HDFS源码分析(9):DFSCliet
2016-01-01 17:27
381 查看
HDFS源码分析(9):DFSCliet
前提
Hadoop版本:hadoop-0.20.2概述
在上一篇文章中HDFS源码分析(8):FileSystem已对Hadoop的文件系统接口进行了简单的介绍,相信读者也能猜到HDFS会对外提供什么样的接口。为了让读者对HDFS有个总体的把握,本文将对DistributedFileSystem和DFSClient进行分析,这两个类都位于包org.apache.hadoop.hdfs下。好了,废话不多说,真奔主题吧。
##DistributedFileSystem ##
DistributedFileSystem是用于DFS系统的抽象文件系统的实现,继承自FileSystem,用户在使用HDFS时,所使用的文件系统就是该实现。但是DistributedFileSystem的实现并不复杂,没有过多的逻辑,大部分方法会间接调用DFSClient的方法,使DFSClient能兼容Hadoop的FileSystem接口,从而能在Hadoop系统中工作,这不就是设计模式中的Adapter(适配器)模式吗?
我们先来看看与DistributedFileSystem相关的类图,由于涉及到的类繁多,因此只列出关键类的属性和方法,其它的类只有类名:
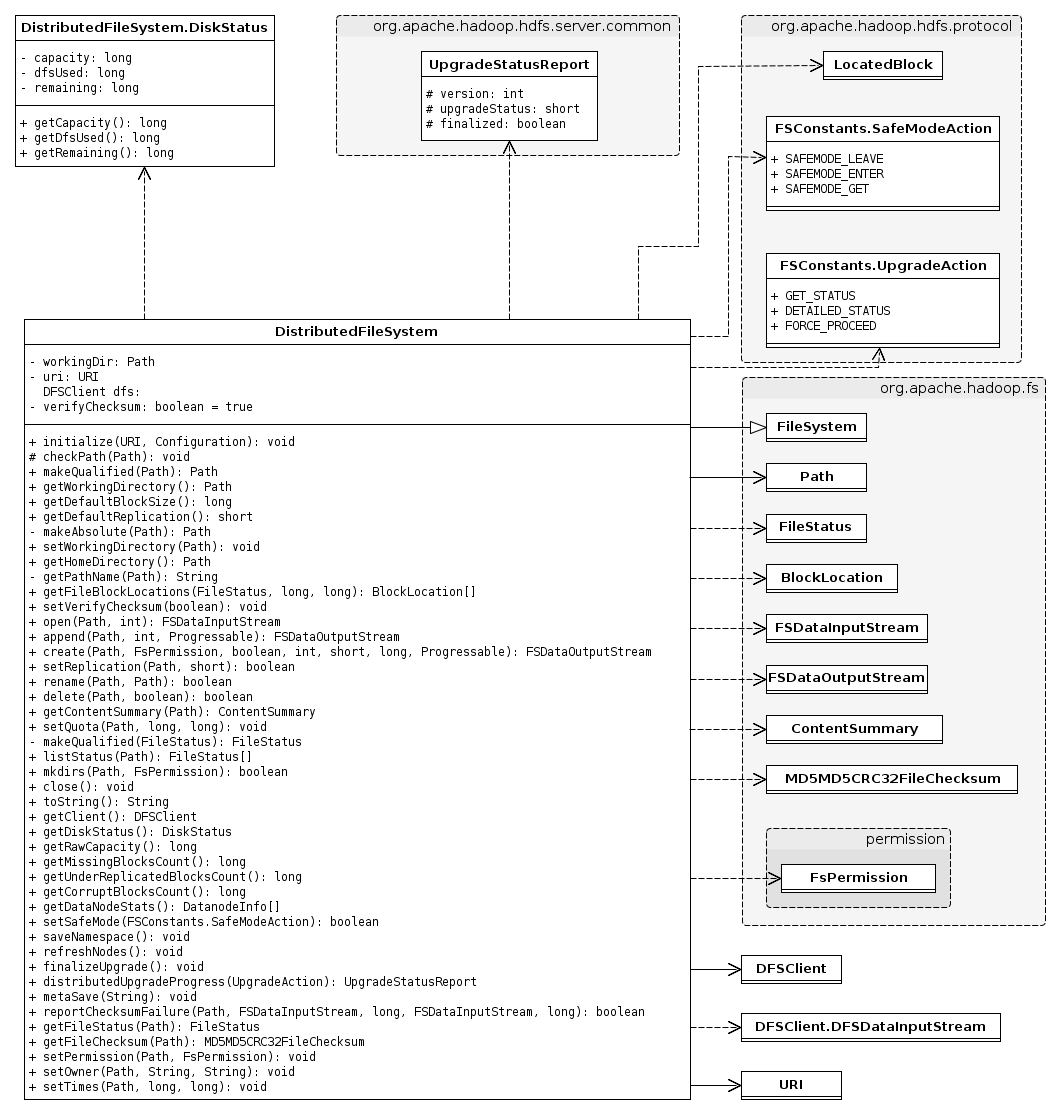
从上图可以看出依赖或关联的类基本是HDFS中通用的类和org.apache.hadoop.fs包下的与文件系统相关的类,DistributedFileSystem的大部分方法会调用DFSClien对应的方法,待下方分析DFSClient时再进行介绍。
先来看看类的初始,在静态初始化块中加载了hdfs-default.xml和hdfs-site.xml配置文件,其中包含了namenode的信息以及一些与HDFS相关的参数;在初始化对象时,从uri中得到namenode地址,设置默认工作目录为用户目录。
有三个方法频繁被其它方法调用:
checkPath,检查路径的scheme、port和authority,允许显式指定默认端口的路径;
makeQualified,归一化显式指定默认端口的路径;
getPathName,检查路径的合法性,并将相对路径转换成绝对路径。
DFSClient
DFSClient是一个真正实现了客户端功能的类,它能够连接到一个Hadoop文件系统并执行基本的文件任务。它使用ClientProtocol来和NameNode通信,并且使用Socket直接连接到DataNode来完成块数据的读/写。Hadoop 用户应该得到一个DistributedFileSystem实例,该实现使用了DFSClient来处理文件系统任务,而不是直接使用DFSClient。我们先来看看与DFSClient相关的类图,由于涉及到的类繁多,因此只列出关键类的属性和方法,其它的类只有类名:
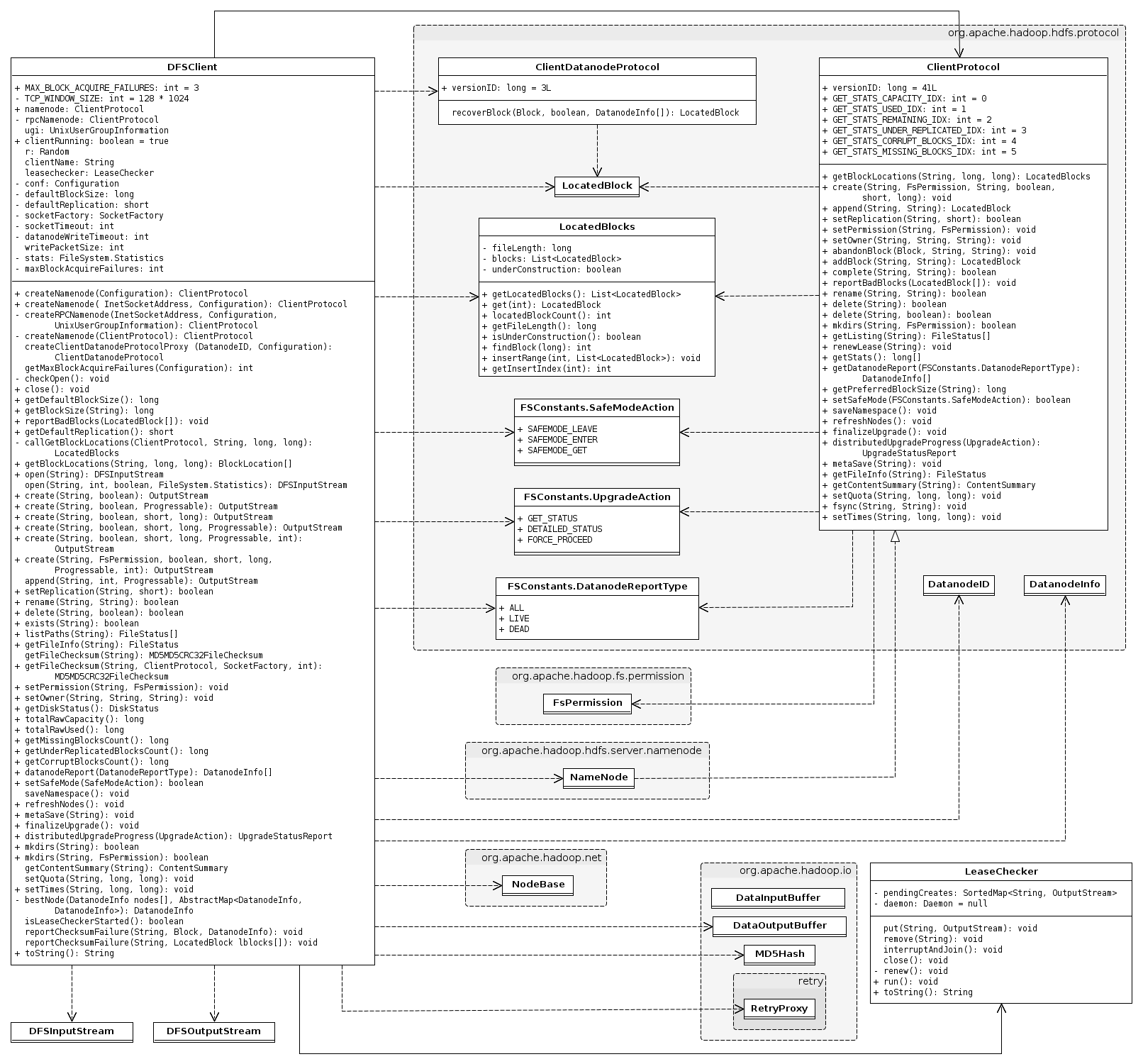
看着上图这么多类,一下子就没有头绪,先来看看DFSClient一些重要的属性:
MAX_BLOCK_ACQUIRE_FAILURES:块最大请求失败次数,值为3
TCP_WINDOW_SIZE:TCP窗口的大小,值为128KB,在seek操作中会用到,假如目标位置在当前块内及在当前位置之后,并且与当前位置的距离不超过TCP_WINDOW_SIZE,那么这些数据很可能在TCP缓冲区中,只需要通过读取操作来跳过这些数据
rpcNamenode:通过建立一个RPC代理来和namenode通信
namenode:在rcpNamenode基础上封装了一个Retry代理,添加了一些RetryPolicy
leasechecker:租约管理,用于管理正被写入的文件输出流
defaultBlockSize:块大小,默认是64MB
defaultReplication:副本数,默认是3
socketTimeout:socket超时时间,默认是60秒
datanodeWriteTimeout:datanode写超时时间,默认是480秒
writePacketSize:写数据时,一个packet的大小,默认是64KB
maxBlockAcquireFailures:块最大请求失败次数,默认是3,主要用于向datanode请求块时,失败了可以重试
DSClient的属性主要是在初始化对象时设置,其中涉及到几个参数,如下所示:
dfs.socket.timeout:读超时
dfs.datanode.socket.write.timeout:写超时
dfs.write.packet.size:一个的packet大小
dfs.client.max.block.acquire.failures:块最大请求失败次数
mapred.task.id:map reduce的ID,如果不为空,clientName设置为“DFSClient_”,否则clientName设置为“DFSClient_”
dfs.block.size:块大小
dfs.replication:副本数
接下来,可以来看看DFSClient的方法,笔者发现很多方法是通过RPC调namenode的方法,这些方法不需赘述了,相信读者都能看出要实现什么操作,下面着重说一下部分方法:
checkOpen:这个方法被频繁调用,但过程很简单,只是检查一下clientRunning的值
getBlockLocations:由于从namenode得到的所有块以LocatedBlocks来描述,那么需要从LocatedBlocks从提取出每个块及拥有该块的datanode信息,并以BlockLocation来描述每个块,最后返回的是BlockLocation数组
getFileChecksum:得到文件的checksum,过程稍微复杂了一点
得到文件所有块的位置
对于每个块,向datanode请求checksum信息,返回的信息中包括块的所有checksum的MD5摘要,如果向一个datanode请求失败,会向另一datanode请求
将所有块的MD5合并,并计算这些内容的MD5摘要
bestNode:挑选一个不在deadNodes中的节点
HftpFileSystem
HftpFileSystem是一种用于通过HTTP方式访问文件系统的协议实现,该实现提供了一个有限的、只读的文件系统接口。实现时,HftpFileSystem通过打开一个到namenode的HTTP连接来读取数据和元信息,主要支持三种操作:
open:向namenode发出http请求,地址是/data/path/to/file,并带有查询串,形式如query1=val1&query2=val2,相信了解http协议的GET方法肯定不觉得陌生
listStatus和getFileStatus:都是向namenode发出http请求,地址是/listPaths/path/to/file
getFileChecksum:向namdenode发现http请求,地址是/fileChecksum/path/to/file
HftpFileSystem的工作目录是根目录,不能设置根目录,不支持append、create、rename、delete、mkdirs等操作。
还有一个HsftpFileSystem类,继承自HftpFileSystem,通过https与namenode连接,需要建立ssl。
类图如下:


相关文章推荐
- hdfs
- HDFS 和 YARN 的 HA 故障切换
- HDFS 用户手册
- Hive,Hbase,HDFS等之间的关系
- Map[Reduce] 的 setup 中读取 HDFS 文件夹信息
- hadoop2.7.1环境搭建
- Flume HDFS Sink使用及源码分析
- client如何访问HA HDFS
- HDFS初步学习的总结
- hdfs目录创建hive表
- HDFS升级和回滚机制
- HDFS的特性和目标
- 使用webhdfs
- [Hive]使用HDFS文件夹数据创建Hive表分区
- Hadoop集群_WordCount运行详解
- Spark将HDFS数据导入到HBase
- HDFS中block块大小设置问题
- hadoop2.7.1不重启,动态删除节点和新增节点
- Using the command line to manage files on HDFS--转载
- FilesystemReader输出HDFS上的文件内容