计网-ch03-题目与解释
2016-01-15 11:38
435 查看
复习题
6.请描述应用程序开发者为什么更倾向于选择在UDP上运行应用程序而不是TCP。ANS:
应用程序开发者可能不想其应用程序使用TCP的拥塞控制,因为这会在出现拥塞时降低应用程序的传输速率。通常,IP电话和IP视频会议应用程序的设计者选择让他们的应用程序运行在UDP上,因为他们想要避免TCP的拥塞控制。还有,一些应用不需要TCP提供的可靠数据传输。
选路和转发的区别
ANS:
路由是根据路由表查找到达目标网络的最佳路由表项,转发是根据最佳路由中的出口及下一跳IP转发数据包的过程。因此,路由选择是转发的基础,数据转发是路由的结果。
7.假定主机C上的一个进程有一个端口号6789的UDP套接字。假定主机A和主机B都用目的端口号6789向主机C发送一个UDP报文段。这两台主机的这些报文段在主机C上都被描述为相同的套接字吗?如果是这样的话,主机C上的进程是怎样区分源于两台不同主机的两个报文段的?
ANS:
是为相同的套接字,For each received segment, at the socket interface, the operating system will provide the process with the IP addresses to determine the origins of the individual segments.
8. 假定在主机C的端口80上运行一个Web服务器。假定这个Web服务器使用持久连接,并且正在接受来自两台不同主机A和B的请求。被发送的所有请求都通过位于主机C的相同套接字吗?如果它们通过不同的套接字来传递,这两个套接字都具有端口80吗?讨论和解释之。
ANS:
Web服务器是使用TCP连接,Web服务器对于不同的连接采用的是不同的套接字,因此A和B发出的请求通过的是在主机C不同的套接字上的,TCP连接的套接字是个四元组,由(源IP,源端口号,目标IP,目标端口号)组成,主机A和主机B都是向主机C 80端口上的Web服务器发出TCP连接请求,这两个套接字的目标端口号都是80,目标IP都是主机C的IP地址,因此这两个套接字中都具有端口号80。
9.在rdt协议中,为什么要引入序号
ANS:
序号是为了解决冗余分组问题。在rdt2.0协议中,由于假设信道中可能发生比特差错,发送方根据接收方反馈信息的肯定确认(ACK)或否定确认(NAK)来确定分组是否被正确的接收,若分组没有被正确的接收,即收到NAK反馈则重传该分组,但是ACK与NAK本身会发生差错,而通常情况下处理受损ACK或NAK的方法是,当发送方收到含糊不清的ACK或NAK时,只需重发当前数据分组即可。这就是冗余分组,发送方无法事先知道接收到的分组是新的还是又一次重传。因此,在数据分组中添加一新字段,即序号,让发送方对其数据分组编号,于是,接收方只需检查序号即可确定收到的分组是否是一次重传。
10.在rdt协议中,为什么需要引入定时器
ANS:
在数据传送的过程中可能会发生丢包的情况,解决丢包的方法有很多种,而rdt3.0中采用的是让发送方负责检测和恢复丢包。假定发送方传输一个数据分组,或则该分组或接收方对该分组的ACK发生了丢失。这两种情况下,发送方都收不到应当到来的接收方的响应。如果发送方愿意等待足够长的时间以确定分组已丢失,则只需重传该数据分组即可。因此在rdt3.0中引入了定时器来确定发送方应该等待的时间,一旦超过了该定时器的时间,则发送方认为产生了丢包现象,再重发该分组。
14. 是非判断题
a. 主机A通过一条TCP连接向主机B发送一个大文件。假设主机B没有数据发往主机A。因为主机B不能随数据捎带确认信息,所以主机B将不向主机A发送确认。
b. 在连接的整个过程中,TCP的RcvWindow的长度不会变化
c. 假设主机A通过一条TCP连接向主机B发送一个大文件。主机A发送的未被确认的字节数不会超过接收缓存的大小
d. 假设主机A通过一条TCP连接向主机B发送一个大文件。如果对于这次连接的一个报文段序列号为m,则对于后继报文段的序列号必然为m+1
e. TCP报文段在它的首部中有一个RcvWindow字段
f. 假定在一条TCP连接中最后的SampleRTT等于1s,那么对于这一连接的TimeoutInterVal的当前值必定≥1s
g. 假定主机A通过一条TCP连接向主机B发送一个序号为38的4字节报文段。这个报文段的确认号必定是42
ANS:
a.错误;TCP连接中,如果主机B没有数据要发往主机,它就不能随数据捎带确认信息,但是,TCP要求B必须发送确认,因此B将向A发送非捎带的确认信息。
b.错误;TCP在全双工连接中,连接双方的发送方各自保留一个接收窗口以提供流量控制。接收窗口是动态的,在连接的整个生命周期中是不断变化的。
c. 正确。
d.错误;顺序号的设定是以传送的字节流为单位,而不是以报文段为单位。一个报文段的顺序号
是该报文段中数据段的第一个字节在字节流中的编号
e.正确
f.错误;超时时间是EstimatedRTT 和SampleRTT的函数,不能由一个SampleRTT值决定。
g.错误;某些情况下(比如该报文段发送超时)接收方会发送一个重复的ACK,即确认号仍然是 38。
15. 假设主机A通过一条TCP连接向主机B连续发送两个TCP报文段。第一个报文段的序号为90,第二个报文段的序号为110.
a. 第一个报文段中有多少数据
b. 假设第一个报文段丢失而第二个报文段到达主机B,那么在主机B发往主机A的捎带确认报文中,确认号应该是多少?
ANS:
a.因为TCP把数据看成一个无结构的但是有序的字节流。因此TCP的序号是建立在传送的字节流上的。因此在第一个报文段序号为90,第二个报文段序号为110的情况下,我们可推出第一个报文段中的数据大小为110-90=20 Bytes,即第一个报文段中有20个字节数据
b. 若第一个报文段丢失,则发送方会在
4000
一定时间后没有收到接收方的反馈确认包,因此接收方会发送一个重复的ACK,确认号为90。
16. 考虑3.5节中讨论的Telnet的例子。在键入字符C数秒之后,用户又键入字符R。那么在用户键入字符R之后,总共发送了多少个报文段?这些报文段中的序号和确认号字段应该填入什么?
ANS:
3 个报文段.
第一个报文段: seq = 43, ack =80;
第二个报文段: seq = 80, ack = 44;
第三个报文段: seq = 44, ack = 81
习题
3.UDP和TCP使用反码来计算检验和。假设有下面3个8比特字节:0101 0101,0111 0000,0100 1100.这些8比特字节和的反码是多少(注意到尽管UDP和TCP使用16比特的字来计算检验和,但对于这个问题,应考虑8比特和。)写出所有工作过程。UDP为什么要用该和的反码。即为什么不直接使用该和呢?使用该和反码方案,接收方如何检验出差错?1比特的差错将可能检测不出来吗?2比特的差错呢?ANS:
0101 0101 + 0111 0000 = 1100 0101
1100 0101 + 0100 1100 = 0001 0001
二进制反码为:1110 1110
检测错误,接收方添加四个字(原来的三个单词和校验和)。如果和包含一个0,接收方知道存在一个错误。1比特的差错可以被检测出来,但2比特的差错无法检测(例如,如果第一个单词最后的数字转换为0,第二个词的最后数字转换为1)。
18.考虑一个GBN协议,其发送方窗口长度为3,序号范围为1024.假设在时刻t,接收方期待的下一个有序分组的序号是k.假设其中的介质不会对报文重新排序。请回答以下问题:
a. 在t时刻,发送窗口内的报文序号可能是多少?论证你的回答
b. 在t时刻,在当前发送方收到的所有报文中,ACK字段的可能值是多少?论证你的回答
ANS:
a. Here we have a window size of N=3. Suppose the receiver has received packet k-1, and has ACKed that and all other preceeding packets. If all of these ACK’s have been received by sender, then sender’s window is [k, k+N-1]. Suppose next that none of the ACKs have been received at the sender. In this second case, the sender’s window contains k-1 and the N packets up to and including k-1. The sender’s window is thus [k-N,k-1]. By these arguments, the senders window is of size 3 and begins somewhere in the range [k-N,k].
b. If the receiver is waiting for packet k, then it has received (and ACKed) packet k-1 and the N-1 packets before that. If none of those N ACKs have been yet received by the sender, then ACK messages with values of [k-N,k-1] may still be propagating back.
Because the sender has sent packets [k-N, k-1], it must be the case that the sender has already received an ACK for k-N-1. Once the receiver has sent an ACK for k-N-1 it will never send an ACK that is less that k-N-1. Thus the range of in-flight ACK values can range from k-N-1 ~ k-1.
19.假定有两个网络实体A和B。B有一些数据报文要通过下列规则传给A:当A从其上一层得到一个请求时,就从B接收下一个数据(D)报文。A必须通过A到B信道向B发送一个请求(R)报文。仅当B收到一个R报文后,它才会通过B到A信道向A发送数据(D)报文。A应当将每份D报文的拷贝交付给上层。R报文可能会在A到B的信道中丢失(但不会损坏);D报文一旦发出总是能够正确交付。两个信道的时延未知且是变化的。
请设计一个协议(画出FSM),它能够综合适当的机制,以补偿A到B信道中可能出现的丢包,实现在A实体中向上层传递的报文。只采用绝对必要的机制。
ANS:
Because the A-to-B channel can lose request messages, A will need to timeout and retransmit its request messages (to be able to recover from loss). Because the channel delays are variable and unknown, it is possible that A will send duplicate requests (i.e., resend a request message that has already been received by B). To be able to detect duplicate request messages, the protocol will use sequence numbers. A 1-bit sequence number will suffice for a stop-and-wait type of request/response protocol.
A (the requestor) has 4 states:
“Wait for Request 0 from above.” Here the requestor is waiting for a call from above to request a unit of data. When it receives a request from above, it sends a request message, R0, to B, starts a timer and makes a transition to the “Wait for D0” state. When in the “Wait for Request 0 from above” state, A ignores anything it receives from B.
“Wait for D0”. Here the requestor is waiting for a D0 data message from B. A timer is always running in this state. If the timer expires, A sends another R0 message, restarts the timer and remains in this state. If a D0 message is received from B, A stops the time and transits to the“Wait for Request 1 from above” state. If A receives a D1 data message while in this state, it is ignored.
“Wait for Request 1 from above.” Here the requestor is again waiting for a call from above to request a unit of data. When it receives a request from above, it sends a request message, R1, to B, starts a timer and makes a transition to the “Wait for D1” state. When in the “Wait for Request 1 from above” state, A ignores anything it receives from B.
“Wait for D1”. Here the requestor is waiting for a D1 data message from B. A timer is always running in this state. If the timer expires, A sends another R1 message, restarts the timer and remains in this state. If a D1 message is received from B, A stops the timer and transits to the “Wait for Request 0 from above” state. If A receives a D0 data message while in this state, it is ignored.
The data supplier (B) has only two states:
“Send D0.” In this state, B continues to respond to received R0 messages by sending D0, and then remaining in this state. If B receives a R1 message, then it knows its D0 message has been received correctly. It thus discards this D0 data (since it has been received at the other side) and then transits to the “Send D1” state, where it will use D1 to send the next requested piece of data.
“Send D1.” In this state, B continues to respond to received R1 messages by sending D1, and then remaining in this state. If B receives a R1 message, then it knows its D1 message has been received correctly and thus transits to the “Send D1” state.
21. 判断下面的问题,并简要地证实你的回答:
a.在SR协议中,发送方可能会收到落在其当前窗口之外的分组ACK.
b.在GBN协议中,发送方可能会受到落在其当前窗口之外的分组的ACK
c. 当发送方和接收方窗口长度都为1时,比特交替协议与SR协议相同
d. 当发送方和接收方窗口长度都为1时,比特交替协议与GBN协议相同
ANS:
a. 正确 ;Suppose the sender has a window size of 3 and sends packets 1, 2, 3 at t0. At t1(t1>t0) the receiver ACKS 1, 2, 3. At t2(t2>t1) the sender times out and resends 1, 2, 3. At t3(t3>t2) the receiver receives the duplicates and re-acknowledges 1, 2, 3. At t4(t4>t3) the sender receives the ACKs that the receiver sent at t1 and advances its window to 4, 5, 6. At t5 the sender receives the ACKs 1, 2, 3 the receiver sent at t2. These ACKs are outside its window.
b.正确;和a一样的场景
c. 正确;
d.正确;Note that with a window size of 1, SR, GBN, and the alternating bit protocol are functionally equivalent. The window size of 1 precludes the possibility of out-of-order packets (within the window). A cumulative ACK is just an ordinary ACK in this situation, since it can only refer to the single packet within the window.
23. 考虑从主机A向主机B传输L字节的大文件,假设MMS为1460字节。
a. 在TCP序号允许范围内,L的值最大是多少?TCP的序号字段为4字节
b.对于你在(a)中得到的L,求出传输此文件要用多长时间。假定运输层、网络层和数据链路层总共加在每个报文段首部上的长度为66字节,传输分组的链路速率为10Mbps。不采用流量控制和拥塞控制,因此主机A能够一个接一个、连续不断地发送报文段
ANS:
a. TCP 的序号为32bit,因此TCP序号表示范围为0~232 bit,故能表示的L的最大值为232=4Gbytes
b. 结合a可知,主机A向主机B传输的文件的报文段segment数目为⌈2321460⌉=2941758Bytes,则所有分组的总的头部信息大小为66*2941758=194156055 Bytes
故链路总所要传递的总信息数为232+194,156,055=3591∗107bits
因此需要3951∗107bits10Mbps=3591sec=59分钟传输此文件
24.主机A和B通过一个TCP连接通信,并且主机B已经收到了来自A的直到字节248的所有字节。假定主机A随后向主机B发送两个报文段。第一个和第二个报文段分别包含了40和60字节的数据。在第一个报文段中,序号是249,源端口号是503,目的端口号是80. 无论何时主机B接收到来自主机A的报文段,它都会发送确认。
a. 在从主机A发往B的第二个报文段中,序号、源端口号和目的端口号各是什么?
b. 如果第一个报文段在第二个报文段之前到达,在第一个到达报文段的确认中,确认号、源端口号和目的端口号各是什么?
c. 如果第二个报文段在第一个报文段之前到达,在第一个到达报文段的确认中,确认号是什么?
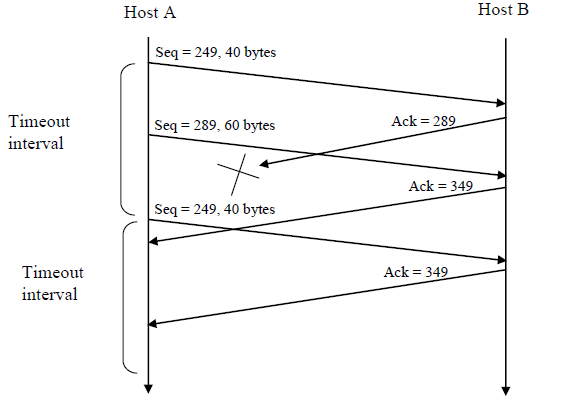
d. 假定由A发送的两个报文段按序到达B。第一个确认丢失了,而第二个确认在第一个超时间隔之后到达。画出时序图,显示这些报文段、发送的所有其他报文段和确认。(假设没有其他分组丢失。)对于每个报文段,标出序号和数据的字节编号;对于增加的每个确认,标出确认号。
ANS:
a. 序号为288,源端口号为503,目标端口号为80
b.确认号为288,源端口号为80,目标端口号为503
c.确认号为249
d.
31. 考虑下图中TCP 窗口长度作为时间的函数。
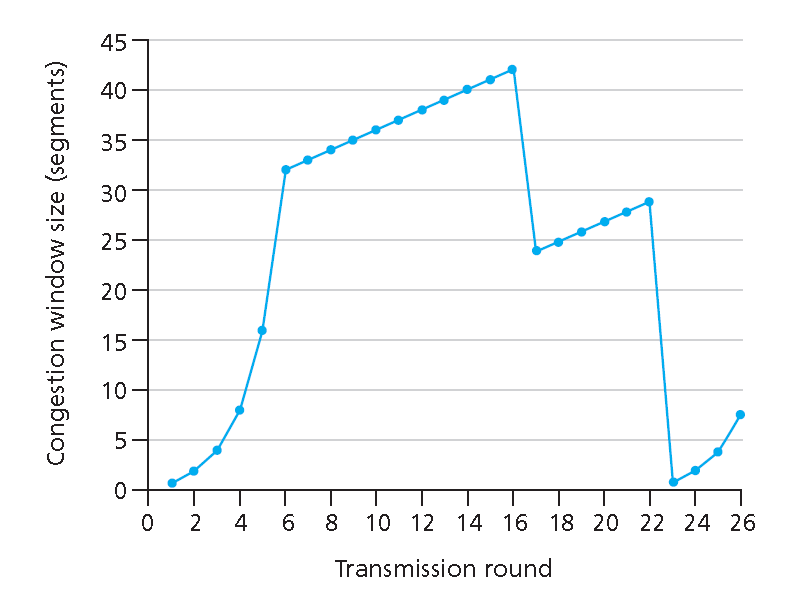
假设TCP Reno是一个经历如上图所示行为的协议,请回答下列问题。在各种情况下,简要地论证你的回答。
a. 指出当运行TCP 慢启动时的时间间隔
b. 指出当运行TCP拥塞避免时的时间间隔
c. 在第16个传输周期之后,报文段的丢失是根据3个重复确认还是根据超时检测出来的?
d. 在第22个传输周期之后,报文段的丢失是根据3个重复确认还是根据超时检测出来的?
e. 在第一个传输周期里,Threshold的初始值设置为多少?
f. 在第18个传输周期里,Threshold的值设置为多少?
g. 在第24个传输周期里,Threshold的值设置为多少?
h. 第70个报文段在哪一个传输周期内发送?
i. 假定在第26个发送周期后,通过收到3个冗余ACK 检测出有分组丢失,那么拥塞的窗口长度和Threshold的值应当是多少?
ANS:
a. 慢启动的时间间隔为[1,6]和[23,26]
b. 拥塞避免的时间间隔为[6,16]和[17,22]
c. 由于ConWin的大小是变为当前的一半,因此报文段的丢失是根据3个重复确认检测出来的
d. 由于ConWin的大小是变为一个MSS,因此报文段的丢失是根据超时检测出来的
e. 因为拥塞窗口在达到32*MSS之后就开始拥塞避免阶段,因此Threshold的初始值为32* MSS
f. 在第16个周期发生第一次丢包之后ConWin的值将为原来的一半,变成21*MSS,接着从[17,22]为拥塞避免时的时间间隔,因此在第18个传输周期里,Threshold的值为21*MSS
g. 在第22个传输周期时ConWin大小为26,此时又发生丢包事件,因此Threshold变为ConWin的一半为13* MSS,因此在第24个传输周期里,Threshold值为13*MSS
h. 在第6个传输周期时,已经发送了1+2+4+…+32=63个报文段,而在第7个传输周期ConWin大小为33,63+33=96>70,因此第70个报文段是在第7个传输周期内传送的
i. 在第26个传输周期时,拥塞串口长度ConWin大小为8*MSS,因此当收到3个冗余ACK检测出有分组丢失时,将启动拥塞避免周期,Threshold为当前ConWin大小的一半,即4*MSS
34. 参考图3-55,该图描述了TCP的AIMD算法的收敛特性。现在假设TCP不采用乘性减,而是采用某一常量递减。所得的AIAD算法将收敛于一种平均共享算法吗?使用类似于图3-55中的图来证实你的结论
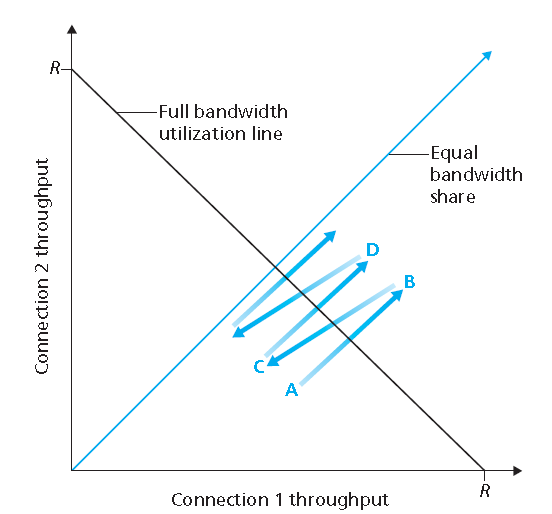
ANS:
Refer to Figure 5. In Figure 5(a), the ratio of the linear decrease on loss between connection 1 and connection 2 is the same - as ratio of the linear increases: unity. In this case, the throughputs never move off of the AB line segment. In Figure 5(a), the ratio of the linear decrease on loss between connection 1 and connection 2 is 2:1. That is, whenever there is a loss, connection 1 decreases its window by twice the amount of connection 2. We see that eventually, after enough losses, and subsequent increases, that connection 1’s throughput will go to 0, and the full link bandwidth will be allocated to connection 2.
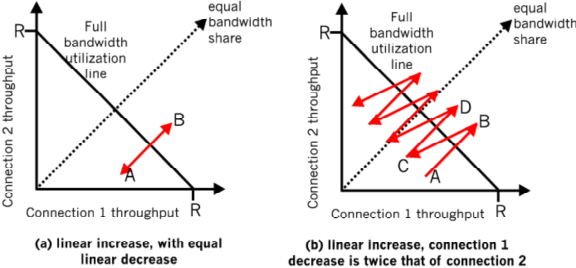
Figure 5: Lack of TCP convergence with linear increase, linear decrease
36. 主机A通过一条TCP连接向主机B发送一个很大的文件。在这条连接上,不会出现任何分组丢失和定时器超时。主机A与因特网连接的链路的传输速率为R bps。假设主机A上的进程向TCP套接字发送数据的速率为S bps,其中S=10 * R。进一步假设TCP的接收缓存足够大,能够接收整个文件。然而,发送缓存只能容纳这个文件的百分之一。那么如何防止主机A上的进程连续地向TCP套接字以速率S bps传送速率呢?使用TCP流量控制?使用TCP拥塞控制?还是用其他措施?请阐述之。
ANS:
使用TCP流量控制,In this problem, there is no danger in overflowing the receiver since the receiver’s receive buffer can hold the entire file. Also, because there is no loss and acknowledgements are returned before timers expire, TCP congestion control does not throttle the sender. However, the process in host A will not continuously pass data to the socket because the send buffer will quickly fill up. Once the send buffer becomes full, the process will pass data at an average rate or R << S.
37.考虑一台主机经一条TCP连接向另一台主机发送一个大文件,这条连接不会丢包。
a.假定TCP使用不具有慢启动的AIMD进行拥塞控制。假设每当收到一批ACK时,CongWin增加1个MSS,往返时间基本恒定,那么CongWin从1 MSS增加到6 MSS要花费多长时间(假设没有丢包事件)?
b. 对于该连接,直到时间为5 RTT,其平均吞吐量是多少?(根据MSS和RTT来计算)
ANS:
a.由于MSS的增长是线性的,故CongWin从1MSS增加到6MSS需要5个RTT
b. 时间为5RTT时,发送方发送的所有报文段总数为1+2+3+4+5=15个MSS,则平均吞吐量为15MSS5RTT=3MSS\RTT
40. 在3.7节对TCP拥塞控制的讨论中,我们隐含地假定TCP发送方总是有数据发送。现在考虑下列情况:某TCP发送方发送大量数据,然后在t1时刻变得空闲(因为它没有更多的数据要发送)。TCP在相对长时间内保持空闲,然后在t2时刻要发送更多的数据。让TCP在t2时刻开始发送数据时,使用它在t1时刻的CongWin和Threshold值有什么样的优点和缺点?你认为应该使用什么样的方法?为什么?
ANS:
An advantage of using the earlier values of CongWin and Threshold at t2 is that TCP would not have to go through slow start and congestion avoidance to ramp up to the throughput value obtained at t1. A disadvantage of using these values is that they may be no longer accurate. In particular, if the path has become more congested between t1 and t2, the sender will send a large window’s worth of segments into an already (more) congested path.
41. 在这个习题中,我们研究UDP或TCP是否提供了某种程度的端点鉴别功能。
a.考虑一台服务器接收到一个UDP分组中的请求并对该请求进行响应的情况,(例如,像一台DNS服务器所做的那样)。如果一个IP地址为X的客户机用地址Y进行欺骗的话,服务器将向何处发送响应?
b. 假定一台服务器接收到来自IP源地址Y的一个SYN,在用SYNACK响应之后,接收到一个来自IP源地址Y、具有正确确认号的ACK。假设该服务器选择了一个随机初始序号并且没有“中间人”,它能够确定该客户机的确位于Y(并且不在某个其他地址X,用X欺骗Y)吗?
ANS:
a. 服务器将向地址Y发送响应
b. The server can be certain that the client is indeed at Y. If it were at some other address spoofing Y, the SYNACK would have been sent to the address Y, and the TCP in that host would not send the TCP ACK segment back. Even if the attacker were to send an appropriately timed TCP ACK segment, it would not know the correct server sequence number (since the server uses random initial sequence numbers.)

相关文章推荐
- 计网-ch01-题目与解释
- 计网-ch02-题目与解释
- Eclipse启动报错 java was started but returned code=14
- Android init.rc文件详
- jni编译问题:jin中添加LOG方法以及undefined reference to `__android_log_print'错误
- ORACLE游标概念讲解
- poj 1959 Darts 同意反复组合
- [资料收集]Java问题解决
- UE4 WCF RestFul 服务器 读取JSON 数据并解析 简单实例
- OC中的const
- Linux下添加用户和用户组的命令使用教程
- 四种存储方式(File sharepreference....)
- 66. Plus One
- nginx屏蔽IP
- 在Win7虚拟机下搭建Hadoop2.5.2+Spark1.5.2单机环境
- console编码问题
- Java将字节转换为十六进制代码分享
- cin、cin.get()、cin.getline()、getline()、gets()等函数的用法
- ios植入广告
- 透明度