sed、grep
2015-12-31 14:28
204 查看
两个概念,通配符与正则表达式,这两个规范的实现都是由软件所提供的,如通配符:shell和find,而它们的实现之间还有区别如:shell的[ ]里面是不区分大小写的。而find是区分大小写的。
而正则表达式这一种更为强大的搜索规范所使用的软件如:vi,sed,grep,awk。
Linux上文本处理三剑客:
grep, egrep, fgrep:文本过滤工具(模式:pattern)工具;
grep:基本正则表达式,-E (egrep),-F(fgrep)
egrep:扩展正则表达式, -G(grep),-F(fgrep)
fgrep:不支持正则表达式,性能更好。
sed:stream editor, 流编辑器;文本编辑工具;
awk:Linux上的实现为gawk,文本报告生成器(格式化文本);
使用:/article/4404064.html
正则表达式:Regual Expression, REGEXP
由一类特殊字符(元字符)及文本字符所编写的模式,这些元字符不表示其字面意义,而是用于表示控制或通配的功能.
分两类:
基本正则表达式:BRE
扩展正则表达式:ERE
目录:
一、grep
1、正则表达式
2、扩展正则表达式
二、sed
一、grep
grep: Global search REgular expression and Print out the line.
作用:文本搜索工具,根据用户指定的“模式(过滤条件)”对目标文本逐行进行匹配检查;打印匹配到的行;
模式:由正则表达式的元字符及文本字符所编写出的过滤条件;
正则表达式引擎;
grep [OPTIONS] PATTERN [FILE...]
grep [OPTIONS] [-e PATTERN | -f FILE] [FILE...]
OPTIONS:
--color=auto:对匹配到的文本着色后高亮显示;
-i:ignorecase,忽略字符的大小写;
-o:仅显示匹配到的字符串本身;
-v, --invert-match:显示不能被模式匹配到的行;
-E:支持使用扩展的正则表达式元字符;
-q, --quiet, --silent:静默模式,即不输出任何信息;
-A #:after, 后#行
-B #:before,前#行
-C #:context,前后各#行
1、基本正则表达式
字符匹配:
上面的[ ]之间也可以用下面这些字符组。它们代表一部分字符的组合。
[:upper:] 大写字母[:lower:] 小写字母[:alpha:] 所有字母[:digit:] 所有数字[:alnum:] 所有字母和数字[:space:] 空格[:punct:] 标点符号
如:查找大写字母[[:upper:]]。里面的[:upper:]是一个整体,与外面的[ ]没有关系,所以不能省略。
次数匹配:用在要指定其出现的次数的字符的后面,用于限制其前面字符出现的次数;默认工作于贪婪模式;
位置锚定:用于指定字符出现的位置。
组:
分组括号中的模式匹配 到的内容会被正则表达式引擎自动记录于内部的变量中,这些变量为:
\1:模式从左侧起,第一个左括号以及与之匹配的右括号之间的模式所匹配到的字符;
\2:模式从左侧起,第二个左括号以及与之匹配的右括号之间的模式所匹配到的字符;
...
关于后向引用。老师上课的时候,所给出的很有意思的题。
找出前后一样的love或者like。就是前是love后面就要是love.
He loves his lover.
He likes his lover.
She likes her liker.
She loves her liker.
~]# grep "\(l..e\).*\1" lovers.txt

例、查找下以 f 开头,中间两个任意字符,以 m 结尾的都有哪些。
[root@star-linux ~]# grep "f..m" text.tx
But from behind the walls of doubt
[root@star-linux ~]#
例、 第一个字符要么是g 要么是m,中间是两个一样的,结尾一个d,怎么查 [ ] \{m\}
[root@star-linux ~]# grep "[gm].\{2\}d" text.tx
good morning everyone
I had a dream, I had an awesome dream
As we go down life's lonesome highway
[root@star-linux ~]#
结果出乎意料, 这是因为 . 是任意字符, 而\{2\} 是代表2个前面的字符,也就是两个任意字符了(包括空格),这个题做的有问题。在要求前后一样的情况下,就要用到后向引用了。
例、用组和后向引用。\(\) \# 后向引用
[root@star-linux ~]# grep "[gm]\(.\)\1d" text.tx
good morning everyone
[root@star-linux ~]#
我们要的是这个结果。 上面的意思就是小括号里面的 . 所匹配到的是什么结果,后面\1也就是什么结果, 在个例子中,小括号是 o , 那么 \1 也就是 o.
例、查找下行开头是A 或者 As 。 ^ \?
[root@star-linux ~]# grep "^As\?" text.tx
And what they played
A voice was crying out
As we go down life's lonesome highway
[root@star-linux ~]#
例、再查找个单词试试,way , 找这个单词,那我们就来试试。[root@star-linux ~]# grep "way" text.tx
Say it for always
That's the way it should be
Say it for always
That's the way it should beSay it for always
.........
[root@star-linux ~]#
What? 搞什么仙人板板,把有关way的字符串都给拉出来了。 那么 \< \>
[root@star-linux ~]# grep "\<way\>" text.tx
That's the way it should be
That's the way it should be
When you feel you've lost your way
That's the way it should be
That's the way it should be
[root@star-linux ~]#
\< \> 指定单词用的,这两个符号的两边只允许出现空格或者标点符号。如果是字母则不匹配。
例、查找以组为单位的重复字符。组的次数匹配, \(\) \{m,\}
[root@star-linux ~]# grep "\(way\)\{2,\}" text.tx
Say it for alway waywayway ways
[root@star-linux ~]#
这个意思就是,way这个整体,重复两次到无限多次。
例、再看看行尾是怎么回事,查找行尾是 . 的,有意思吧,注意 . 可是元字符,意思就不用说了吧, 那怎么让它变成普通字符, 转义字符\ $
[root@star-linux ~]# grep "\.$" text.tx
it's fine day today.
There are many birds flying in the sky.
[root@star-linux ~]#
\ 的功能就是转义。把有意义的字符,转成普通的。把普通字符转成有意义的,当然如果是彻彻底底的普通字符,再转也没用。
而在正则表达式里的加\的元字符, 是因为规范的问题所导致的,在grep所用的正则表达式里,那些需要加\的元字符,都是普通字符,需要加上\来转义,如果不加的话,它就是普通字符。
而在egrep 所用的扩展的正则表达式中, 除了\< \>和后向引用还要用转义外, 其它的都不用转义了,这又是另外的一种规范, 如果非要加转义符, 反而又变成普通字符了。
2、扩展正则表达式
主要区别就是次数匹配的元字符不用加\了.
egrep:
支持扩展的正则表达式实现类似于grep文本过滤功能;grep -E
egrep [OPTIONS] PATTERN [FILE...]
选项:
-i, -o, -v, -q, -A, -B, -C
-G:支持基本正则表达式
元字符:
次数匹配:
位置锚定:
分组:
跟基本正则表达式,除了不用加\以外,没有什么其它的区别。这里来些例子做些参考
取路径基名:

匹配IP地址:匹配1.0.0.1--223.255.255.254 IP地址的写法

匹配IP地址一般也没必要一定要匹配1-254之间。也可以直接匹配0-999的数字。

二、sed。
sed [OPTION]... 'script' [input-file] ...
script:地址定界编辑命令
常用选项:
-n:不输出模式空间中的内容至屏幕;
-e script, --expression=script:多点编辑;
-f /PATH/TO/SED_SCRIPT_FILE 从文件读取命令,每行一个编辑命令;
-r, --regexp-extended:扩展的正则表达式
-i[SUFFIX], --in-place[=SUFFIX]:直接编辑原文件 ;
地址定界:
(1) 空地址:对全文进行处理;
(2) 单地址:
#:指定行;
/pattern/:被此模式所匹配到的每一行;
(3) 地址范围
#,#:
#,+#:
#,/pat1/
/pat1/,/pat2/
$:最后一行;
(4) 步进:~
1~2:所有奇数行
2~2:所有偶数行
编辑命令:
d:删除;
p:显示模式空间中的内容;
a \text:在行后面追加文本“text”,支持使用\n实现多行追加;
i \text:在行前面插入文本“text”,支持使用\n实现多行插入;
以上如果text之前没有要显示的空字符,可以不用\.
c \text:把匹配到的行替换为此处指定的文本“text”;
w /PATH/TO/SOMEFILE:保存模式空间匹配到的行至指定的文件中;
r /PATH/FROM/SOMEFILE:读取指定文件的内容至当前文件被模式匹配到的行后面;文件合并;
=:为模式匹配到的行打印行号;
!:条件取反;格式:!编辑命令;
s///:查找替换,其分隔符可自行指定,常用的有s@@@, s###等;
替换标记:
g:全局替换;
w /PATH/TO/SOMEFILE:将替换成功的结果保存至指定文件中;
p:显示替换成功的行;
sed的工作方式:
每次在磁盘上读取一个块,要看读取文件的范围了。然后在内核所缓存的文件数据中按换行符一次读取一行数据,放到sed自己的内存空间(模式空间)来等待处理。
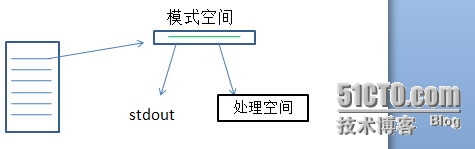
但处理的时候却还有点不一样,会复制一份数据直接stdout(默认屏幕),一份到处理空间处理。
虽然画的stdou与处理空间一点关系也没有,但还是有点关联的。在用d编译命令的时候,不会直接stdout。
地址定界:
例:输出passwd文件中的2-5行.
上面的-n就是常用选项,而2,5的部分就是地址定界,p就是编辑命令。
地址定界也可以用 /pattern/方式,如:
例:输出root所在的数据。
例:显示sshd用户到最后一行。
步进,从第几行开始,每次跨几行。如:
从20行开始,以3为跨度。
编辑命令:
上面的p和=号都有了,下面再来几个。(a,i,c)
添加多行。单引号是绝对引用所以回车也可以被sed识别,用\n代表换行也可以。如果不定界,就是空地址,会在所有行的下面加上这一堆数据。
而i就是在root行的下面插入一行。
编辑命令:d
sed '2d' 删除第二行
sed '2,5d' 删除2到5行
sed '2,$d' 删除2到尾行
sed '/star/d' 删除有star的行
编辑命令:s
sed '行号s/老的字符串/新的字符串/g'
以行单位查找匹配的字符串,然后替换。
sed 's/:/?/g' 把数据中所有行的:变成?。
sed '2,5s/:/?/g' 把2-5行的:变成?。
sed '/star/s/#/#star/g' 把有star的行中的#变成#star。
删除/etc/fstab文件中所有以#开头的行的行首的#号及#后面的所有空白字符;并且删除空行。
输出一个绝对路径给sed命令,取出其目录,其行为类似于dirname;
把/etc/fstab文件中的所有UUID的行,最后面的0变成1.
取出/boot/grub/grub.conf文件中的内核文件名称。
谢谢浏览,有什么不对的地方,还请指出。谢谢。
本文出自 “大蕃茄” 博客,请务必保留此出处http://fanqie.blog.51cto.com/9382669/1730391
而正则表达式这一种更为强大的搜索规范所使用的软件如:vi,sed,grep,awk。
Linux上文本处理三剑客:
grep, egrep, fgrep:文本过滤工具(模式:pattern)工具;
grep:基本正则表达式,-E (egrep),-F(fgrep)
egrep:扩展正则表达式, -G(grep),-F(fgrep)
fgrep:不支持正则表达式,性能更好。
sed:stream editor, 流编辑器;文本编辑工具;
awk:Linux上的实现为gawk,文本报告生成器(格式化文本);
使用:/article/4404064.html
正则表达式:Regual Expression, REGEXP
由一类特殊字符(元字符)及文本字符所编写的模式,这些元字符不表示其字面意义,而是用于表示控制或通配的功能.
分两类:
基本正则表达式:BRE
扩展正则表达式:ERE
目录:
一、grep
1、正则表达式
2、扩展正则表达式
二、sed
一、grep
grep: Global search REgular expression and Print out the line.
作用:文本搜索工具,根据用户指定的“模式(过滤条件)”对目标文本逐行进行匹配检查;打印匹配到的行;
模式:由正则表达式的元字符及文本字符所编写出的过滤条件;
正则表达式引擎;
grep [OPTIONS] PATTERN [FILE...]
grep [OPTIONS] [-e PATTERN | -f FILE] [FILE...]
OPTIONS:
--color=auto:对匹配到的文本着色后高亮显示;
-i:ignorecase,忽略字符的大小写;
-o:仅显示匹配到的字符串本身;
-v, --invert-match:显示不能被模式匹配到的行;
-E:支持使用扩展的正则表达式元字符;
-q, --quiet, --silent:静默模式,即不输出任何信息;
-A #:after, 后#行
-B #:before,前#行
-C #:context,前后各#行
1、基本正则表达式
字符匹配:
| . | 点号匹配任意单个字符。 |
| [] | 匹配里面的任意单个字符,如:[acdb] a,c,d,b,这四个单字符都会匹配 |
| [^] | 不匹配里面的任意单个字符。跟上面完全相反,这四个单字符都不会匹配。 |
[:upper:] 大写字母[:lower:] 小写字母[:alpha:] 所有字母[:digit:] 所有数字[:alnum:] 所有字母和数字[:space:] 空格[:punct:] 标点符号
如:查找大写字母[[:upper:]]。里面的[:upper:]是一个整体,与外面的[ ]没有关系,所以不能省略。
次数匹配:用在要指定其出现的次数的字符的后面,用于限制其前面字符出现的次数;默认工作于贪婪模式;
| * | 任意次前面的字符。包括0次。如:s* 没有s的也会匹配。 |
| .* | 只是一种应用方法,代表任意个任意字符。 |
| \? | 前面字符的0次或1次。 |
| \{m\} | 前面字符的m次。手动指定前面字符的次数。 |
| \{m,n\} | 前面的字符的m-n次。如:\{2,3\} 2-8次前面的字符。 |
| \{m,\} | 前面的字符至少m次。没有上限,只有下限。 |
| \{0,n\} | 前面的字符至多只有n次。也就是从0到n个。 |
| \+ | 前面的字符等于大于1次,与*相比,没有0次了。 |
| ^ | 指定行首 |
| $ | 指定行尾 |
| ^$ | 这个只是一种应用方法, 代表空白行。 行首跟着行尾 空白行。 |
| \<char | 查找以字符开头的单词。 用 \b 也行。 \bchar char是字符的意思。 |
| char\> | 查找以字符结尾的单词。 用\b 也行。 char\b |
| \(\) | 用于把单个字符组合成多个字符, 以组的方式再来次数匹配。 而且可以被引用。 组的功能:1、把多个字符组合成整体来做次数匹配。2、可以后向引用 |
| \# | 后向引用。#为数字,可以引用第#个组的匹配结果,也就是第#个小括号。注意引用的是组所匹配到的结果,而不是把组的功能给复制过来。 |
| \| | 或。如:"^abc|^def", 开头是abc,或者开头是def的。也可以"^\(abc\|def\)" |
\1:模式从左侧起,第一个左括号以及与之匹配的右括号之间的模式所匹配到的字符;
\2:模式从左侧起,第二个左括号以及与之匹配的右括号之间的模式所匹配到的字符;
...
关于后向引用。老师上课的时候,所给出的很有意思的题。
找出前后一样的love或者like。就是前是love后面就要是love.
He loves his lover.
He likes his lover.
She likes her liker.
She loves her liker.
~]# grep "\(l..e\).*\1" lovers.txt
例、查找下以 f 开头,中间两个任意字符,以 m 结尾的都有哪些。
[root@star-linux ~]# grep "f..m" text.tx
But from behind the walls of doubt
[root@star-linux ~]#
例、 第一个字符要么是g 要么是m,中间是两个一样的,结尾一个d,怎么查 [ ] \{m\}
[root@star-linux ~]# grep "[gm].\{2\}d" text.tx
good morning everyone
I had a dream, I had an awesome dream
As we go down life's lonesome highway
[root@star-linux ~]#
结果出乎意料, 这是因为 . 是任意字符, 而\{2\} 是代表2个前面的字符,也就是两个任意字符了(包括空格),这个题做的有问题。在要求前后一样的情况下,就要用到后向引用了。
例、用组和后向引用。\(\) \# 后向引用
[root@star-linux ~]# grep "[gm]\(.\)\1d" text.tx
good morning everyone
[root@star-linux ~]#
我们要的是这个结果。 上面的意思就是小括号里面的 . 所匹配到的是什么结果,后面\1也就是什么结果, 在个例子中,小括号是 o , 那么 \1 也就是 o.
例、查找下行开头是A 或者 As 。 ^ \?
[root@star-linux ~]# grep "^As\?" text.tx
And what they played
A voice was crying out
As we go down life's lonesome highway
[root@star-linux ~]#
例、再查找个单词试试,way , 找这个单词,那我们就来试试。[root@star-linux ~]# grep "way" text.tx
Say it for always
That's the way it should be
Say it for always
That's the way it should beSay it for always
.........
[root@star-linux ~]#
What? 搞什么仙人板板,把有关way的字符串都给拉出来了。 那么 \< \>
[root@star-linux ~]# grep "\<way\>" text.tx
That's the way it should be
That's the way it should be
When you feel you've lost your way
That's the way it should be
That's the way it should be
[root@star-linux ~]#
\< \> 指定单词用的,这两个符号的两边只允许出现空格或者标点符号。如果是字母则不匹配。
例、查找以组为单位的重复字符。组的次数匹配, \(\) \{m,\}
[root@star-linux ~]# grep "\(way\)\{2,\}" text.tx
Say it for alway waywayway ways
[root@star-linux ~]#
这个意思就是,way这个整体,重复两次到无限多次。
例、再看看行尾是怎么回事,查找行尾是 . 的,有意思吧,注意 . 可是元字符,意思就不用说了吧, 那怎么让它变成普通字符, 转义字符\ $
[root@star-linux ~]# grep "\.$" text.tx
it's fine day today.
There are many birds flying in the sky.
[root@star-linux ~]#
\ 的功能就是转义。把有意义的字符,转成普通的。把普通字符转成有意义的,当然如果是彻彻底底的普通字符,再转也没用。
而在正则表达式里的加\的元字符, 是因为规范的问题所导致的,在grep所用的正则表达式里,那些需要加\的元字符,都是普通字符,需要加上\来转义,如果不加的话,它就是普通字符。
而在egrep 所用的扩展的正则表达式中, 除了\< \>和后向引用还要用转义外, 其它的都不用转义了,这又是另外的一种规范, 如果非要加转义符, 反而又变成普通字符了。
2、扩展正则表达式
主要区别就是次数匹配的元字符不用加\了.
egrep:
支持扩展的正则表达式实现类似于grep文本过滤功能;grep -E
egrep [OPTIONS] PATTERN [FILE...]
选项:
-i, -o, -v, -q, -A, -B, -C
-G:支持基本正则表达式
元字符:
| . | 任意单个字符 |
| [] | 范围内的任意单个字符 |
| [^] | 范围外的任意单个字符 |
| * | 匹配任意次前面的字符 |
| ? | 匹配0或1次前面的字符 |
| + | 匹配至少1次前面的字符 |
| {m} | 匹配其前面的字符m次 |
| {m,n} | 匹配其前面的字符m-n次 |
| {m,} | 匹配其前面的字符至少m次 |
| {0,n} | 至多n次 |
| ^ | 行首 |
| $ | 行尾 |
| \<或\b | 词首 |
| \>或\b | 词尾 |
| ( ) | 分组。 组的功能 1、把多个字符组合成整体来做次数匹配。2、可以后向引用 |
| | | 或者 a|b:a或者b;C|cat:C或cat |
| (|) | 组中的或 (c|C)at:cat或Cat |
取路径基名:
匹配IP地址:匹配1.0.0.1--223.255.255.254 IP地址的写法
[root@localhost ~]# ifconfig | egrep '(\<(1?[0-9]?[0-9]|2[0-4][0-9]|25[0-5])\>\.){3}\<(1?[0-9]?[0-9]|2[0-4][0-9]|25[0-5])\>'
inet 172.16.249.185 netmask 255.255.0.0 broadcast 172.16.255.255
inet 192.168.189.190 netmask 255.255.255.0 broadcast 192.168.189.255
inet 127.0.0.1 netmask 255.0.0.0匹配IP地址一般也没必要一定要匹配1-254之间。也可以直接匹配0-999的数字。
[root@localhost ~]# ifconfig | grep -E --color=auto "\<([0-9]{1,3}\.){3}[0-9]{1,3}\>"
inet 172.16.249.185 netmask 255.255.0.0 broadcast 172.16.255.255
inet 192.168.189.190 netmask 255.255.255.0 broadcast 192.168.189.255
inet 127.0.0.1 netmask 255.0.0.0二、sed。
sed [OPTION]... 'script' [input-file] ...
script:地址定界编辑命令
常用选项:
-n:不输出模式空间中的内容至屏幕;
-e script, --expression=script:多点编辑;
-f /PATH/TO/SED_SCRIPT_FILE 从文件读取命令,每行一个编辑命令;
-r, --regexp-extended:扩展的正则表达式
-i[SUFFIX], --in-place[=SUFFIX]:直接编辑原文件 ;
地址定界:
(1) 空地址:对全文进行处理;
(2) 单地址:
#:指定行;
/pattern/:被此模式所匹配到的每一行;
(3) 地址范围
#,#:
#,+#:
#,/pat1/
/pat1/,/pat2/
$:最后一行;
(4) 步进:~
1~2:所有奇数行
2~2:所有偶数行
编辑命令:
d:删除;
p:显示模式空间中的内容;
a \text:在行后面追加文本“text”,支持使用\n实现多行追加;
i \text:在行前面插入文本“text”,支持使用\n实现多行插入;
以上如果text之前没有要显示的空字符,可以不用\.
c \text:把匹配到的行替换为此处指定的文本“text”;
w /PATH/TO/SOMEFILE:保存模式空间匹配到的行至指定的文件中;
r /PATH/FROM/SOMEFILE:读取指定文件的内容至当前文件被模式匹配到的行后面;文件合并;
=:为模式匹配到的行打印行号;
!:条件取反;格式:!编辑命令;
s///:查找替换,其分隔符可自行指定,常用的有s@@@, s###等;
替换标记:
g:全局替换;
w /PATH/TO/SOMEFILE:将替换成功的结果保存至指定文件中;
p:显示替换成功的行;
sed的工作方式:
每次在磁盘上读取一个块,要看读取文件的范围了。然后在内核所缓存的文件数据中按换行符一次读取一行数据,放到sed自己的内存空间(模式空间)来等待处理。
但处理的时候却还有点不一样,会复制一份数据直接stdout(默认屏幕),一份到处理空间处理。
虽然画的stdou与处理空间一点关系也没有,但还是有点关联的。在用d编译命令的时候,不会直接stdout。
地址定界:
例:输出passwd文件中的2-5行.
[root@localhost ~]# sed -n '2,5p' /etc/passwd bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin [root@localhost ~]#一般情况下,每行数据都会直接stdout出来。-n就是不要stdout。所以上面显示的只有处理完成的数据。
上面的-n就是常用选项,而2,5的部分就是地址定界,p就是编辑命令。
地址定界也可以用 /pattern/方式,如:
例:输出root所在的数据。
[root@localhost ~]# sed -n '/root/p' /etc/passwd root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin [root@localhost ~]# sed -n '/^root\>/p' /etc/passwd root:x:0:0:root:/root:/bin/bash [root@localhost ~]#上面第一个例子因为/pattern/写的不够严谨,所以匹配到了两行。
例:显示sshd用户到最后一行。
[root@localhost ~]# sed -n '/^sshd\>/,$p' /etc/passwd sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologin tcpdump:x:72:72::/:/sbin/nologin mageedu:x:1000:1000:MageEdu:/home/mageedu:/bin/bash sst:x:1001:1001::/home/sst:/bin/bash [root@localhost ~]#显示root和以下3行。
[root@localhost ~]# sed -n '/^root\>/,+3p' /etc/passwd root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin [root@localhost ~]#
步进,从第几行开始,每次跨几行。如:
从20行开始,以3为跨度。
[root@localhost ~]# sed -n '20~3p' /etc/passwd rpc:x:32:32:Rpcbind Daemon:/var/lib/rpcbind:/sbin/nologin chrony:x:996:994::/var/lib/chrony:/sbin/nologin ntp:x:38:38::/etc/ntp:/sbin/nologin编辑命令中有个=号,是用来显示所匹配到的数据的行号。
[root@localhost ~]# sed -n '20~3=' /etc/passwd 20 23 26
编辑命令:
上面的p和=号都有了,下面再来几个。(a,i,c)
[root@localhost ~]# sed '/^root\>/a drink tea' /etc/passwd root:x:0:0:root:/root:/bin/bash drink tea bin:x:1:1:bin:/bin:/sbin/nologin在root所在行的下面附加一行。a就是这个功能。
添加多行。单引号是绝对引用所以回车也可以被sed识别,用\n代表换行也可以。如果不定界,就是空地址,会在所有行的下面加上这一堆数据。
[root@localhost ~]# sed '2a drink tea\ > drink coffee\ > drink apple juicd' /etc/passwd root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin drink tea drink coffee drink apple juicd
而i就是在root行的下面插入一行。
[root@localhost ~]# sed '/^root\>/i drink tea' /etc/passwd drink tea root:x:0:0:root:/root:/bin/bash而c就是直接修改root行。
[root@localhost ~]# sed '/^root\>/c drink tea' /etc/passwd drink tea bin:x:1:1:bin:/bin:/sbin/nologin
编辑命令:d
sed '2d' 删除第二行
sed '2,5d' 删除2到5行
sed '2,$d' 删除2到尾行
sed '/star/d' 删除有star的行
编辑命令:s
sed '行号s/老的字符串/新的字符串/g'
以行单位查找匹配的字符串,然后替换。
sed 's/:/?/g' 把数据中所有行的:变成?。
sed '2,5s/:/?/g' 把2-5行的:变成?。
sed '/star/s/#/#star/g' 把有star的行中的#变成#star。
删除/etc/fstab文件中所有以#开头的行的行首的#号及#后面的所有空白字符;并且删除空行。
[root@localhost ~]# sed -e 's/^#[[:space:]]*//g' -e '/^$/d' /etc/fstab /etc/fstab Created by anaconda on Sun Dec 6 11:02:42 2015 Accessible filesystems, by reference, are maintained under '/dev/disk' See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info UUID=1f89bbf3-c25c-4b4b-aac8-284c19077770 / xfs defaults 0 0 UUID=1591ce0b-5726-4e03-8cbe-0a2105169930 /boot xfs defaults 0 0 UUID=0a527ef7-eb80-4155-9cd5-ea12fba99515 /usr xfs defaults 0 0 UUID=7f892a1b-055a-498f-a812-64086132157a swap swap defaults 0 0 [root@localhost ~]#
输出一个绝对路径给sed命令,取出其目录,其行为类似于dirname;
[root@localhost ~]# echo "/etc/sysconfig/network-scripts/ifcfg-eno16777736/" | sed -r 's/[^\/]+\/?$//' /etc/sysconfig/network-scripts/ [root@localhost ~]#
把/etc/fstab文件中的所有UUID的行,最后面的0变成1.
[root@localhost ~]# sed -r '/^UUID\>/s/0([[:space:]]*)$/1\1/g' /etc/fstab # # /etc/fstab # Created by anaconda on Sun Dec 6 11:02:42 2015 # # Accessible filesystems, by reference, are maintained under '/dev/disk' # See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info # UUID=1f89bbf3-c25c-4b4b-aac8-284c19077770 / xfs defaults 0 1 UUID=1591ce0b-5726-4e03-8cbe-0a2105169930 /boot xfs defaults 0 1 UUID=0a527ef7-eb80-4155-9cd5-ea12fba99515 /usr xfs defaults 0 1 UUID=7f892a1b-055a-498f-a812-64086132157a swap swap defaults 0 1
取出/boot/grub/grub.conf文件中的内核文件名称。
[root@localhost ~]# sed -n 's/^[[:space:]]\+kernel \/\(vmlinuz[^[:space:]]\+\).*$/\1/p' /boot/grub/grub.conf vmlinuz-2.6.32-573.el6.x86_64 [root@localhost ~]#
谢谢浏览,有什么不对的地方,还请指出。谢谢。
本文出自 “大蕃茄” 博客,请务必保留此出处http://fanqie.blog.51cto.com/9382669/1730391

相关文章推荐
- Spring概述
- Android Studio 快捷键
- 输出整数的所有划分
- Spring概述
- MongoDB学习笔记七:管理
- 抓包工具: WireShark; Fiddler; Charles
- ASP.NET MVC html help
- 二维码扫描利用ZBar实现
- Win10开发:Toast通知之应用激活
- 二进制和十六进制互转
- 卡尔曼滤波器跟踪
- VS低版本怎么打开高版本的工程
- 自定义DB连接池实现
- 自删除技术
- Struts2 实现上传整合excl导入
- PHP和串口通信的方法介绍
- apache ftp server 64位无法启动的问题
- ajax 提交数组 泛型集合
- UITableViewCell点击事件--可跳转到新界面
- maven 部署一个Java web application到本地(或者远程)的tomcat