们已经有了一些部分匹配结果(上图中的绿色字符):

……(2)
由(1)、(2)可以得到:

……(3)
即如下图所示效果:

定义next[j]=k,k表示当模式串P中index为 j 的字符与主串S中index为 i 的字符发生失配时,应将P中index为 k 的字符继续与主串S中index为 i 的字符比较。

……(4)
按上述定义给出next数组的一个例子:
j 0 1 2 3 4 5 6 7
P a b a a b c a c
next[j] -1 0 0 1 1 2 0 1
在已知next数组的前提下,字符串匹配的步骤如下:
i 和 j 分别表示在主串S和模式串P中当前正待比较的字符的index,i 的初始值为sIndex,j 的初始值为0。
在匹配过程中的每一次循环,若

,i 和 j 分别增 1,
else,j 退回到 next[j]的位置,此时下一次循环是

与

相比较。
4、kmp算法的实现
在已知next函数的前提下,根据上面的步骤,kmp算法的实现如下:
ok,下面的问题是怎么求模式串 P 的next数组。
next数组的初始条件是next[0] = -1,设next[j] = k,则有:
那么,next[j+1]有两种情况:
①

,则有:

此时next[j+1] = next[j] + 1 = k + 1
②

, 如图所示:

此时需要将P向右滑动之后继续比较P中index为 j 的字符与index为 next[k] 的字符:

值得注意的是,上面的“向右滑动”本身就是一个kmp在失配情况下的滑动过程,将这个过程看 P 的自我匹配,则有:

如果

,则next[j+1] = next[k] + 1;
否则,继续将 P 向右滑动,直至匹配成功,或者不存在这样的匹配,此时next[j+1] = 0。
getNext函数的实现如下:
至此,一个完整的kmp已经实现。
5、getNext函数的进一步优化
注意到,上面的getNext函数还存在可以优化的地方,比如:
i=3
S: a a a
b a a a a b
P: a a a
a b
j=3
此时,i=3、j=3时发生失配,next[3]=2,此时还需要进行 3 次比较:
i=3, j=2;
i=3, j=1;
i=3, j=0。
而实际上,因为i=3, j=3时就已经知道a!=b,而之后的三次依旧是拿 a 和 b 比较,因此这三次比较都是多余的。
此时应当直接将P向右滑动4个字符,进行 i=4, j=0的比较。
一般而言,在getNext函数中,next[i]=j,也就是说当p[i]与S中某个字符匹配失败的时候,用p[j]继续与S中的这个字符比较。
如果p[i]==p[j],那么这次比较是多余的(如同上面的例子),此时应该直接使next[i]=next[j]。
完整的实现代码如下:
对应的,只需要在kmp算法中将 getNext(p, next); 替换成 getNextUpdate(p, next); 即可。
6、时间复杂度分析
下面以getNext函数为例,分析kmp算法的时间复杂度。
假定p.size()为m,分析其时间复杂度的困惑在于,在while里面不是每次循环都执行 ++i 操作,所以整个while的执行次数不一定为m。
换个角度,注意到在每次循环中,无论 if 还是 else 都会修改 j 的值且每次循环仅对 j 进行一次修改,所以在整个while中 j 被修改的次数即为getNext函数的时间复杂度。
每次成功匹配时,++i; ++j; , 由于 ++i 最多执行 m-1 次,故++j也最多执行 m-1 次,即 j 最多增加m-1次;
对应的,只有在 j=next[j]; 处 j 的值一定会变小,由于 j 最多增加m-1次,故 j 最多减小m-1次。
综上所述,getNext函数的时间复杂度为O(m),若带匹配串S的长度为n,则kmp函数的时间负责度为O(m+n)。
7、kmp的应用优势
①快,O(m+n)的线性最坏时间复杂度;
②无需回朔访问待匹配字符串S,所以对处理从外设输入的庞大文件很有效,可以边读入边匹配。
举例来说,有一个字符串"BBC ABCDAB ABCDABCDABDE",我想知道,里面是否包含另一个字符串"ABCDABD"?
许多算法可以完成这个任务,Knuth-Morris-Pratt算法(简称KMP)是最常用的之一。它以三个发明者命名,起头的那个K就是著名科学家Donald Knuth。
这种算法不太容易理解,网上有很多解释,但读起来都很费劲。直到读到Jake
Boxer的文章,我才真正理解这种算法。下面,我用自己的语言,试图写一篇比较好懂的KMP算法解释。
1.
首先,字符串"BBC ABCDAB ABCDABCDABDE"的第一个字符与搜索词"ABCDABD"的第一个字符,进行比较。因为B与A不匹配,所以搜索词后移一位。
2.
因为B与A不匹配,搜索词再往后移。
3.
就这样,直到字符串有一个字符,与搜索词的第一个字符相同为止。
4.
接着比较字符串和搜索词的下一个字符,还是相同。
5.
直到字符串有一个字符,与搜索词对应的字符不相同为止。
6.
这时,最自然的反应是,将搜索词整个后移一位,再从头逐个比较。这样做虽然可行,但是效率很差,因为你要把"搜索位置"移到已经比较过的位置,重比一遍。
7.
一个基本事实是,当空格与D不匹配时,你其实知道前面六个字符是"ABCDAB"。KMP算法的想法是,设法利用这个已知信息,不要把"搜索位置"移回已经比较过的位置,继续把它向后移,这样就提高了效率。
8.
怎么做到这一点呢?可以针对搜索词,算出一张《部分匹配表》(Partial Match Table)。这张表是如何产生的,后面再介绍,这里只要会用就可以了。
9.
已知空格与D不匹配时,前面六个字符"ABCDAB"是匹配的。查表可知,最后一个匹配字符B对应的"部分匹配值"为2,因此按照下面的公式算出向后移动的位数:
移动位数 = 已匹配的字符数 - 对应的部分匹配值
因为 6 - 2 等于4,所以将搜索词向后移动4位。
10.
因为空格与C不匹配,搜索词还要继续往后移。这时,已匹配的字符数为2("AB"),对应的"部分匹配值"为0。所以,移动位数 = 2 - 0,结果为 2,于是将搜索词向后移2位。
11.
因为空格与A不匹配,继续后移一位。
12.
逐位比较,直到发现C与D不匹配。于是,移动位数 = 6 - 2,继续将搜索词向后移动4位。
13.
逐位比较,直到搜索词的最后一位,发现完全匹配,于是搜索完成。如果还要继续搜索(即找出全部匹配),移动位数 = 7 - 0,再将搜索词向后移动7位,这里就不再重复了。
14.
下面介绍《部分匹配表》是如何产生的。
首先,要了解两个概念:"前缀"和"后缀"。 "前缀"指除了最后一个字符以外,一个字符串的全部头部组合;"后缀"指除了第一个字符以外,一个字符串的全部尾部组合。
15.
"部分匹配值"就是"前缀"和"后缀"的最长的共有元素的长度。以"ABCDABD"为例,
- "A"的前缀和后缀都为空集,共有元素的长度为0; - "AB"的前缀为[A],后缀为,共有元素的长度为0; - "ABC"的前缀为[A, AB],后缀为[BC, C],共有元素的长度0; - "ABCD"的前缀为[A, AB, ABC],后缀为[BCD, CD, D],共有元素的长度为0; - "ABCDA"的前缀为[A, AB, ABC, ABCD],后缀为[BCDA, CDA, DA, A],共有元素为"A",长度为1; - "ABCDAB"的前缀为[A, AB, ABC, ABCD, ABCDA],后缀为[BCDAB, CDAB, DAB, AB, B],共有元素为"AB",长度为2; - "ABCDABD"的前缀为[A, AB, ABC, ABCD, ABCDA, ABCDAB],后缀为[BCDABD, CDABD, DABD, ABD, BD, D],共有元素的长度为0。
16.
"部分匹配"的实质是,有时候,字符串头部和尾部会有重复。比如,"ABCDAB"之中有两个"AB",那么它的"部分匹配值"就是2("AB"的长度)。搜索词移动的时候,第一个"AB"向后移动4位(字符串长度-部分匹配值),就可以来到第二个"AB"的位置。
转载地址:http://developer.51cto.com/art/201305/392555_all.htm
二、
[b]1、传统的字符串匹配算法
/*
* 从s中第sIndex位置开始匹配p
* 若匹配成功,返回s中模式串p的起始index
* 若匹配失败,返回-1
*/
int index(const std::string &s, const std::string &p, const int sIndex = 0)
{
int i = sIndex, j = 0;
if (s.length() < 1 || p.length() < 1 || sIndex < 0)
{
return -1;
}
while (i != s.length() && j != p.length())
{
if (s[i] == p[j])
{
++i;
++j;
}
else
{
i = i - j + 1;
j = 0;
}
}
return j == p.length() ? i - j: -1;
}2、[b]传统字符串匹配算法的性能问题[/b]
用模式串P去匹配字符串S,在i=6,j=4时发生失配:
i=6
S: a b a b c a d c a c b a b
P: a b c a c
j=4
此时,按照传统算法,应当将P的第 1 个字符 a(j=0) 滑动到与S中第4个字符 b(i=3) 对齐再进行匹配:
i=3
S: a b a b c a a d a c b a b
P: a b c a c
j=0
这个过程中,对字符串S的访问发生了“回朔”(从 i=6 移回到 i=3)。
我们不希望发生这样的回朔,而是试图通过尽可能的“向右滑动”模式串P,让P中index为 j 的字符对齐到S中 i=5 的字符,然后试图匹配S中 i=6 的字符与P中index为 j+1 的字符。
在这个测试用例中,我们直接将P向右滑动3个字符,使S中 i=5 的字符与P中 j=0 的字符对齐,再匹配S中 i=6 的字符与P中 j=1 的字符。
i=6
S: a b a b c a d c a c b a b
P: a
b c a c
j=0
3、kmp算法的一般性讨论
下面讨论在一般性的情况下,如何实现在“不回朔”访问S、仅依靠“滑动”P的前提下实现字符串匹配,即“kmp算法”。
i=6
S: a b a b c a d c a c b a b
P: a b c a c
k=1
i=6
S: a b a b c a d c a c b a b
P: a b c a c
j=4
对于任意的S和P,当S中index为 i 的字符和P中index为 j 的字符失配时,我们假定应当滑动P使其index为 k 的字符与S中index为 i 的字符“对齐”并继续比较。
那么,这个 k 是多少?
我们知道,所谓的对齐,就是要让S和P满足以下条件(上图中的蓝色字符):
……(1)
另一方面,在失配时我们已经有了一些部分匹配结果(上图中的绿色字符):
……(2)
由(1)、(2)可以得到:
……(3)
即如下图所示效果:
定义next[j]=k,k表示当模式串P中index为 j 的字符与主串S中index为 i 的字符发生失配时,应将P中index为 k 的字符继续与主串S中index为 i 的字符比较。
……(4)
按上述定义给出next数组的一个例子:
j 0 1 2 3 4 5 6 7
P a b a a b c a c
next[j] -1 0 0 1 1 2 0 1
在已知next数组的前提下,字符串匹配的步骤如下:
i 和 j 分别表示在主串S和模式串P中当前正待比较的字符的index,i 的初始值为sIndex,j 的初始值为0。
在匹配过程中的每一次循环,若
,i 和 j 分别增 1,
else,j 退回到 next[j]的位置,此时下一次循环是
与
相比较。
4、kmp算法的实现
在已知next函数的前提下,根据上面的步骤,kmp算法的实现如下:
int kmp(const std::string& s, const std::string& p, const int sIndex = 0)
{
std::vector<int>next(p.size());
getNext(p, next);//获取next数组,保存到vector中
int i = sIndex, j = 0;
while(i != s.length() && j != p.length())
{
if (j == -1 || s[i] == p[j])
{
++i;
++j;
}
else
{
j = next[j];
}
}
return j == p.length() ? i - j: -1;
}ok,下面的问题是怎么求模式串 P 的next数组。
next数组的初始条件是next[0] = -1,设next[j] = k,则有:
那么,next[j+1]有两种情况:
①
,则有:
此时next[j+1] = next[j] + 1 = k + 1
②
, 如图所示:
此时需要将P向右滑动之后继续比较P中index为 j 的字符与index为 next[k] 的字符:
值得注意的是,上面的“向右滑动”本身就是一个kmp在失配情况下的滑动过程,将这个过程看 P 的自我匹配,则有:
如果
,则next[j+1] = next[k] + 1;
否则,继续将 P 向右滑动,直至匹配成功,或者不存在这样的匹配,此时next[j+1] = 0。
getNext函数的实现如下:
void getNext(const std::string &p, std::vector<int> &next)
{
next.resize(p.size());
next[0] = -1;
int i = 0, j = -1;
while (i != p.size() - 1)
{
//这里注意,i==0的时候实际上求的是next[1]的值,以此类推
if (j == -1 || p[i] == p[j])
{
++i;
++j;
next[i] = j;
}
else
{
j = next[j];
}
}
}至此,一个完整的kmp已经实现。
5、getNext函数的进一步优化
注意到,上面的getNext函数还存在可以优化的地方,比如:
i=3
S: a a a
b a a a a b
P: a a a
a b
j=3
此时,i=3、j=3时发生失配,next[3]=2,此时还需要进行 3 次比较:
i=3, j=2;
i=3, j=1;
i=3, j=0。
而实际上,因为i=3, j=3时就已经知道a!=b,而之后的三次依旧是拿 a 和 b 比较,因此这三次比较都是多余的。
此时应当直接将P向右滑动4个字符,进行 i=4, j=0的比较。
一般而言,在getNext函数中,next[i]=j,也就是说当p[i]与S中某个字符匹配失败的时候,用p[j]继续与S中的这个字符比较。
如果p[i]==p[j],那么这次比较是多余的(如同上面的例子),此时应该直接使next[i]=next[j]。
完整的实现代码如下:
void getNextUpdate(const std::string& p, std::vector<int>& next)
{
next.resize(p.size());
next[0] = -1;
int i = 0, j = -1;
while (i != p.size() - 1)
{
//这里注意,i==0的时候实际上求的是nextVector[1]的值,以此类推
if (j == -1 || p[i] == p[j])
{
++i;
++j;
//update
//next[i] = j;
//注意这里是++i和++j之后的p[i]、p[j]
next[i] = p[i] != p[j] ? j : next[j];
}
else
{
j = next[j];
}
}
}对应的,只需要在kmp算法中将 getNext(p, next); 替换成 getNextUpdate(p, next); 即可。
6、时间复杂度分析
下面以getNext函数为例,分析kmp算法的时间复杂度。
1 void getNext(const std::string& p, std::vector<int>& next)
2 {
3 next.resize(p.size());
4 next[0] = -1;
5
6 int i = 0, j = -1;
7
8 while (i != p.size() - 1)
9 {
10 if (j == -1 || p[i] == p[j])
11 {
12 ++i;
13 ++j;
14 next[i] = j;
15 }
16 else
17 {
18 j = next[j];
19 }
20 }
21 }假定p.size()为m,分析其时间复杂度的困惑在于,在while里面不是每次循环都执行 ++i 操作,所以整个while的执行次数不一定为m。
换个角度,注意到在每次循环中,无论 if 还是 else 都会修改 j 的值且每次循环仅对 j 进行一次修改,所以在整个while中 j 被修改的次数即为getNext函数的时间复杂度。
每次成功匹配时,++i; ++j; , 由于 ++i 最多执行 m-1 次,故++j也最多执行 m-1 次,即 j 最多增加m-1次;
对应的,只有在 j=next[j]; 处 j 的值一定会变小,由于 j 最多增加m-1次,故 j 最多减小m-1次。
综上所述,getNext函数的时间复杂度为O(m),若带匹配串S的长度为n,则kmp函数的时间负责度为O(m+n)。
7、kmp的应用优势
①快,O(m+n)的线性最坏时间复杂度;
②无需回朔访问待匹配字符串S,所以对处理从外设输入的庞大文件很有效,可以边读入边匹配。

相关文章推荐
- Number 类型
- redis作为mysql的缓存服务器(读写分离)
- 安卓图片下载
- 数据库SQL优化大总结
- ionicAPP发布问题
- iOS-NSTimer定时器总结
- 【解题报告】传球游戏
- (总结)Nginx配置文件nginx.conf中文详解
- ZOJ1016-Parencodings
- ELK
- git学习笔记(三)
- Linux周期性自动发送邮件
- 如果在docker中部署tomcat,并且部署java应用程序
- fastjson解析JSON数据
- document.write()相关
- 如果在docker中部署tomcat,并且部署java应用程序
- 阿里云IE测试地址
- Boolean 相关
- Struct2或者SSH项目中,在JSP页面显示Action中注册的错误信息
- Oracle日志清理