257. Binary Tree Paths-LeetCode(树的全部路径)(第一次写树,兴奋)
2016-01-09 23:42
381 查看
第一次写有关树结构的代码,运行通过心里还是蛮开心的。
Total Accepted: 29117 Total Submissions: 113069 Difficulty: Easy
Given a binary tree, return all root-to-leaf paths.
For example, given the following binary tree:
1
/ \
2 3
\
5
All root-to-leaf paths are:
[“1->2->5”, “1->3”]
好在我的算法的效率之低是惊人的,让我依然有很大的进步空间……
这里面使用了递归的方法,递归方法中无论递归函数有没有返回值都是可以进行递归地,区别在于每次将结果向上传送返回还是在每一个子节递归中都可以保存进全局的一块内存,依据具体的需求耳而定。比如这里面如果需求是将所有的路径组成一个String,那么不断向上级返回的方法应该会逻辑简单。而这里面每一个字符串都将加入一个容器当中。
这是一种深度遍历,二叉树中的(先序遍历,因为String中的顺序是先出现的信息显示子在字符串的前面,当然也可以进行后续遍历,不过添加新的字符串要放在前面。)
深度遍历:从树根开始扫描,顶层扫描完了,从一层最左(也可以右)面的结点往下层扫描,直到下层已无结点,这时所有靠最左(右)的结点全部扫描完毕,从树梢往上退一层,看这层旁有无兄弟结点,有的话还是一样从最左(右)边开始扫描,这是个递归概念,利用这一方法来遍历整棵树。
广度遍历:从树根开始扫描,顶层扫描完了,扫描一层的所有结点,扫描二层的所有结点,……,扫描最底层的结点。
这里补充一下自己的观点:
二叉树的先中后遍历都是深度优先遍历,只不过路径上节点输出的顺序不同。其路径都是在树的外围包裹一层。(游客走的路径相同,拍照记录时间不同。)
而层次遍历对应广度优先遍历。(犹如搜捕的特警队员。不断站在自己扫描过的点上进行扫描,每次扫描各个角度都要看到。)
好了好了,看看排序那些做我分母的大神的算法吧。
其实这个思路跟我是一样的,但是时间复杂度小了很多。
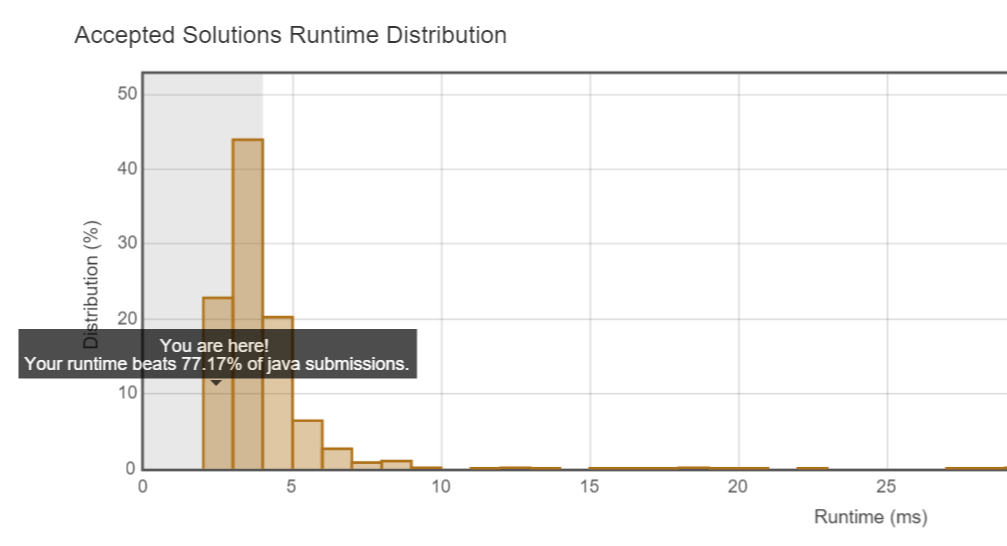
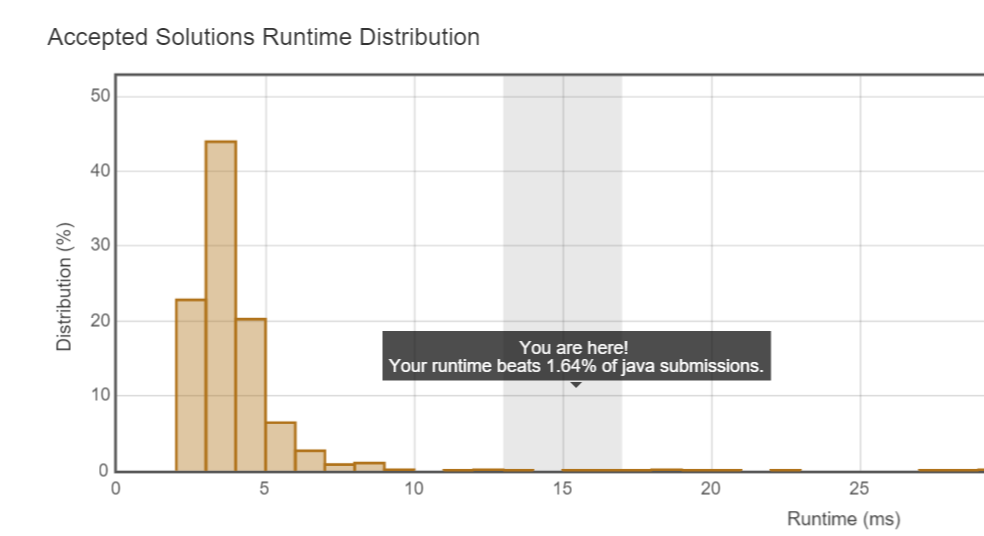
里面的原因要想一下。咳咳,看了一下,自己的System.out输出没有注释掉。注释以后也是2ms执行时间,yeah~!
还有这次写程序没有写注释和明确思想,直接在代码上进行修改,有点冒险。但是可喜的是我做到了。
Total Accepted: 29117 Total Submissions: 113069 Difficulty: Easy
Given a binary tree, return all root-to-leaf paths.
For example, given the following binary tree:
1
/ \
2 3
\
5
All root-to-leaf paths are:
[“1->2->5”, “1->3”]
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
public class Solution {
List<String> myList=new ArrayList<String>();
public List<String> binaryTreePaths(TreeNode root) {
addNode(null,root);
for(String temp:myList){
System.out.println(temp);
}
return myList;
}
private void addNode(String parentString,TreeNode thisNode){
if(thisNode==null){
return ;
}
String currentString=null;
if(parentString!=null){
currentString=parentString+"->";
}else{
currentString="";
}
currentString+=thisNode.val;
if(thisNode.left==null&&thisNode.right==null){
if(currentString!=null){
myList.add(currentString);
}
}
if(thisNode.left!=null){
addNode(currentString,thisNode.left);
}
if(thisNode.right!=null){
addNode(currentString,thisNode.right);
}
return ;
}
}好在我的算法的效率之低是惊人的,让我依然有很大的进步空间……
这里面使用了递归的方法,递归方法中无论递归函数有没有返回值都是可以进行递归地,区别在于每次将结果向上传送返回还是在每一个子节递归中都可以保存进全局的一块内存,依据具体的需求耳而定。比如这里面如果需求是将所有的路径组成一个String,那么不断向上级返回的方法应该会逻辑简单。而这里面每一个字符串都将加入一个容器当中。
这是一种深度遍历,二叉树中的(先序遍历,因为String中的顺序是先出现的信息显示子在字符串的前面,当然也可以进行后续遍历,不过添加新的字符串要放在前面。)
知识回顾——树的遍历形式
先序,后序,中序针对二叉树。深度、广度针对普通树。深度遍历:从树根开始扫描,顶层扫描完了,从一层最左(也可以右)面的结点往下层扫描,直到下层已无结点,这时所有靠最左(右)的结点全部扫描完毕,从树梢往上退一层,看这层旁有无兄弟结点,有的话还是一样从最左(右)边开始扫描,这是个递归概念,利用这一方法来遍历整棵树。
广度遍历:从树根开始扫描,顶层扫描完了,扫描一层的所有结点,扫描二层的所有结点,……,扫描最底层的结点。
这里补充一下自己的观点:
二叉树的先中后遍历都是深度优先遍历,只不过路径上节点输出的顺序不同。其路径都是在树的外围包裹一层。(游客走的路径相同,拍照记录时间不同。)
而层次遍历对应广度优先遍历。(犹如搜捕的特警队员。不断站在自己扫描过的点上进行扫描,每次扫描各个角度都要看到。)
好了好了,看看排序那些做我分母的大神的算法吧。
public List<String> binaryTreePaths(TreeNode root) {
List<String> answer = new ArrayList<String>();
if (root != null) searchBT(root, "", answer);
return answer;
}
private void searchBT(TreeNode root, String path, List<String> answer) {
if (root.left == null && root.right == null) answer.add(path + root.val);
if (root.left != null) searchBT(root.left, path + root.val + "->", answer);
if (root.right != null) searchBT(root.right, path + root.val + "->", answer);
}其实这个思路跟我是一样的,但是时间复杂度小了很多。
里面的原因要想一下。咳咳,看了一下,自己的System.out输出没有注释掉。注释以后也是2ms执行时间,yeah~!
还有这次写程序没有写注释和明确思想,直接在代码上进行修改,有点冒险。但是可喜的是我做到了。

相关文章推荐
- 注册表的组织结构
- SQLSERVER的非聚集索引结构深度理解
- 调整SQLServer2000运行中数据库结构
- C#基础语法:结构和类区别详解
- 深入c# 类和结构的区别总结详解
- c#结构和类的相关介绍
- C#中结构(struct)的部分初始化和完全初始化实例分析
- C#中类与结构的区别实例分析
- C#枚举类型与结构类型实例解析
- javascript实现表现、结构、行为分离的选项卡效果!
- 实用的js 焦点图切换效果 结构行为相分离
- asp下生成目录树结构的类
- Android编程入门之HelloWorld项目目录结构分析
- Go语言的Windows下环境配置以及简单的程序结构讲解
- thinkphp文件引用与分支结构用法实例
- php实现的树形结构数据存取类实例
- Swift教程之类与结构详解
- leetcode 179 Largest Number
- leetcode 24 Swap Nodes in Pairs
- leetcode 2 Add Two Numbers 方法1