spark yarn-client和yarn-cluster
2016-01-25 09:56
411 查看
大数据系列零基础由入门到实战视频
| 问题导读 1.Spark在YARN中有几种模式? 2.Yarn Cluster模式,Driver程序在YARN中运行,应用的运行结果在什么地方可以查看? 3.由client向ResourceManager提交请求,并上传jar到HDFS上包含哪些步骤? 4.传递给app的参数应该通过什么来指定? 5.什么模式下最后将结果输出到terminal中?  [align=left]Spark在YARN中有yarn-cluster和yarn-client两种运行模式:[/align] I. Yarn Cluster Spark Driver首先作为一个ApplicationMaster在YARN集群中启动,客户端提交给ResourceManager的每一个job都会在集群的worker节点上分配一个唯一的ApplicationMaster,由该ApplicationMaster管理全生命周期的应用。因为Driver程序在YARN中运行,所以事先不用启动Spark Master/Client,应用的运行结果不能在客户端显示(可以在history server中查看),所以最好将结果保存在HDFS而非stdout输出,客户端的终端显示的是作为YARN的job的简单运行状况。 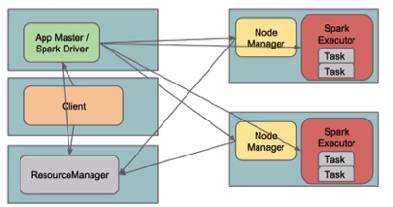 by @Sandy Ryza  by 明风@taobao 从terminal的output中看到任务初始化更详细的四个步骤: 14/09/28 11:24:52 INFO RMProxy: Connecting to ResourceManager at hdp01/172.19.1.231:8032 14/09/28 11:24:52 INFO Client: Got Cluster metric info from ApplicationsManager (ASM), number of NodeManagers: 4 14/09/28 11:24:52 INFO Client: Queue info ... queueName: root.default, queueCurrentCapacity: 0.0, queueMaxCapacity: -1.0, queueApplicationCount = 0, queueChildQueueCount = 0 14/09/28 11:24:52 INFO Client: Max mem capabililty of a single resource in this cluster 8192 14/09/28 11:24:53 INFO Client: Uploading file:/usr/lib/spark/examples/lib/spark-examples_2.10-1.0.0-cdh5.1.0.jar to hdfs://hdp01:8020/user/spark/.sparkStaging/application_1411874193696_0003/spark-examples_2.10-1.0.0-cdh5.1.0.jar 14/09/28 11:24:54 INFO Client: Uploading file:/usr/lib/spark/assembly/lib/spark-assembly-1.0.0-cdh5.1.0-hadoop2.3.0-cdh5.1.0.jar to hdfs://hdp01:8020/user/spark/.sparkStaging/application_1411874193696_0003/spark-assembly-1.0.0-cdh5.1.0-hadoop2.3.0-cdh5.1.0.jar 14/09/28 11:24:55 INFO Client: Setting up the launch environment 14/09/28 11:24:55 INFO Client: Setting up container launch context 14/09/28 11:24:55 INFO Client: Command for starting the Spark ApplicationMaster: List($JAVA_HOME/bin/java, -server, -Xmx512m, -Djava.io.tmpdir=$PWD/tmp, -Dspark.master="spark://hdp01:7077", -Dspark.app.name="org.apache.spark.examples.SparkPi", -Dspark.eventLog.enabled="true", -Dspark.eventLog.dir="/user/spark/applicationHistory", -Dlog4j.configuration=log4j-spark-container.properties, org.apache.spark.deploy.yarn.ApplicationMaster, --class, org.apache.spark.examples.SparkPi, --jar , file:/usr/lib/spark/examples/lib/spark-examples_2.10-1.0.0-cdh5.1.0.jar, , --executor-memory, 1024, --executor-cores, 1, --num-executors , 2, 1>, <LOG_DIR>/stdout, 2>, <LOG_DIR>/stderr) 14/09/28 11:24:55 INFO Client: Submitting application to ASM 14/09/28 11:24:55 INFO YarnClientImpl: Submitted application application_1411874193696_0003 14/09/28 11:24:56 INFO Client: Application report from ASM: application identifier: application_1411874193696_0003 appId: 3 clientToAMToken: null appDiagnostics: appMasterHost: N/A appQueue: root.spark appMasterRpcPort: -1 appStartTime: 1411874695327 yarnAppState: ACCEPTED distributedFinalState: UNDEFINED appTrackingUrl: http://hdp01:8088/proxy/application_1411874193696_0003/ appUser: spark 复制代码 1. 由client向ResourceManager提交请求,并上传jar到HDFS上 这期间包括四个步骤: a). 连接到RM b). 从RM ASM(ApplicationsManager )中获得metric、queue和resource等信息。 c). upload app jar and spark-assembly jar d). 设置运行环境和container上下文(launch-container.sh等脚本) 2. ResouceManager向NodeManager申请资源,创建Spark ApplicationMaster(每个SparkContext都有一个ApplicationMaster) 3. NodeManager启动Spark App Master,并向ResourceManager AsM注册 4. Spark ApplicationMaster从HDFS中找到jar文件,启动DAGscheduler和YARN Cluster Scheduler 5. ResourceManager向ResourceManager AsM注册申请container资源(INFO YarnClientImpl: Submitted application) 6. ResourceManager通知NodeManager分配Container,这时可以收到来自ASM关于container的报告。(每个container的对应一个executor) 7. Spark ApplicationMaster直接和container(executor)进行交互,完成这个分布式任务。 需要注意的是: a). Spark中的localdir会被yarn.nodemanager.local-dirs替换 b). 允许失败的节点数(spark.yarn.max.worker.failures)为executor数量的两倍数量,最小为3. c). SPARK_YARN_USER_ENV传递给spark进程的环境变量 d). 传递给app的参数应该通过–args指定。 部署: 环境介绍: hdp0[1-4]四台主机 hadoop使用CDH 5.1版本: hadoop-2.3.0+cdh5.1.0+795-1.cdh5.1.0.p0.58.el6.x86_64 直接下载对应2.3.0的pre-build版本http://spark.apache.org/downloads.html 下载完毕后解压,检查spark-assembly目录: file /home/spark/spark-1.1.0-bin-hadoop2.3/lib/spark-assembly-1.1.0-hadoop2.3.0.jar /home/spark/spark-1.1.0-bin-hadoop2.3/lib/spark-assembly-1.1.0-hadoop2.3.0.jar: Zip archive data, at least v2.0 to extract 复制代码 然后输出环境变量HADOOP_CONF_DIR/YARN_CONF_DIR和SPARK_JAR(可以设置到spark-env.sh中) export HADOOP_CONF_DIR=/etc/hadoop/etc export SPARK_JAR=/home/spark/spark-1.1.0-bin-hadoop2.3/lib/spark-assembly-1.1.0-hadoop2.3.0.jar 复制代码 如果使用cloudera manager 5,在Spark Service的操作中可以找到Upload Spark Jar将spark-assembly上传到HDFS上。 
spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster /usr/lib/spark/examples/lib/spark-examples_2.10-1.0.0-cdh5.1.0.jar 复制代码 II. yarn-client (YarnClientClusterScheduler)查看对应类的文件 在yarn-client模式下,Driver运行在Client上,通过ApplicationMaster向RM获取资源。本地Driver负责与所有的executor container进行交互,并将最后的结果汇总。结束掉终端,相当于kill掉这个spark应用。一般来说,如果运行的结果仅仅返回到terminal上时需要配置这个。 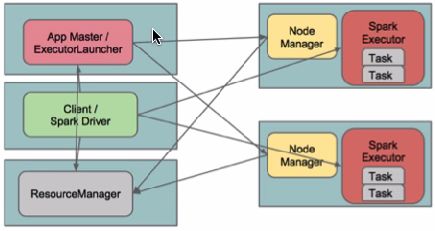 客户端的Driver将应用提交给Yarn后,Yarn会先后启动ApplicationMaster和executor,另外ApplicationMaster和executor都 是装载在container里运行,container默认的内存是1G,ApplicationMaster分配的内存是driver- memory,executor分配的内存是executor-memory。同时,因为Driver在客户端,所以程序的运行结果可以在客户端显 示,Driver以进程名为SparkSubmit的形式存在。 配置YARN-Client模式同样需要HADOOP_CONF_DIR/YARN_CONF_DIR和SPARK_JAR变量。 提交任务测试: spark-submit --class org.apache.spark.examples.SparkPi --deploy-mode client /usr/lib/spark/examples/lib/spark-examples_2.10-1.0.0-cdh5.1.0.jar terminal output: 14/09/28 11:18:34 INFO Client: Command for starting the Spark ApplicationMaster: List($JAVA_HOME/bin/java, -server, -Xmx512m, -Djava.io.tmpdir=$PWD/tmp, -Dspark.tachyonStore.folderName="spark-9287f0f2-2e72-4617-a418-e0198626829b", -Dspark.eventLog.enabled="true", -Dspark.yarn.secondary.jars="", -Dspark.driver.host="hdp01", -Dspark.driver.appUIHistoryAddress="", -Dspark.app.name="Spark Pi", -Dspark.jars="file:/usr/lib/spark/examples/lib/spark-examples_2.10-1.0.0-cdh5.1.0.jar", -Dspark.fileserver.uri="http://172.19.17.231:53558", -Dspark.eventLog.dir="/user/spark/applicationHistory", -Dspark.master="yarn-client", -Dspark.driver.port="35938", -Dspark.httpBroadcast.uri="http://172.19.17.231:43804", -Dlog4j.configuration=log4j-spark-container.properties, org.apache.spark.deploy.yarn.ExecutorLauncher, --class, notused, --jar , null, --args 'hdp01:35938' , --executor-memory, 1024, --executor-cores, 1, --num-executors , 2, 1>, <LOG_DIR>/stdout, 2>, <LOG_DIR>/stderr) 14/09/28 11:18:34 INFO Client: Submitting application to ASM 14/09/28 11:18:34 INFO YarnClientSchedulerBackend: Application report from ASM: appMasterRpcPort: -1 appStartTime: 1411874314198 yarnAppState: ACCEPTED ...... 复制代码 [align=left]##最后将结果输出到terminal中[/align] [align=left]转自:http://www.aboutyun.com/thread-12294-1-1.html[/align] |

相关文章推荐
- 从技术细节看美团的架构
- iOS开发笔记--iOS开发 使用NSUserDefaults 保存数据
- 线段树区间合并(POJ 3667 Hotel ,HDU HDU3308 LCIS)
- 主动噪声控制方向期刊
- 局部敏感哈希(原始LSH)C++实现
- java提高篇(十二)-----equals()
- Go语言使用CGO获取Windows的CPU使用率
- JS/JQ用法小總
- IOS开发用户登录注册模块所遇到的问题
- CityHorizon-线段树
- Swift中文教程(九) 类与结构
- nyoj2
- mfc常见面试题
- iOS开发笔记--声明全局变量
- X-UA-Compatible IE=edge,chrome=1
- MySQL InnoDB存储引擎
- UE4 代码编写细节:静态变量
- 模板方法模式
- python-dict
- openstack各个组件功能