awk:报告生成器
2016-01-05 22:18
387 查看
一、awk简介 1.awk简介:报告生成器,文本格式化输出;遍历文件 命名: Aho, Weinberger, Kernighan采用三个作者的名称首字母简写 版本:awk、Nawk(New AWK, NAWK)、gawk((GNU版本的awk) 注意:Linux上使用的awk实际上是gawk,awk为gawk的一个链接文件 [root@localhost ~]# ls -l /usr/bin/awk lrwxrwxrwx. 1 root root 14 Dec 30 23:58 /usr/bin/awk ->../../bin/gawk

2.gawk- pattern scanning and processing language模式扫描及解释语言 gawk本质上来说也是编程语言,脚本编程语言解释器,过程式编程语言基本用法:gawk [options] 'program_text' FILE ...program_text :PATTERN{ACTION STATEMENTS}模式{动作语句} 多个动作语句之间用分号分隔,此处模式更多是地址定界的意味 [options]-F:指明输入时用到的字段分隔符,默认为空格;-v var=value: 用于实现自定义变量; [ACTION] (1) Expressions表达式:比较表达式、算数表达式等 (2) Controlstatements控制语句:if, while等; (3) Compound statements:组合语句; (4) input statements输入语句 (5) outputstatements输出语句
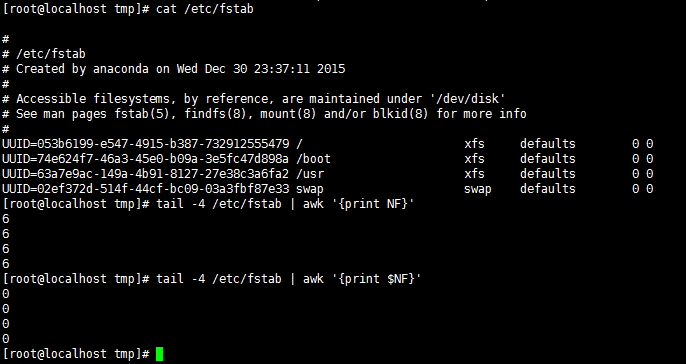
二、gawk详解 基本用法:gawk|awk [options] 'program' FILE … gawk [options] -f 'program_file' FILE … 从文件中读取配置切割成片段时候显示某一段或几段$1,$2,$3,逗号分隔… …$0 表示整行全部片段 1.print:输出命令 print item1,item2, … 注意: (1)逗号分隔符每项,用以说明多个字段,不显示,输出时候任然以空格分开; (2)输出的各item可以字符串、数值、当前记录的字段、变量或awk的表达式; (3)直接使用print,省略item,相当于print $0,打印整行 2.变量 (1)内建变量:var=value格式 FS:input field seperator,输入字段分隔符,默认为空白字符; OFS:output field seperator,输出字段分隔符,默认为空白字符; RS:inputrecord seperator,输入时的换行符; ORS:outputrecord seperator,输出时的换行符; NF:number of field,显示字段数量 NR:numberof record, 行数; FNR:各文件分别计数;行数; FILENAME:当前文件名; ARGC:命令行参数的个数; ARGV:数组,保存的是命令行所给定的各参数; 注意: {print NF}和{print $NF}的区别: [root@localhost tmp]# tail -4 /etc/fstab | awk '{print NF}'显示有多少字段 [root@localhost tmp]# tail -4 /etc/fstab | awk '{print $NF}'显示第几个$内容
(2)自定义变量 1)-v var=value 变量名区分字符大小写,引用变量在awk中无需加$符号 2)在program中可以可以直接定义自定义变量,使用时候直接定义变量

3.printf命令:输出显示 (1)格式化输出:printf FORMAT,item1, item2, ... 1)FORMAT必须给出; 2)不会自动换行,需要显式给出换行控制符,\n 3)FORMAT中需要分别为后面的每个item指定一个格式化符号; (2)格式符: %c:显示字符的ASCII码; %d,%i: 显示十进制整数; %e,%E: 科学计数法数值显示; %f:显示为浮点数; %g,%G:以科学计数法或浮点形式显示数值; %s:显示字符串; %u:无符号整数; %%:显示%自身; (3)修饰符: #[.#]:第一个数字控制显示的宽度;第二个#表示小数点后的精度;默认右对齐,如%3.1f -: 左对齐 +:显示数值的符号,正负数符号 实例:[root@localhost tmp]# head -5 /etc/passwd | awk -F: '{printf"Username: %-10s, UID:%d\n",$1,$3}' -F:指明字段分隔符,%-10s十个字符左对齐,\n换行默认不换行

4.操作符 (1)算术操作符 加减乘除次方取模:x+y, x-y, x*y, x/y, x^y, x%y 负值:-x 将字符串 转换为数值:+x (2)字符串操作符:没有符号的操作符,字符串连接 (3)赋值操作符: =, +=, -=, *=, /=, %=, ^= ++, --:自加、自减 (4)比较操作符: >, >=, <, <=, !=, == (5)模式匹配符:~表示是否匹配、!~表示是否不匹配 (6)逻辑操作符:&& || ! (7)函数调用:function_name(argu1, argu2, ...) (8)条件表达式:selector?if-true-expression:if-false-expression # awk-F: '{$3>=1000?usertype="Common User":usertype="Sysadmin orSysUser";printf "%15s:%-s\n",$1,usertype}' /etc/passwd

5.PATTERN可用样式 (1) empty:空模式,匹配任意一行; (2) /regularexpression/:仅处理能够被此处的模式匹配到的行,正则表达式; (3) relational expression: 关系表达式,比较表达式 结果为“真”才会被处理;真表示结果为非0值、非空字符串; (4) line ranges:指明行范围 startline,endline:以NR的条件判断的形式显示 /pat1/,/pat2/:模式匹配方法 注意: 不支持直接给出数字的格式,Eg:~]# awk -F:'(NR>=2&&NR<=10){print $1}' /etc/passwd (5)BEGIN/END模式 BEGIN{}: 仅在开始处理文件中的文本之前执行一次; END{}:仅在文本处理完成之后执行一次;
6.控制语句 (1)if-else 语法:if(condition)statement [else statement] 使用场景:对awk取得的整行或某个字段做条件判断; 示例: ~]# awk -F:'{if($3>=1000) {printf "Common user: %s\n",$1} else {printf"root or Sysuser: %s\n",$1}}' /etc/passwd ~]# awk -F:'{if($NF=="/bin/bash") print $1}' /etc/passwd ~]# awk'{if(NF>5) print $0}' /etc/fstab ~]# df -h | awk-F[%] '/^\/dev/{print $1}' | awk '{if($NF>=20) print $1}' (2)while循环 语法:while(condition)statement 条件“真”,进入循环;条件“假”,退出循环;使用场景:对一行内的多个字段逐一类似处理时使用;对数组中的各元素逐一处理时使用;~]#awk '/^[[:space:]]*linux16/{i=1;while(i<=NF) {print $i,length($i); i++}}'/etc/grub2.cfg~]#awk '/^[[:space:]]*linux16/{i=1;while(i<=NF) {if(length($i)>=7) {print$i,length($i)}; i++}}' /etc/grub2.cfg (3)do-while循环 语法:dostatement while(condition) 意义:至少执行一次循环体 (4)for循环 语法:for(expr1;expr2;expr3)statement for(variableassignment;condition;iteration process) {for-body} ~]#awk '/^[[:space:]]*linux16/{for(i=1;i<=NF;i++) {print $i,length($i)}}'/etc/grub2.cfg特殊用法:能够遍历数组中的元素;语法:for(varin array) {for-body} (5)switch语句 语法:switch(expression){case VALUE1 or /REGEXP/: statement; case VALUE2 or /REGEXP2/: statement; ...;default: statement} (6)break和continue break
continue (7)next 提前结束对本行的处理而直接进入下一行; ~]# awk -F: '{if($3%2!=0) next; print $1,$3}' /etc/passwd
7.array 关联数组:array[index-expression] index-expression:(1)可使用任意字符串;字符串要使用双引号;(2)如果某数组元素事先不存在,在引用时,awk会自动创建此元素,并将其值初始化为“空串”; 若要判断数组中是否存在某元素,要使用"index in array"格式进行; weekdays[mon]="Monday" 若要遍历数组中的每个元素,要使用for循环:for(var in array) {for-body}~]# awk'BEGIN{weekdays["mon"]="Monday";weekdays["tue"]="Tuesday";for(iin weekdays) {print weekdays[i]}}'注意:var会遍历array的每个索引;state["LISTEN"]++state["ESTABLISHED"]++~]#netstat -tan | awk '/^tcp\>/{state[$NF]++}END{for(i in state) { printi,state[i]}}'~]#awk '{ip[$1]++}END{for(i in ip) {print i,ip[i]}}' /var/log/httpd/access_log 8.函数 (1)内置函数 数值处理:rand():返回0和1之间一个随机数; 字符串处理:length([s]):返回指定字符串的长度; sub(r,s,[t]):以r表示的模式来查找t所表示的字符中的匹配的内容,并将其第一次出现替换为s所表示内容;gsub(r,s,[t]):以r表示的模式来查找t所表示的字符中的匹配的内容,并将其所有出现均替换为s所表示的内容;split(s,a[,r]):以r为分隔符切割字符s,并将切割后的结果保存至a所表示的数组中;示例:# netstat-tan | awk '/^tcp\>/{split($5,ip,":");count[ip[1]]++}END{for (i incount) {print i,count[i]}}' (2)自定义函数
本文出自 “许鼎的博客” 博客,请务必保留此出处http://xuding.blog.51cto.com/4890434/1731883
2.gawk- pattern scanning and processing language模式扫描及解释语言 gawk本质上来说也是编程语言,脚本编程语言解释器,过程式编程语言基本用法:gawk [options] 'program_text' FILE ...program_text :PATTERN{ACTION STATEMENTS}模式{动作语句} 多个动作语句之间用分号分隔,此处模式更多是地址定界的意味 [options]-F:指明输入时用到的字段分隔符,默认为空格;-v var=value: 用于实现自定义变量; [ACTION] (1) Expressions表达式:比较表达式、算数表达式等 (2) Controlstatements控制语句:if, while等; (3) Compound statements:组合语句; (4) input statements输入语句 (5) outputstatements输出语句
二、gawk详解 基本用法:gawk|awk [options] 'program' FILE … gawk [options] -f 'program_file' FILE … 从文件中读取配置切割成片段时候显示某一段或几段$1,$2,$3,逗号分隔… …$0 表示整行全部片段 1.print:输出命令 print item1,item2, … 注意: (1)逗号分隔符每项,用以说明多个字段,不显示,输出时候任然以空格分开; (2)输出的各item可以字符串、数值、当前记录的字段、变量或awk的表达式; (3)直接使用print,省略item,相当于print $0,打印整行 2.变量 (1)内建变量:var=value格式 FS:input field seperator,输入字段分隔符,默认为空白字符; OFS:output field seperator,输出字段分隔符,默认为空白字符; RS:inputrecord seperator,输入时的换行符; ORS:outputrecord seperator,输出时的换行符; NF:number of field,显示字段数量 NR:numberof record, 行数; FNR:各文件分别计数;行数; FILENAME:当前文件名; ARGC:命令行参数的个数; ARGV:数组,保存的是命令行所给定的各参数; 注意: {print NF}和{print $NF}的区别: [root@localhost tmp]# tail -4 /etc/fstab | awk '{print NF}'显示有多少字段 [root@localhost tmp]# tail -4 /etc/fstab | awk '{print $NF}'显示第几个$内容
(2)自定义变量 1)-v var=value 变量名区分字符大小写,引用变量在awk中无需加$符号 2)在program中可以可以直接定义自定义变量,使用时候直接定义变量
3.printf命令:输出显示 (1)格式化输出:printf FORMAT,item1, item2, ... 1)FORMAT必须给出; 2)不会自动换行,需要显式给出换行控制符,\n 3)FORMAT中需要分别为后面的每个item指定一个格式化符号; (2)格式符: %c:显示字符的ASCII码; %d,%i: 显示十进制整数; %e,%E: 科学计数法数值显示; %f:显示为浮点数; %g,%G:以科学计数法或浮点形式显示数值; %s:显示字符串; %u:无符号整数; %%:显示%自身; (3)修饰符: #[.#]:第一个数字控制显示的宽度;第二个#表示小数点后的精度;默认右对齐,如%3.1f -: 左对齐 +:显示数值的符号,正负数符号 实例:[root@localhost tmp]# head -5 /etc/passwd | awk -F: '{printf"Username: %-10s, UID:%d\n",$1,$3}' -F:指明字段分隔符,%-10s十个字符左对齐,\n换行默认不换行
4.操作符 (1)算术操作符 加减乘除次方取模:x+y, x-y, x*y, x/y, x^y, x%y 负值:-x 将字符串 转换为数值:+x (2)字符串操作符:没有符号的操作符,字符串连接 (3)赋值操作符: =, +=, -=, *=, /=, %=, ^= ++, --:自加、自减 (4)比较操作符: >, >=, <, <=, !=, == (5)模式匹配符:~表示是否匹配、!~表示是否不匹配 (6)逻辑操作符:&& || ! (7)函数调用:function_name(argu1, argu2, ...) (8)条件表达式:selector?if-true-expression:if-false-expression # awk-F: '{$3>=1000?usertype="Common User":usertype="Sysadmin orSysUser";printf "%15s:%-s\n",$1,usertype}' /etc/passwd
5.PATTERN可用样式 (1) empty:空模式,匹配任意一行; (2) /regularexpression/:仅处理能够被此处的模式匹配到的行,正则表达式; (3) relational expression: 关系表达式,比较表达式 结果为“真”才会被处理;真表示结果为非0值、非空字符串; (4) line ranges:指明行范围 startline,endline:以NR的条件判断的形式显示 /pat1/,/pat2/:模式匹配方法 注意: 不支持直接给出数字的格式,Eg:~]# awk -F:'(NR>=2&&NR<=10){print $1}' /etc/passwd (5)BEGIN/END模式 BEGIN{}: 仅在开始处理文件中的文本之前执行一次; END{}:仅在文本处理完成之后执行一次;
6.控制语句 (1)if-else 语法:if(condition)statement [else statement] 使用场景:对awk取得的整行或某个字段做条件判断; 示例: ~]# awk -F:'{if($3>=1000) {printf "Common user: %s\n",$1} else {printf"root or Sysuser: %s\n",$1}}' /etc/passwd ~]# awk -F:'{if($NF=="/bin/bash") print $1}' /etc/passwd ~]# awk'{if(NF>5) print $0}' /etc/fstab ~]# df -h | awk-F[%] '/^\/dev/{print $1}' | awk '{if($NF>=20) print $1}' (2)while循环 语法:while(condition)statement 条件“真”,进入循环;条件“假”,退出循环;使用场景:对一行内的多个字段逐一类似处理时使用;对数组中的各元素逐一处理时使用;~]#awk '/^[[:space:]]*linux16/{i=1;while(i<=NF) {print $i,length($i); i++}}'/etc/grub2.cfg~]#awk '/^[[:space:]]*linux16/{i=1;while(i<=NF) {if(length($i)>=7) {print$i,length($i)}; i++}}' /etc/grub2.cfg (3)do-while循环 语法:dostatement while(condition) 意义:至少执行一次循环体 (4)for循环 语法:for(expr1;expr2;expr3)statement for(variableassignment;condition;iteration process) {for-body} ~]#awk '/^[[:space:]]*linux16/{for(i=1;i<=NF;i++) {print $i,length($i)}}'/etc/grub2.cfg特殊用法:能够遍历数组中的元素;语法:for(varin array) {for-body} (5)switch语句 语法:switch(expression){case VALUE1 or /REGEXP/: statement; case VALUE2 or /REGEXP2/: statement; ...;default: statement} (6)break和continue break
continue (7)next 提前结束对本行的处理而直接进入下一行; ~]# awk -F: '{if($3%2!=0) next; print $1,$3}' /etc/passwd
7.array 关联数组:array[index-expression] index-expression:(1)可使用任意字符串;字符串要使用双引号;(2)如果某数组元素事先不存在,在引用时,awk会自动创建此元素,并将其值初始化为“空串”; 若要判断数组中是否存在某元素,要使用"index in array"格式进行; weekdays[mon]="Monday" 若要遍历数组中的每个元素,要使用for循环:for(var in array) {for-body}~]# awk'BEGIN{weekdays["mon"]="Monday";weekdays["tue"]="Tuesday";for(iin weekdays) {print weekdays[i]}}'注意:var会遍历array的每个索引;state["LISTEN"]++state["ESTABLISHED"]++~]#netstat -tan | awk '/^tcp\>/{state[$NF]++}END{for(i in state) { printi,state[i]}}'~]#awk '{ip[$1]++}END{for(i in ip) {print i,ip[i]}}' /var/log/httpd/access_log 8.函数 (1)内置函数 数值处理:rand():返回0和1之间一个随机数; 字符串处理:length([s]):返回指定字符串的长度; sub(r,s,[t]):以r表示的模式来查找t所表示的字符中的匹配的内容,并将其第一次出现替换为s所表示内容;gsub(r,s,[t]):以r表示的模式来查找t所表示的字符中的匹配的内容,并将其所有出现均替换为s所表示的内容;split(s,a[,r]):以r为分隔符切割字符s,并将切割后的结果保存至a所表示的数组中;示例:# netstat-tan | awk '/^tcp\>/{split($5,ip,":");count[ip[1]]++}END{for (i incount) {print i,count[i]}}' (2)自定义函数
本文出自 “许鼎的博客” 博客,请务必保留此出处http://xuding.blog.51cto.com/4890434/1731883

相关文章推荐
- SQL HAVING用法笔记
- CentOS使用不了scp命令怎么办?
- 5-16 求符合给定条件的整数集
- Windows下nginx配置python服务器
- Android动态修改view的长和宽
- Android开发中小知识
- 用CSS样式截取字符串,多的用省略号表示
- POJ 1005_I Think I Need a Houseboat
- ImageLoader加载圆形图片
- Java中HashMap和TreeMap的区别深入理解
- 数据库总结.5
- lintcode:anagrams 乱序字符串
- 基于B-树的图书管理系统课程设计
- 分区表fstab的用法说明
- 安装jira
- 让程序在崩溃时体面的退出之SEH
- MapReduce 图解流程超详细解答(1)-【map阶段】
- s5pv210 的定时器
- 第二章 管理数据库和表
- OpenGL: 矩阵相乘的顺序