Android NDK开发之 NEON基础介绍
2015-12-30 14:04
537 查看
这是官方介绍:
http://www.arm.com/zh/products/processors/technologies/neon.php
一、NEON简介
ARM® NEON™ 通用 SIMD 引擎可有效处理当前和将来的多媒体格式,从而改善用户体验。
NEON 技术可加速多媒体和信号处理算法(如视频编码/解码、2D/3D 图形、游戏、音频和语音处理、图像处理技术、电话和声音合成),其性能至少为 ARMv5 性能的 3 倍,为 ARMv6 SIMD 性能的 2 倍。
通过干净方式构建的 NEON 技术可无缝用于其本身的独立管道和寄存器文件。
NEON 技术是 ARM
Cortex™-A 系列处理器的 128 位 SIMD(单指令,多数据)架构扩展,旨在为消费性多媒体应用程序提供灵活、强大的加速功能,从而显著改善用户体验。它具有 32 个寄存器,64 位宽(双倍视图为 16 个寄存器,128 位宽。)
NEON 指令可执行“打包的 SIMD”处理:
寄存器被视为同一数据类型的元素的矢量
数据类型可为:有符号/无符号的 8 位、16 位、32 位、64 位单精度浮点
指令在所有通道中执行同一操作

使用 NEON 技术的 ARM Cortex™-A 系列处理器,以及 ARM 的 Mali 多媒体硬件解决方案可用于多媒体应用,范围从智能手机和移动计算设备到HDTV。
下图通过SISD(单指令单数据)和SIMD(单指令多数据)的对比,来说明NEON的工作原理:
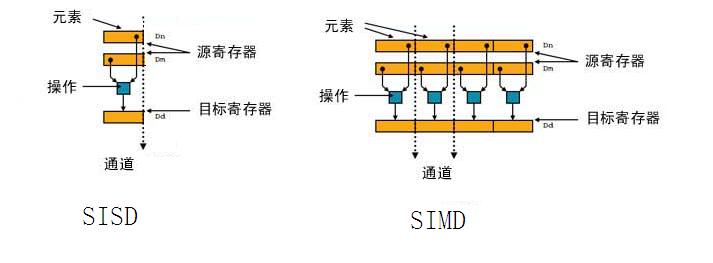
从图上可以看到,对于SISD,每个指令只能处理一个数据,而SIMD一个指令可以处理多个数据,因为多个数据的处理是平行的,因此从时间来说,一个指令执行的时间,SISD和SIMD是差不多的。由于SIMD一次可以处理N个数据,所以它的处理的时间也就缩短到SISD的1/N。
需要指出一点,NEON是需要硬件的支持的,需要有一块寄存器放到硬件上来处理这个的。
实际上ARM NEON的使用,是C方式调用,下面给出例子。
用C实现GRB灰度化算法

下面是一个用NEON现实的将GRB转化成灰度图的算法
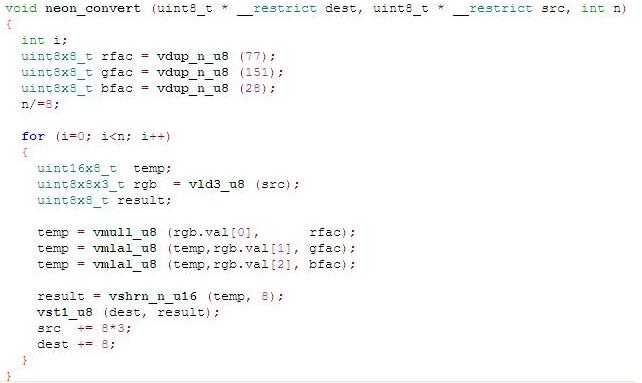
对以上函数进行说明如下:
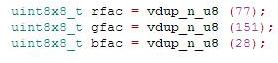
把权重放入NEON寄存器

一次载入8 pixles到三个NOEN寄存器,这个地方是重点可以说明NEON的高效率。

计算结果
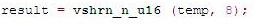
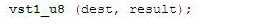
NEON函数参考gcc工具里面的gcc.pdf文档中NEON部分.
二、选择NEON的原因
NEON增强了用户体验
观看任意格式的任意视频
编辑和强化捕获的视频 – 视频稳定性
锯齿消除渲染和合成
游戏处理
快速处理几百万像素的照片
语音识别
强大的多通道高保真音频处理
NEON的特征和优点
NEON 支持用于 Internet 应用程序的范围广泛的多媒体编解码器:
许多软编解码器标准:MPEG-4、H.264、On2 VP6/7/8、Real、AVS
对于各种格式的正常大小的“Internet 流”解码来说,是理想的解决方案
不仅仅针对编解码器,还适用于 2D 和 3D 图形和其他矢量处理
提供现有工具、操作系统支持和生态体系支持
所需周期减少:
NEON 可使复杂视频编解码器的性能提升 60-150%
单个简单 DSP 算法可实现更大的性能提升(4 倍 -8 倍)
处理器可更快进入睡眠状态,从而在整体上节约了动态功耗
NEON 技术的大量元素能够提高性能并简化软件开发过程,如:
通过对齐和非对齐数据访问,可对 SIMD 操作进行有效的矢量化。
清晰的指令集架构,设计用于自动矢量化编译器和手动编码。
有效访问打包数组,如 ARGB 或 xyz 坐标
支持整数和浮点操作,以确保适合从编解码器、高性能计算到 3D 图形等广泛应用领域。
与 ARM 处理器紧密结合,提供单指令流和内存的统一视图,从而能够提供一个具有更简单工具流的开发平台目标。
通过具有双 128 位/64 位视图的大型 NEON 寄存器文件,可有效处理数据并尽可能减少对内存的访问,从而增加了数据吞吐量。
三、NEON应用
以源格式释放的库,在 ARM 网站上免费提供
支持以下格式:MPEG-4 简单配置文件、H.264 基准、JPEG、MP3、AAC
支持以下功能:FIR、IIR、FFT、点积、色彩空间转换、de-blocking.de-ringing、旋转、缩放、合成
受 ARM RealView 开发套件(v3.1 Pro 及更高版本)支持
在 2007q3 及更高版本中受 gcc 支持
支持 NEON 支持的所有数据类型和操作
在 ARM RealView 开发套件(3.1 及更高版本)和 gcc 2007q3 及更高版本中受支持
在 ARM 的
RealView 开发套件(3.1 及更高版本)和 gcc 2007q3 及更高版本中受支持
Android – NEON 优化
使用 NEON,Skia 库 S32A_D565_Opaque 的速度加快了 5 倍
Ubuntu 09.04 支持 NEON:
关键共享库的 NEON 版本
Bluez – 官方 Linux 蓝牙协议堆栈
NEON SBC 音频编码器
Pixman(Cairo 2D 图形库的一部分)
合成/alpha 混合
X.Org、Mozilla Firefox、Fennec 和 Webkit 浏览器
例如,使用 NEON 后,fbCompositeSolidMask_nx8x0565neon 的速度提高了 8 倍
ffmpeg - libavcodec
用于众多 Linux 分发版的 LGPL 媒体播放器
视频:MPEG-2、MPEG-4ASP、H.264 (AVC)、VC1
音频:Ogg Vorbis
x264 – Google 2009 年度编程之夏
GPL h.264 编码器 – 例如,针对视频会议
SIMD单指令流多数据流(SingleInstruction Multiple Data,SIMD)是一种采用一个控制器来控制多个处理器,同时对一组数据(又称“数据向量”)中的每一个分别执行相同的操作从而实现空间上的并行性的技术。在微处理器中,单指令流多数据流技术则是一个控制器控制多个平行的处理微元,例如Intel的MMX或SSE以及AMD的3D Now!技术。
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
MMX是由英特尔开发的一种SIMD多媒体指令集,共有57条指令。它于1996年集成在英特尔奔腾 (Pentium) MMX处理器上,以提高其多媒体数据的处理能力。
其优点是增加了处理器关于多媒体方面的处理能力,缺点是占用浮点数寄存器进行运算(64位MMX寄存器实际上就是浮点数寄存器的别名)以至于MMX 指令和浮点数操作不能同时工作。为了减少在MMX和浮点数模式切换之间所消耗的时间,程序员们尽可能减少模式切换的次数,也就是说,这两种操作在应用上是互斥的。后来英特尔在此基础上发展出SSE指令集;AMD在此基础上发展出3DNow!指令集。现在新开发的程序不再仅使用MMX来优化软件执行效能,而是改使用如SSE、3DNOW!等更容易优化效能的新一代多媒体指令集,不过目前的处理器仍可以执行针对MMX优化的较早期软件。
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
SSE
SSE(Streaming SIMD Extensions)是英特尔在AMD的3DNow!发布一年之后,在其计算机芯片Pentium III中引入的指令集,是继MMX的扩充指令集。SSE 指令集提供了 70 条新指令。AMD后来在Athlon XP中加入了对这个新指令集的支持。
SSE的缓存器
SSE 加入新的 8 个 128 位缓存器(XMM0~XMM7)。而 AMD 发表的x86-64延伸架构《又称 AMD64》再加入额外 8 个缓存器。除此之外还有一个新的 32 位的控制/状态缓存器(MXCSR)。不过只能在 64 位的模式下才能使用额外 8 个缓存器。
每 个缓存器可以容纳 4 个 32 位单精度浮点数,或是2 个 64 位双精度浮点数,或是 4 个 32 位整数,或是 8 个 16 位短整数,或是 16 个字符。整数运算能够使用正负号运算。而整数 SIMD 运算可能仍然要与 8 个 64 位 MMX 缓存器一起执行。
因为操作系统必须要在进程切换的时候保护这些 128 位的缓存器状态,除非操作系统去启动这些缓存器,否则默认值是不会去启用的。这表示操作系统必须要知道如何使用 FXSAVE 与 FXRSTOR 指令才能储存 x87 与 SSE 缓存器的状态。而在当时 IA-32 的主流操作系统很快的都加入了此功能。
由于 SSE 加入了浮点支持,SSE 就比MMX 更加常用。而 SSE2 加入了整数运算支持之后让SSE 更加的有弹性,当 MMX 变成是多余的指令集,SSE 指令集甚至可以与 MMX 并行运作,在某些时候可以提供额外的性能增进。
第一个支持 SSE 的 CPU 是 Pentium III,在FPU 与SSE 之间共享执行支持。当编译出来的软件能够交叉的同时以 FPU 与 SSE 运作,Pentium III 并无法在同一个周期中同时执行 FPU 与 SSE。这个限制降低了指令管线的有效性,不过 XMM 缓存器能够让 SIMD 与纯量浮点运算混合执行,而不会因为切换 MMX/浮点模式而产生性能的折损。
SSE指令表
SSE 提供纯量与包裹式(packed)浮点指令。
浮点指令
内存到缓存器/缓存器到内存/缓存器之间的数据搬移
纯量 – MOVSS
包裹式 – MOVAPS, MOVUPS, MOVLPS, MOVHPS, MOVLHPS, MOVHLPS
数学运算
纯量 – ADDSS, SUBSS, MULSS, DIVSS, RCPSS, SQRTSS, MAXSS, MINSS, RSQRTSS
包裹式 – ADDPS, SUBPS, MULPS, DIVPS, RCPPS, SQRTPS, MAXPS, MINPS, RSQRTPS
比较
纯量 – CMPSS, COMISS, UCOMISS
包裹式 – CMPPS
资料拆包(unpack)与随机搬移(shuffle)
包裹式 – SHUFPS, UNPCKHPS, UNPCKLPS
数据型态转换
纯量 – CVTSI2SS, CVTSS2SI, CVTTSS2SI
包裹式 – CVTPI2PS, CVTPS2PI, CVTTPS2PI
逐位逻辑运算
包裹式 – ANDPS, ORPS, XORPS, ANDNPS
整数指令
数学运算
PMULHUW, PSADBW, PAVGB, PAVGW, PMAXUB, PMINUB, PMAXSW, PMINSW
数据搬移
PEXTRW, PINSRW
其他
PMOVMSKB, PSHUFW
其他指令
MXCSR 管理
LDMXCSR, STMXCSR
快取与内存管理
MOVNTQ, MOVNTPS, MASKMOVQ, PREFETCH0, PREFETCH1, PREFETCH2, PREFETCHNTA, SFENCE
后续版本
SSE2
SSE2是 Intel在Pentium 4处理器的最初版本中引入的,但是AMD后来在Opteron 和Athlon64处理器中也加入了SSE2的支持。SSE2指令集添加了对64位双精度浮点数的支持,以及对整型数据的支持,也就是说这个指令集中所有的MMX指令都是多余的了,同时也避免了占用浮点数寄存器。这个指令集还增加了对CPU快取的控制指令。AMD对它的扩展增加了8个XMM寄存器,但是需要切换到64位 模式(x86-64/AMD64)才可以使用这些寄存器。Intel后来在其Intel 64架构中也增加了对x86-64的支持。
SSE3
SSE3是 Intel在Pentium 4处理器的 Prescott 核心中引入的第三代SIMD指令集,AMD在Athlon64的第五个版本,Venice核心中也加入了SSE3的支持。这个指令集扩展的指令包含寄存器的局部位之间的运算,例如高位和低位之间的加减运算;浮点数到整数的转换,以及对超线程技术的支持。
SSSE3
SSSE3是Intel针对SSE3指令集的一次额外扩充,最早内建于Core2 Duo处理器中。
SSE4
SSE4是Intel在Penryn核心的Core 2 Duo与Core2 Solo处理器时,新增的47条新多媒体指令集,并且现在更新至SSE4.2。AMD也开发了属于自己的SSE4a多媒体指令集,并内建在Phenom与 Opteron等K10架构处理器中,不过无法与Intel的SSE4系列指令集兼容。
SSE5
SSE5是AMD为了打破Intel垄断在处理器指令集的独霸地位所提出的,SSE5初期规划将加入超过100条新指令,其中最引人注目的就是三操作数指令(3-OperandInstructions)及熔合乘法累积(Fused Multiply Accumulate)。其中,三操作数指令让处理器可将一个数学或逻辑函式库,套用到操作数或输入数据。藉由增加操作数的数量,一个 x86 指令能处理二至三笔数据, SSE5 允许将多个简单指令汇整成一个指令,达到更有效率的指令处理模式。提升为三运算指令的运算能力,是少数RISC架构的水平。熔合乘法累积让允许建立新的指令,有效率地执行各种复杂的运算。熔合乘法累积可结合乘法与加法运算,透过单一指令执行多笔重复计算。透过简化程序码,让系统能迅速执行绘图着色、快速相片着色、音场音效,以及复杂向量演算等效能密集的应用作业。目前AMD已放弃下一代Bulldozer核心内建
SSE5指令集,改内建Intel授权SSE4系列指令集。
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
AVX
是Sandy Bridge和Larrabee架构新指令集 Intel的微架构也进入了全速发展的时期,在2010年4月结束的IDF峰会上Intel公司就发布了 2010年的RoadMap。2011年1月Intel发布全新的处理器微架构Sandy Bridge,其中全新增加的指令集也将带来CPU性能的提升。
AVX(Advanced Vector Extensions) 是Intel的SSE延伸架构,如IA16至IA32般的把缓存器XMM 128bit提升至YMM 256bit,以增加一倍的运算效率。此架构支持了三运算指令(3-Operand Instructions),减少在编码上需要先复制才能运算的动作。在微码部分使用了LES LDS这两少用的指令作为延伸指令Prefix。
FMA
FMA是Intel的AVX扩充指令集,如名称上熔合乘法累积(Fused Multiply Accumulate)的意思一样。
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
历史
1996年Intel首先推出了支持MMX的Pentium处理器,极大地提高了CPU处理多媒体数据的能力,被广泛地应用于语音合成、语音识别、音频视频编解码、图像处理和串流媒体等领域。但是MMX只支持整数运算,浮点数运算仍然要使用传统的x87协处理器指令。由于MMX与x87的寄存器相互重叠,在MMX代码中插入x87指令时必须先执行EMMS指令清除MMX状态,频繁地切换状态将严重影响性能。这限制了MMX指令在需要大量浮点运算的程序,如三维几何变换、裁剪和投影中的应用。
另一方面,由于x87古怪的堆栈式缓存器结构,使得硬件上将其流水线化和软件上合理调度指令都很困难,这成为提高x86架构浮点性能的一个瓶颈。
为了解决以上这两个问题,AMD公司于1998年推出了包含21条指令的3DNow!指令集,并在其K6-2处理器中实现。K6-2是第一个能执行浮点SIMD指令的x86处理器,也是第一个支持水平浮点寄存器模型的x86处理器。借助3DNow!,K6-2实现了x86处理器上最快的浮点单元,在每个时钟周期内最多可得到4个单精度浮点数结果,是传统x87协处理器的4倍。许多游戏厂商为3DNow!优化了程序,微软的DirectX 7也为3DNow!做了优化,AMD处理器的游戏性能第一次超过Intel,这大大提升了AMD在消费者心目中的地位。K6-2和随后的K6-III成为市场上的热门货。
1999年,随着Athlon处理器的推出,AMD为3DNow!增加了5条新的指令,用于增强其在DSP方面的性能,它们被称为“扩展3DNow!”(Extended 3DNow!)。
为了对抗3DNow!,Intel公司于1999年推出了SSE指令集。SSE几乎能提供3DNow!的所有功能,而且能在一条指令中处理两倍多的单精度浮点数;同时,SSE完全支持IEEE 754,在处理单精度浮点数时可以完全代替x87。这迅速瓦解了3DNow!的优势。
1999年后,随着主流操作系统和软件都开始支持SSE并为SSE优化,AMD在其2000年发布的代号为“Thunderbird”的 Athlon处理器中添加了对SSE的完全支持(“经典”的Athlon或K7只支持SSE中与MMX有关的部分,AMD称之为“扩展MMX”即 Extended MMX)。随后,AMD致力于AMD64架构的开发;在SIMD指令集方面,AMD跟随Intel,为自己的处理器添加SSE2和SSE3支持,而不再改进3DNow!。
2010年八月,AMD宣布将在新一代处理器中取消除了两条数据预取指令之外3DNow!指令的支持,并鼓励开发者将3DNow!代码重新用SSE实现。
支持检测
支持3DNow!的CPU的CPUID扩展功能字(EAX=80000001h时执行CPUID指令得到的EDX的内容)的(从低位到高位)第31位为1。支持扩展3DNow!的CPU的CPUID扩展功能字的(从低位到高位)第30位为1。
K6-2以后AMD所有的x86处理器都支持3DNow!,包括最新的Athlon 64、Opteron和Sempron处理器;Cyrix等一些其他厂家生产的某些处理器也支持3DNow!;但Intel生产的所有处理器都不支持3DNow!。
执行环境
3DNow!指令的执行环境与MMX一样,都是将8个x87寄存器ST0~ST7的低64位重命名为MMX寄存器MM0~MM7,并依平坦模式进行操作(即指令可以任意访问这8个寄存器中的任何一个而不必使用堆栈)。
由于3DNow!使用的寄存器与x87寄存器重叠,任务切换时,保存x87寄存器状态的同时也保存了3DNow!的状态,所以3DNow!不需要操作系统的额外支持。只要CPU支持3DNow!,含有3DNow!代码的程序可以在只考虑到x87状态的原有的操作系统上不加修改地运行。
由于3DNow!依平坦模式访问寄存器,对3DNow!浮点单元的管线化变得容易,这也利于编译器生成高效的浮点代码。
3DNow!指令集
3DNow!和扩展3DNow!的26条指令从功能上可以分为以下五类。
单精度浮点运算指令
此类指令的操作数均为64位,其高32位和低32位分别是IEEE754格式的单精度浮点数。大部分指令一次可接受两个这样的操作数,并得到两个单精度浮点数的结果。它们的汇编语言助记符都以PF开头。
3DNow!还包含有计算单精度倒数和开方倒数的指令,并可以依程序需要,得到12位精度和24位精度的结果。这些指令一次只能处理一个单精度浮点数。
3DNow!的一个特色是可以将同一寄存器内的64位操作数中的两个单精度浮点数相加或相乘,这在复数运算和内积运算中非常有用。Intel直到最近才在SSE3指令集中增加了这项功能,称之为“水平操作”。
为了保证与旧有操作系统的兼容性,与MMX指令一样,3DNow!指令不引发任何算术异常。3DNow!指令不会生成也不能正确处理NaN和非规格化数,也不支持指定舍入模式。因此3DNow!并不是IEEE 754的一个完整实现,即使是只涉及单精度浮点数时也不能完全代替x87。
增强的MMX指令
PAVGUSB用于求64位紧缩字节(8×8位字节)的平均值,可用于视频编码中的像素平均和图像缩放等。可能是意识到这个功能的重要性,Intel在SSE中添加了功能完全相同的PAVGB指令。
PMULHRW则用来补充MMX指令PMULHW的不足,在紧缩字(4×16位字)相乘时可以得到比后者更准确的结果。Intel直到最近才在SSSE3中增加了功能相似的指令PMULHRSW。
PSWAPD指令用于交换紧缩双字(2×32位字)中两个双字数据的位置。
数据类型转换指令
PF2ID、PI2FD等4条指令用于完成整数和单精度浮点数之间的相互转换。
数据预取指令
PREFETCH/PREFETCHW指令用于把将要使用到的数据从主存储器提前加载快取中,以减少访问主存储器的指令执行时的延迟。Intel在SSE中添加了类似的PREFETCHTx指令
快速退出MMX状态指令
FEMMS指令与MMX中的EMMS功能相同,用于退出MMX状态。在K6-2和K6-III处理器中,FEMMS比EMMS更快;在Athlon及更新的处理器中,FEMMS等同于EMMS。
http://www.arm.com/zh/products/processors/technologies/neon.php
一、NEON简介
ARM® NEON™ 通用 SIMD 引擎可有效处理当前和将来的多媒体格式,从而改善用户体验。
NEON 技术可加速多媒体和信号处理算法(如视频编码/解码、2D/3D 图形、游戏、音频和语音处理、图像处理技术、电话和声音合成),其性能至少为 ARMv5 性能的 3 倍,为 ARMv6 SIMD 性能的 2 倍。
通过干净方式构建的 NEON 技术可无缝用于其本身的独立管道和寄存器文件。
NEON 技术是 ARM
Cortex™-A 系列处理器的 128 位 SIMD(单指令,多数据)架构扩展,旨在为消费性多媒体应用程序提供灵活、强大的加速功能,从而显著改善用户体验。它具有 32 个寄存器,64 位宽(双倍视图为 16 个寄存器,128 位宽。)
NEON 指令可执行“打包的 SIMD”处理:
寄存器被视为同一数据类型的元素的矢量
数据类型可为:有符号/无符号的 8 位、16 位、32 位、64 位单精度浮点
指令在所有通道中执行同一操作
使用 NEON 技术的 ARM Cortex™-A 系列处理器,以及 ARM 的 Mali 多媒体硬件解决方案可用于多媒体应用,范围从智能手机和移动计算设备到HDTV。
下图通过SISD(单指令单数据)和SIMD(单指令多数据)的对比,来说明NEON的工作原理:
从图上可以看到,对于SISD,每个指令只能处理一个数据,而SIMD一个指令可以处理多个数据,因为多个数据的处理是平行的,因此从时间来说,一个指令执行的时间,SISD和SIMD是差不多的。由于SIMD一次可以处理N个数据,所以它的处理的时间也就缩短到SISD的1/N。
需要指出一点,NEON是需要硬件的支持的,需要有一块寄存器放到硬件上来处理这个的。
实际上ARM NEON的使用,是C方式调用,下面给出例子。
用C实现GRB灰度化算法
下面是一个用NEON现实的将GRB转化成灰度图的算法
对以上函数进行说明如下:
把权重放入NEON寄存器
一次载入8 pixles到三个NOEN寄存器,这个地方是重点可以说明NEON的高效率。
计算结果
NEON函数参考gcc工具里面的gcc.pdf文档中NEON部分.
二、选择NEON的原因
NEON增强了用户体验
观看任意格式的任意视频
编辑和强化捕获的视频 – 视频稳定性
锯齿消除渲染和合成
游戏处理
快速处理几百万像素的照片
语音识别
强大的多通道高保真音频处理
NEON的特征和优点
NEON 支持用于 Internet 应用程序的范围广泛的多媒体编解码器:
许多软编解码器标准:MPEG-4、H.264、On2 VP6/7/8、Real、AVS
对于各种格式的正常大小的“Internet 流”解码来说,是理想的解决方案
不仅仅针对编解码器,还适用于 2D 和 3D 图形和其他矢量处理
提供现有工具、操作系统支持和生态体系支持
所需周期减少:
NEON 可使复杂视频编解码器的性能提升 60-150%
单个简单 DSP 算法可实现更大的性能提升(4 倍 -8 倍)
处理器可更快进入睡眠状态,从而在整体上节约了动态功耗
NEON 技术的大量元素能够提高性能并简化软件开发过程,如:
通过对齐和非对齐数据访问,可对 SIMD 操作进行有效的矢量化。
清晰的指令集架构,设计用于自动矢量化编译器和手动编码。
有效访问打包数组,如 ARGB 或 xyz 坐标
支持整数和浮点操作,以确保适合从编解码器、高性能计算到 3D 图形等广泛应用领域。
与 ARM 处理器紧密结合,提供单指令流和内存的统一视图,从而能够提供一个具有更简单工具流的开发平台目标。
通过具有双 128 位/64 位视图的大型 NEON 寄存器文件,可有效处理数据并尽可能减少对内存的访问,从而增加了数据吞吐量。
三、NEON应用
OpenMAX DL 库:
加速 AV 编解码器的建议方法以源格式释放的库,在 ARM 网站上免费提供
支持以下格式:MPEG-4 简单配置文件、H.264 基准、JPEG、MP3、AAC
支持以下功能:FIR、IIR、FFT、点积、色彩空间转换、de-blocking.de-ringing、旋转、缩放、合成
矢量化编译器:
使用现有源代码自动搜索 NEON SIMD受 ARM RealView 开发套件(v3.1 Pro 及更高版本)支持
在 2007q3 及更高版本中受 gcc 支持
C 内部函数:
C 函数调用接口至 NEON 操作支持 NEON 支持的所有数据类型和操作
在 ARM RealView 开发套件(3.1 及更高版本)和 gcc 2007q3 及更高版本中受支持
汇编器:
针对确实需要在最低级别进行优化的用户在 ARM 的
RealView 开发套件(3.1 及更高版本)和 gcc 2007q3 及更高版本中受支持
开源社区中的 NEON 支持
当前,在以下开源项目中支持 NEON:Android – NEON 优化
使用 NEON,Skia 库 S32A_D565_Opaque 的速度加快了 5 倍
Ubuntu 09.04 支持 NEON:
关键共享库的 NEON 版本
Bluez – 官方 Linux 蓝牙协议堆栈
NEON SBC 音频编码器
Pixman(Cairo 2D 图形库的一部分)
合成/alpha 混合
X.Org、Mozilla Firefox、Fennec 和 Webkit 浏览器
例如,使用 NEON 后,fbCompositeSolidMask_nx8x0565neon 的速度提高了 8 倍
ffmpeg - libavcodec
用于众多 Linux 分发版的 LGPL 媒体播放器
视频:MPEG-2、MPEG-4ASP、H.264 (AVC)、VC1
音频:Ogg Vorbis
x264 – Google 2009 年度编程之夏
GPL h.264 编码器 – 例如,针对视频会议
【整理】SIMD、MMX、SSE、AVX、3D Now!、neon
SIMDSIMD单指令流多数据流(SingleInstruction Multiple Data,SIMD)是一种采用一个控制器来控制多个处理器,同时对一组数据(又称“数据向量”)中的每一个分别执行相同的操作从而实现空间上的并行性的技术。在微处理器中,单指令流多数据流技术则是一个控制器控制多个平行的处理微元,例如Intel的MMX或SSE以及AMD的3D Now!技术。
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
MMX是由英特尔开发的一种SIMD多媒体指令集,共有57条指令。它于1996年集成在英特尔奔腾 (Pentium) MMX处理器上,以提高其多媒体数据的处理能力。
其优点是增加了处理器关于多媒体方面的处理能力,缺点是占用浮点数寄存器进行运算(64位MMX寄存器实际上就是浮点数寄存器的别名)以至于MMX 指令和浮点数操作不能同时工作。为了减少在MMX和浮点数模式切换之间所消耗的时间,程序员们尽可能减少模式切换的次数,也就是说,这两种操作在应用上是互斥的。后来英特尔在此基础上发展出SSE指令集;AMD在此基础上发展出3DNow!指令集。现在新开发的程序不再仅使用MMX来优化软件执行效能,而是改使用如SSE、3DNOW!等更容易优化效能的新一代多媒体指令集,不过目前的处理器仍可以执行针对MMX优化的较早期软件。
技术细节
MMX 寄存器,称作MM0到MM7,实际上就是处理器内部80比特字长的浮点寄存器栈st(0)到st(7)的尾数部分(64比特长)的复用。由于浮点栈寄存器的高16位未被MMX技术使用,因此这16位都置为1,因此从栈寄存器的角度看,其浮点值为NaN或Infinities,这可用于区分寄存器是处于浮点栈状态还是MMX状态. 作为MMX寄存器都是直接访问。利用了装配数据类型(packed data type)的概念,每个MMX寄存器的64比特字长可以看作是2个32位整数、或者4个16位整数、或者8个8位整数,从而可以执行整数SIMD运算。这对于1990年代中期的2D、3D计算的加速还是很有意义的,因为当时的计算机的图形处理器(GPU)还很不发达。但现在MMX整数SIMD运算对于图形运算来说是多余的技术了。不过MMX的饱和算术运算(saturationarithmeticoperations)对于一些数字信号处理应用还是有用的。SIMD技术的发展
继 MMX技术之后,Intel又于1999年在Pentium-III处理器上推出SSE技术,引入了新的128比特宽的寄存器集 (register file),称作XMM0到XMM7。这些XMM寄存器用于4个单精度浮点数运算的SIMD执行,并可以与MMX整数运算或x87浮点运算混合执行。 2001年在Pentium 4上引入了SSE2技术,进一步扩展了指令集,使得XMM寄存器上可以执行8/16/32位宽的整数SIMD运算或双精度浮点数的SIMD运算。这使得 SIMD技术基本完善。--------------------------------------------------------------------------------------------------------------------------------------------------------------------
SSE
SSE(Streaming SIMD Extensions)是英特尔在AMD的3DNow!发布一年之后,在其计算机芯片Pentium III中引入的指令集,是继MMX的扩充指令集。SSE 指令集提供了 70 条新指令。AMD后来在Athlon XP中加入了对这个新指令集的支持。
| 目录 [隐藏] 1 SSE 的缓存器 2 SSE 指令表 2.1 浮点指令 2.2 整数指令 2.3 其他指令 3 后续版本 3.1 SSE2 3.2 SSE3 3.3 SSSE3 3.4 SSE4 3.5 SSE5 3.6 AVX 3.7 FMA 4 参见 |
SSE 加入新的 8 个 128 位缓存器(XMM0~XMM7)。而 AMD 发表的x86-64延伸架构《又称 AMD64》再加入额外 8 个缓存器。除此之外还有一个新的 32 位的控制/状态缓存器(MXCSR)。不过只能在 64 位的模式下才能使用额外 8 个缓存器。
每 个缓存器可以容纳 4 个 32 位单精度浮点数,或是2 个 64 位双精度浮点数,或是 4 个 32 位整数,或是 8 个 16 位短整数,或是 16 个字符。整数运算能够使用正负号运算。而整数 SIMD 运算可能仍然要与 8 个 64 位 MMX 缓存器一起执行。
因为操作系统必须要在进程切换的时候保护这些 128 位的缓存器状态,除非操作系统去启动这些缓存器,否则默认值是不会去启用的。这表示操作系统必须要知道如何使用 FXSAVE 与 FXRSTOR 指令才能储存 x87 与 SSE 缓存器的状态。而在当时 IA-32 的主流操作系统很快的都加入了此功能。
由于 SSE 加入了浮点支持,SSE 就比MMX 更加常用。而 SSE2 加入了整数运算支持之后让SSE 更加的有弹性,当 MMX 变成是多余的指令集,SSE 指令集甚至可以与 MMX 并行运作,在某些时候可以提供额外的性能增进。
第一个支持 SSE 的 CPU 是 Pentium III,在FPU 与SSE 之间共享执行支持。当编译出来的软件能够交叉的同时以 FPU 与 SSE 运作,Pentium III 并无法在同一个周期中同时执行 FPU 与 SSE。这个限制降低了指令管线的有效性,不过 XMM 缓存器能够让 SIMD 与纯量浮点运算混合执行,而不会因为切换 MMX/浮点模式而产生性能的折损。
SSE指令表
SSE 提供纯量与包裹式(packed)浮点指令。
浮点指令
内存到缓存器/缓存器到内存/缓存器之间的数据搬移
纯量 – MOVSS
包裹式 – MOVAPS, MOVUPS, MOVLPS, MOVHPS, MOVLHPS, MOVHLPS
数学运算
纯量 – ADDSS, SUBSS, MULSS, DIVSS, RCPSS, SQRTSS, MAXSS, MINSS, RSQRTSS
包裹式 – ADDPS, SUBPS, MULPS, DIVPS, RCPPS, SQRTPS, MAXPS, MINPS, RSQRTPS
比较
纯量 – CMPSS, COMISS, UCOMISS
包裹式 – CMPPS
资料拆包(unpack)与随机搬移(shuffle)
包裹式 – SHUFPS, UNPCKHPS, UNPCKLPS
数据型态转换
纯量 – CVTSI2SS, CVTSS2SI, CVTTSS2SI
包裹式 – CVTPI2PS, CVTPS2PI, CVTTPS2PI
逐位逻辑运算
包裹式 – ANDPS, ORPS, XORPS, ANDNPS
整数指令
数学运算
PMULHUW, PSADBW, PAVGB, PAVGW, PMAXUB, PMINUB, PMAXSW, PMINSW
数据搬移
PEXTRW, PINSRW
其他
PMOVMSKB, PSHUFW
其他指令
MXCSR 管理
LDMXCSR, STMXCSR
快取与内存管理
MOVNTQ, MOVNTPS, MASKMOVQ, PREFETCH0, PREFETCH1, PREFETCH2, PREFETCHNTA, SFENCE
后续版本
SSE2
SSE2是 Intel在Pentium 4处理器的最初版本中引入的,但是AMD后来在Opteron 和Athlon64处理器中也加入了SSE2的支持。SSE2指令集添加了对64位双精度浮点数的支持,以及对整型数据的支持,也就是说这个指令集中所有的MMX指令都是多余的了,同时也避免了占用浮点数寄存器。这个指令集还增加了对CPU快取的控制指令。AMD对它的扩展增加了8个XMM寄存器,但是需要切换到64位 模式(x86-64/AMD64)才可以使用这些寄存器。Intel后来在其Intel 64架构中也增加了对x86-64的支持。
SSE3
SSE3是 Intel在Pentium 4处理器的 Prescott 核心中引入的第三代SIMD指令集,AMD在Athlon64的第五个版本,Venice核心中也加入了SSE3的支持。这个指令集扩展的指令包含寄存器的局部位之间的运算,例如高位和低位之间的加减运算;浮点数到整数的转换,以及对超线程技术的支持。
SSSE3
SSSE3是Intel针对SSE3指令集的一次额外扩充,最早内建于Core2 Duo处理器中。
SSE4
SSE4是Intel在Penryn核心的Core 2 Duo与Core2 Solo处理器时,新增的47条新多媒体指令集,并且现在更新至SSE4.2。AMD也开发了属于自己的SSE4a多媒体指令集,并内建在Phenom与 Opteron等K10架构处理器中,不过无法与Intel的SSE4系列指令集兼容。
SSE5
SSE5是AMD为了打破Intel垄断在处理器指令集的独霸地位所提出的,SSE5初期规划将加入超过100条新指令,其中最引人注目的就是三操作数指令(3-OperandInstructions)及熔合乘法累积(Fused Multiply Accumulate)。其中,三操作数指令让处理器可将一个数学或逻辑函式库,套用到操作数或输入数据。藉由增加操作数的数量,一个 x86 指令能处理二至三笔数据, SSE5 允许将多个简单指令汇整成一个指令,达到更有效率的指令处理模式。提升为三运算指令的运算能力,是少数RISC架构的水平。熔合乘法累积让允许建立新的指令,有效率地执行各种复杂的运算。熔合乘法累积可结合乘法与加法运算,透过单一指令执行多笔重复计算。透过简化程序码,让系统能迅速执行绘图着色、快速相片着色、音场音效,以及复杂向量演算等效能密集的应用作业。目前AMD已放弃下一代Bulldozer核心内建
SSE5指令集,改内建Intel授权SSE4系列指令集。
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
AVX
是Sandy Bridge和Larrabee架构新指令集 Intel的微架构也进入了全速发展的时期,在2010年4月结束的IDF峰会上Intel公司就发布了 2010年的RoadMap。2011年1月Intel发布全新的处理器微架构Sandy Bridge,其中全新增加的指令集也将带来CPU性能的提升。
AVX(Advanced Vector Extensions) 是Intel的SSE延伸架构,如IA16至IA32般的把缓存器XMM 128bit提升至YMM 256bit,以增加一倍的运算效率。此架构支持了三运算指令(3-Operand Instructions),减少在编码上需要先复制才能运算的动作。在微码部分使用了LES LDS这两少用的指令作为延伸指令Prefix。
FMA
FMA是Intel的AVX扩充指令集,如名称上熔合乘法累积(Fused Multiply Accumulate)的意思一样。
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
3DNow!
3DNow!(据称是“3D No Waiting!”的缩写)是由AMD开发的一套SIMD多媒体指令集,支持单精度浮点数的矢量运算,用于增强x86架构的计算机在三维图像处理上的性能。| 目录 [隐藏] 1 历史 2 支持检测 3 执行环境 4 3DNow!指令集 4.1 单精度浮点运算指令 4.2 增强的MMX指令 4.3 数据类型转换指令 4.4 数据预取指令 4.5 快速退出MMX状态指令 5 外部链接 |
1996年Intel首先推出了支持MMX的Pentium处理器,极大地提高了CPU处理多媒体数据的能力,被广泛地应用于语音合成、语音识别、音频视频编解码、图像处理和串流媒体等领域。但是MMX只支持整数运算,浮点数运算仍然要使用传统的x87协处理器指令。由于MMX与x87的寄存器相互重叠,在MMX代码中插入x87指令时必须先执行EMMS指令清除MMX状态,频繁地切换状态将严重影响性能。这限制了MMX指令在需要大量浮点运算的程序,如三维几何变换、裁剪和投影中的应用。
另一方面,由于x87古怪的堆栈式缓存器结构,使得硬件上将其流水线化和软件上合理调度指令都很困难,这成为提高x86架构浮点性能的一个瓶颈。
为了解决以上这两个问题,AMD公司于1998年推出了包含21条指令的3DNow!指令集,并在其K6-2处理器中实现。K6-2是第一个能执行浮点SIMD指令的x86处理器,也是第一个支持水平浮点寄存器模型的x86处理器。借助3DNow!,K6-2实现了x86处理器上最快的浮点单元,在每个时钟周期内最多可得到4个单精度浮点数结果,是传统x87协处理器的4倍。许多游戏厂商为3DNow!优化了程序,微软的DirectX 7也为3DNow!做了优化,AMD处理器的游戏性能第一次超过Intel,这大大提升了AMD在消费者心目中的地位。K6-2和随后的K6-III成为市场上的热门货。
1999年,随着Athlon处理器的推出,AMD为3DNow!增加了5条新的指令,用于增强其在DSP方面的性能,它们被称为“扩展3DNow!”(Extended 3DNow!)。
为了对抗3DNow!,Intel公司于1999年推出了SSE指令集。SSE几乎能提供3DNow!的所有功能,而且能在一条指令中处理两倍多的单精度浮点数;同时,SSE完全支持IEEE 754,在处理单精度浮点数时可以完全代替x87。这迅速瓦解了3DNow!的优势。
1999年后,随着主流操作系统和软件都开始支持SSE并为SSE优化,AMD在其2000年发布的代号为“Thunderbird”的 Athlon处理器中添加了对SSE的完全支持(“经典”的Athlon或K7只支持SSE中与MMX有关的部分,AMD称之为“扩展MMX”即 Extended MMX)。随后,AMD致力于AMD64架构的开发;在SIMD指令集方面,AMD跟随Intel,为自己的处理器添加SSE2和SSE3支持,而不再改进3DNow!。
2010年八月,AMD宣布将在新一代处理器中取消除了两条数据预取指令之外3DNow!指令的支持,并鼓励开发者将3DNow!代码重新用SSE实现。
支持检测
支持3DNow!的CPU的CPUID扩展功能字(EAX=80000001h时执行CPUID指令得到的EDX的内容)的(从低位到高位)第31位为1。支持扩展3DNow!的CPU的CPUID扩展功能字的(从低位到高位)第30位为1。
K6-2以后AMD所有的x86处理器都支持3DNow!,包括最新的Athlon 64、Opteron和Sempron处理器;Cyrix等一些其他厂家生产的某些处理器也支持3DNow!;但Intel生产的所有处理器都不支持3DNow!。
执行环境
3DNow!指令的执行环境与MMX一样,都是将8个x87寄存器ST0~ST7的低64位重命名为MMX寄存器MM0~MM7,并依平坦模式进行操作(即指令可以任意访问这8个寄存器中的任何一个而不必使用堆栈)。
由于3DNow!使用的寄存器与x87寄存器重叠,任务切换时,保存x87寄存器状态的同时也保存了3DNow!的状态,所以3DNow!不需要操作系统的额外支持。只要CPU支持3DNow!,含有3DNow!代码的程序可以在只考虑到x87状态的原有的操作系统上不加修改地运行。
由于3DNow!依平坦模式访问寄存器,对3DNow!浮点单元的管线化变得容易,这也利于编译器生成高效的浮点代码。
3DNow!指令集
3DNow!和扩展3DNow!的26条指令从功能上可以分为以下五类。
单精度浮点运算指令
此类指令的操作数均为64位,其高32位和低32位分别是IEEE754格式的单精度浮点数。大部分指令一次可接受两个这样的操作数,并得到两个单精度浮点数的结果。它们的汇编语言助记符都以PF开头。
3DNow!还包含有计算单精度倒数和开方倒数的指令,并可以依程序需要,得到12位精度和24位精度的结果。这些指令一次只能处理一个单精度浮点数。
3DNow!的一个特色是可以将同一寄存器内的64位操作数中的两个单精度浮点数相加或相乘,这在复数运算和内积运算中非常有用。Intel直到最近才在SSE3指令集中增加了这项功能,称之为“水平操作”。
为了保证与旧有操作系统的兼容性,与MMX指令一样,3DNow!指令不引发任何算术异常。3DNow!指令不会生成也不能正确处理NaN和非规格化数,也不支持指定舍入模式。因此3DNow!并不是IEEE 754的一个完整实现,即使是只涉及单精度浮点数时也不能完全代替x87。
增强的MMX指令
PAVGUSB用于求64位紧缩字节(8×8位字节)的平均值,可用于视频编码中的像素平均和图像缩放等。可能是意识到这个功能的重要性,Intel在SSE中添加了功能完全相同的PAVGB指令。
PMULHRW则用来补充MMX指令PMULHW的不足,在紧缩字(4×16位字)相乘时可以得到比后者更准确的结果。Intel直到最近才在SSSE3中增加了功能相似的指令PMULHRSW。
PSWAPD指令用于交换紧缩双字(2×32位字)中两个双字数据的位置。
数据类型转换指令
PF2ID、PI2FD等4条指令用于完成整数和单精度浮点数之间的相互转换。
数据预取指令
PREFETCH/PREFETCHW指令用于把将要使用到的数据从主存储器提前加载快取中,以减少访问主存储器的指令执行时的延迟。Intel在SSE中添加了类似的PREFETCHTx指令
快速退出MMX状态指令
FEMMS指令与MMX中的EMMS功能相同,用于退出MMX状态。在K6-2和K6-III处理器中,FEMMS比EMMS更快;在Athlon及更新的处理器中,FEMMS等同于EMMS。

相关文章推荐
- android:活动的最佳实践
- android-Managing Audio Playback
- Android:活动的启动模式
- [置顶]android 内存溢出的一些想法
- android自定义控件初解
- android测试工具
- 对于Android stdio 新建工程出错的经验
- Android开发之应用与开发环境(一)
- Android的短信的使用
- Android 使用ORMLite 操作数据库
- android:activity活动的生命周期
- android 十进制颜色值转化为十六进制颜色值的方法
- Android开发笔记(三十四)Excel文件的读写
- Fragment+ViewPager(一)
- android studio 9patch图
- 深入理解:Android 编译系统
- android studio添加第三方.os库
- Silk编解码在android实现
- Android 5.1 Lollipop Phone工作流程浅析(十三)__InCallActivity启动Performance浅析
- speex编解码在android上实现