DP备份任务失败原因解析
2016-01-27 15:47
453 查看
以JDC为例,DP的备份任务失败troubleshooting流程为:
1)/etc/opt/omni/server/datalist下都是备份的job code。
如果要查看一个job code,可以more 此文件夹下的某个datalist,输入如下:
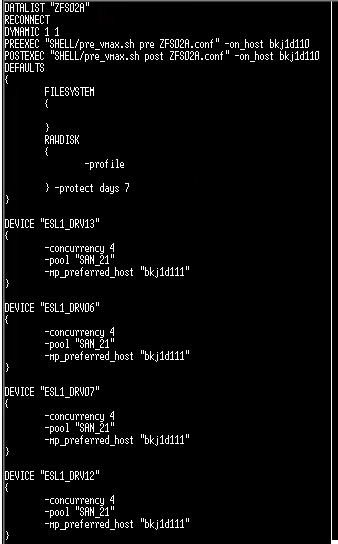
最上面的两个脚本pre和post,内容是一样的,都是check split,开始查一遍,最后再查一遍。
下面的ESL_1DRV13到12是执行此job的drive优先顺序,默认的是dr13优先,如果执行job时这个dr busy,就会按顺序再往下找,直到找到合适的,如下图所示,这种情况虽然job仍然可以ok执行,但是会报错,会被打电话通知.
2016/1/29更新:
如果drive busy,查看drive状态的命令:
#/UMA 1/2/3 [带库ID]
#stat d
能看到full 还是 empty
2)monidb -session [session ID] -report
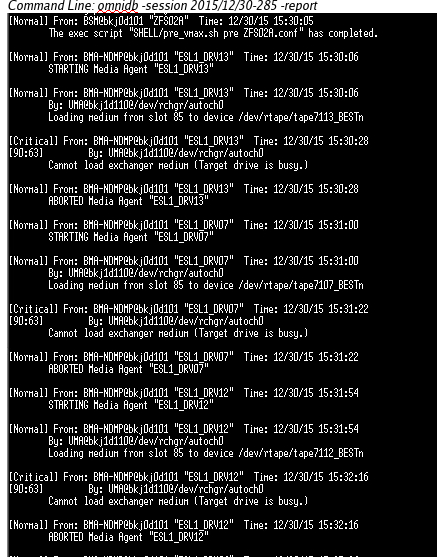
上图有一个输出是:loading media frm slot 85 to device /dev/rtape/tape711_bestn,这个是说从85槽调磁带到drive.
3)/home/work/cs 30/grep [session ID],或者进到/home/work下,./cs 30 |grep [session ID/datalist]

上面这种情况会出现报错.如上图,complete/failure,但是按第二步的命令monidb -session [session ID] -report会有下面的输出:
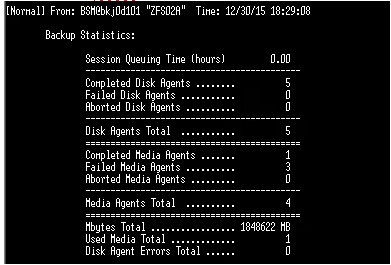
会看到其实是complete ok的,所以force ok 就可以了。
总结其实就是more /etc/opt/omni/server/datalist/[ID] 和/home/work/cs|grep session/datalist ID 这俩命令配合来看。
4)按照第二步的命令,omnidb -session [session id] -report,有时会出现下面的报错:
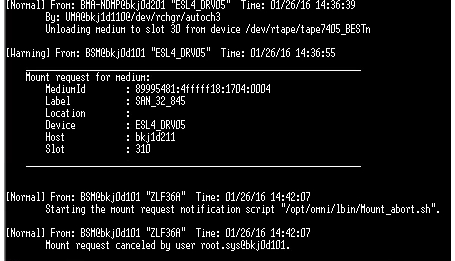
这种mount request cancel的报错一般就是磁带不够的意思。
5)针对未分离而报错的copy的处理方法:
还是根据命令omnidb -session 【session ID】-report,会有下面的报错:
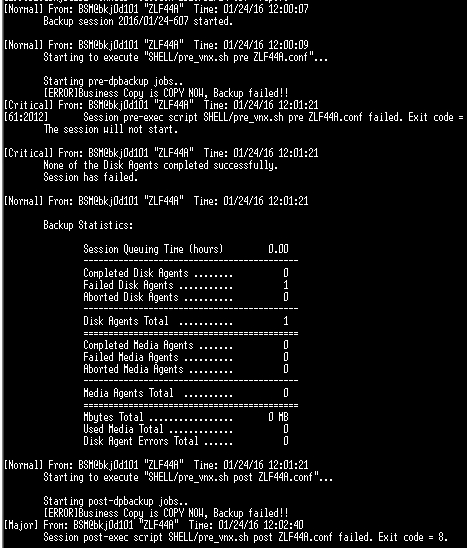
在最前面说的pre和post这两个脚本是检查是否split的,这个就是在最初执行pre时发现还未分离,即还在copy状态,所以报错,这时需要手动执行分离操作,命令为:
/opt/Navisphere/bin/naviseccli -user sysadmin -password sysadmin -address 【IP】 -scope 0 snapview -fractureclone -name CLONE_ID -cloneid 0100000000000000
然后通知chops rerun这个任务。
1)/etc/opt/omni/server/datalist下都是备份的job code。
如果要查看一个job code,可以more 此文件夹下的某个datalist,输入如下:
最上面的两个脚本pre和post,内容是一样的,都是check split,开始查一遍,最后再查一遍。
下面的ESL_1DRV13到12是执行此job的drive优先顺序,默认的是dr13优先,如果执行job时这个dr busy,就会按顺序再往下找,直到找到合适的,如下图所示,这种情况虽然job仍然可以ok执行,但是会报错,会被打电话通知.
2016/1/29更新:
如果drive busy,查看drive状态的命令:
#/UMA 1/2/3 [带库ID]
#stat d
能看到full 还是 empty
2)monidb -session [session ID] -report
上图有一个输出是:loading media frm slot 85 to device /dev/rtape/tape711_bestn,这个是说从85槽调磁带到drive.
3)/home/work/cs 30/grep [session ID],或者进到/home/work下,./cs 30 |grep [session ID/datalist]
上面这种情况会出现报错.如上图,complete/failure,但是按第二步的命令monidb -session [session ID] -report会有下面的输出:
会看到其实是complete ok的,所以force ok 就可以了。
总结其实就是more /etc/opt/omni/server/datalist/[ID] 和/home/work/cs|grep session/datalist ID 这俩命令配合来看。
4)按照第二步的命令,omnidb -session [session id] -report,有时会出现下面的报错:
这种mount request cancel的报错一般就是磁带不够的意思。
5)针对未分离而报错的copy的处理方法:
还是根据命令omnidb -session 【session ID】-report,会有下面的报错:
在最前面说的pre和post这两个脚本是检查是否split的,这个就是在最初执行pre时发现还未分离,即还在copy状态,所以报错,这时需要手动执行分离操作,命令为:
/opt/Navisphere/bin/naviseccli -user sysadmin -password sysadmin -address 【IP】 -scope 0 snapview -fractureclone -name CLONE_ID -cloneid 0100000000000000
然后通知chops rerun这个任务。

相关文章推荐
- c#定时器和global实现自动job示例
- 关于开源项目《Scavenger》
- 北京小易到家研发部招聘---高级java工程师
- 19e平台研发中心招聘---高级Java工程师
- Smarty --roles of template designer and programmer
- SaltStack Job 管理 及 saltutil.signal_job 模块的问题
- job requirements
- oracle job 设置自动执行,执行错误,如何解决呢?
- Mysql Event SCHEDULE Job 定时任务
- java job(spring)
- Java job 定时器
- 创建ORACLE JOB
- oracle 定时器
- sql server 2005 代理作业
- oracle 创建job
- oracle定时任务以及DBLink创建
- dbms_scheduler包中job(作业)学习
- job的使用
- 多个mapreduce过程的组合模式