DIY简单功能的torrentkitty种子爬虫
2016-01-23 17:47
253 查看
过完年回公司比较无聊,一不小心看到微博里美尤莉娅的图片,惊为天人,有图为证!!!

百度之原来这货以前叫小泉彩,貌似动了几个小手术换了个马甲重新出道了。你拍AV你家里知道么?。于是乎下了几个种子看了下,感觉还行(像苍老师什么的我真的没有看过哈哈),狠一点把全集全搞到百度网盘上。
貌似这货拍了200多部,真不少。人工学习了下,torrentkitty的种子貌似还是蛮全的。搜一下关键字11页,接近200+个结果,这一个一个ctrl+c ctrl+v这不得直接导致键盘+鼠标手。祭出FIREBUG+PYTHON,写个爬虫把地址全部搞出来。因为目的比较单纯和纯洁,所以就不用SCRAPY这么大型的东西了。效率第一。
FIREBUG看了下结构,目标的XPATH在/html/body/div[4]/div/table/tbody/tr[2]/td[4]/a[2],直接LXML把地址抓出来只需要一行代码,SO EASY!!

动手开始写,整个过程只用了5分钟,PYTHON真是太方便了。
代码如下:
import urllib2
from lxml import etree
url='http://www.torrentkitty.com/search/'
keyword='%e9%87%8c%e7%be%8e'
pages=11
for page in range(0,pages):
page=str(page)
site=url+keyword+'/'+page
h=urllib2.Request(site)
h.add_header('User-Agent', 'Mozilla/5.0 (Windows; U; Windows NT 5.1;
zh-CN; rv:1.8.1.14) Gecko/20080404 (FoxPlus) Firefox/2.0.0.14')
ht=urllib2.urlopen(h)
html=ht.read(ht)
content=etree.HTML(html.lower().decode('utf-8'))
mags=content.xpath("//a[@rel='magnet']")
for mag in mags:
print "%s \n \n"%(mag.attrib['href'])
KEYWORD是搜索的关键字的URL编码,PAGES是该关键字的页数总数。改好之后直接>>写到TXT里就是了。以后有时间写个自动递交到百度网盘离线下载的。
嗯哼,别问我是谁,我是手拿杜蕾斯戴着红领巾的雷锋同志!!


百度之原来这货以前叫小泉彩,貌似动了几个小手术换了个马甲重新出道了。你拍AV你家里知道么?。于是乎下了几个种子看了下,感觉还行(像苍老师什么的我真的没有看过哈哈),狠一点把全集全搞到百度网盘上。
貌似这货拍了200多部,真不少。人工学习了下,torrentkitty的种子貌似还是蛮全的。搜一下关键字11页,接近200+个结果,这一个一个ctrl+c ctrl+v这不得直接导致键盘+鼠标手。祭出FIREBUG+PYTHON,写个爬虫把地址全部搞出来。因为目的比较单纯和纯洁,所以就不用SCRAPY这么大型的东西了。效率第一。
FIREBUG看了下结构,目标的XPATH在/html/body/div[4]/div/table/tbody/tr[2]/td[4]/a[2],直接LXML把地址抓出来只需要一行代码,SO EASY!!
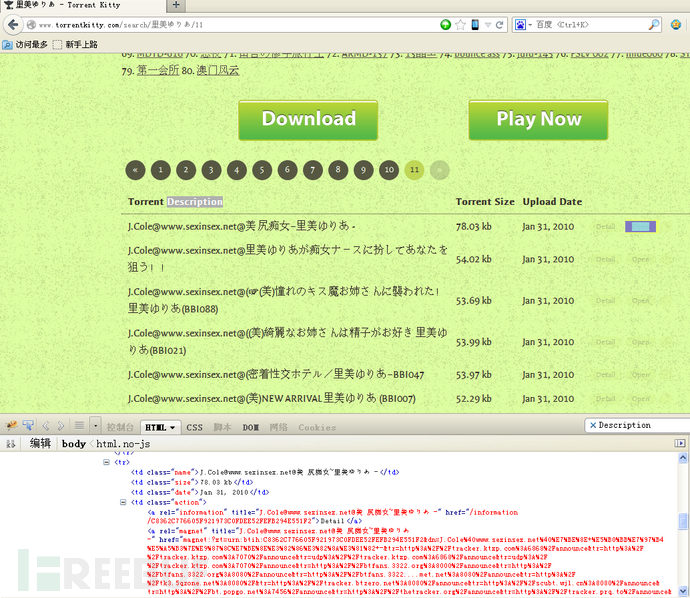
动手开始写,整个过程只用了5分钟,PYTHON真是太方便了。
代码如下:
import urllib2
from lxml import etree
url='http://www.torrentkitty.com/search/'
keyword='%e9%87%8c%e7%be%8e'
pages=11
for page in range(0,pages):
page=str(page)
site=url+keyword+'/'+page
h=urllib2.Request(site)
h.add_header('User-Agent', 'Mozilla/5.0 (Windows; U; Windows NT 5.1;
zh-CN; rv:1.8.1.14) Gecko/20080404 (FoxPlus) Firefox/2.0.0.14')
ht=urllib2.urlopen(h)
html=ht.read(ht)
content=etree.HTML(html.lower().decode('utf-8'))
mags=content.xpath("//a[@rel='magnet']")
for mag in mags:
print "%s \n \n"%(mag.attrib['href'])
KEYWORD是搜索的关键字的URL编码,PAGES是该关键字的页数总数。改好之后直接>>写到TXT里就是了。以后有时间写个自动递交到百度网盘离线下载的。
嗯哼,别问我是谁,我是手拿杜蕾斯戴着红领巾的雷锋同志!!


相关文章推荐
- XSS获取cookie并利用
- 使用UEFI+GPT模式安装Windows
- Fiddler 教程
- 一次xss的黑盒挖掘和利用过程
- Android App 注射&&Drozer Use
- Burp Suite使用介绍总结
- php截取后台登陆密码的代码
- 通用型正方教务(通杀各版本)存在注入(不需登陆)+获得webshell+提权内网漫游
- 密码重置漏洞案例
- post注入及提权思路
- MySQL提权之user.MYD中hash破解方法
- 导出当前域内所有用户hash的技术整理
- 在远程系统上执行程序的技术整理
- 内网渗透中的mimikatz
- Linux下中间人攻击利用框架bettercap测试
- Metasploit渗透技巧:后渗透Meterpreter代理
- 第17章 标准库特殊设施
- linux服务器安全配置10大技巧
- win环境下使用sqlmap写shell + MYSQL提权(默认就是system权限)
- nmap速查表v1.0(中文版)