python学习笔记之基础二(第二天)
2015-12-19 23:10
621 查看
银角大王之博客二:
http://www.cnblogs.com/wupeiqi/articles/4911365.html
1、编码转换介绍
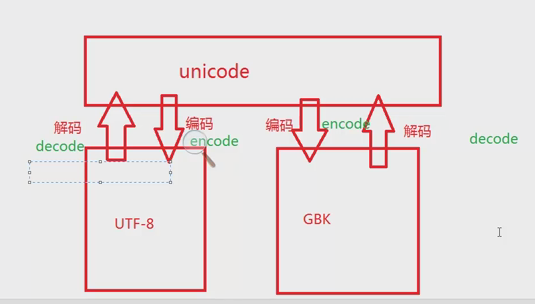
unicode是最底层、最纯的,会根据终端的编码进行转化展示
一般硬盘存储或传输为utf-8(因为省空间、省带宽),读入内存中为unicode,二者如何转换
a = '你好' '\xe4\xbd\xa0\xe5\xa5\xbd' <type 'str'>
b = u'你好' u'\u4f60\u597d' <type 'unicode'>
a.decode('utf-8') u'\u4f60\u597d' (utf-8格式解码为unicode)
b.encode('utf-8') '\xe4\xbd\xa0\xe5\xa5\xbd' (unicode格式加密为utf-8)
注:在python2.7版本中需要如上转换,在脚本中如要显示中文,
只要在文件开头加入 # _*_ coding: UTF-8 _*_ 或者 #coding=utf-8 就行了
在python3.4以后版本,无需转换
2、字符串的常用函数format:
S.format(*args, **kwargs) -> string
Return a formatted version of S, using substitutions from args and kwargs.
The substitutions are identified by braces ('{' and '}').
3、元组的元素是不能被修改,但元素的元素能可以被被修改的
4、字典的循环
当数据量达到上百万时,循环字典就不适合用dict.items(),因为首先会把一对对key和value转化为列表,然后在循环遍历输出,会增加内存使用。建议使用如下:
5、调用系统命令,并存入变量:
1.import os
a = os.system('df -Th')
b = os.popen('df -Th','r') 返回一个文件对象
c = os.path.dirname(os.path.abspath(__file__)) 获取当前的目录
2.import commands
c = commands.getoutput('df -Th') 返回一个字符串
6、sys调用
import sys
sys.exit
print sys.argv
sys.path
7、导入模板方法:
1.import sys [as newname]
多次重复使用import语句时,不会重新加载被指定的模块,只是把对该模块的内存地址给引用到本地变量环境。
2.from sys import argv或(*)
3.reload()
reload会重新加载已加载的模块,但原来已经使用的实例还是会使用旧的模块,而新生产的实例会使用新的模块;reload后还是用原来的内存地址;不能支持from。。import。。格式的模块进行重新加载。
建议使用第一种,第二种导入的对象或变量会与当前的变量会冲突。
8、字典复制:
dict = {'name':'wang', 'sex':'m', 'age':34, 'job':'it'}
info = dict ##别名 (二个字典指向内存的同一地址空间)
info1 = dict.copy() #shadow copy 浅复制(嵌套字典第一层独立,第二层以下相关联)
import copy
copy.copy() #shadow copy 浅复制
copy.deepcopy() #deep copy 深复制(完全独立)
注:浅复制下的关联只是针对字典初始状态包含的嵌套对象,后新加的不会
例:
>>> dict
{'info': ['a', 'b', 1, 2], 'job': 'it', 'sex': 'm', 'age': 40, 'name': 'wang'}
>>> dict_alias = dict
>>> dict_copy = copy.copy(dict)
>>> dict_deep = copy.deepcopy(dict)
#添加、改变、删除第一层的对象键值,浅复制和深复制都不受影响
>>> dict['age'] = 32
>>> del dict['sex']
>>> dict
{'info': ['a', 'b', 1, 2], 'job': 'it', 'age': 32, 'name': 'wang'}
>>> dict_alias
{'info': ['a', 'b', 1, 2], 'job': 'it', 'age': 32, 'name': 'wang'}
>>> dict_copy
{'info': ['a', 'b', 1, 2], 'job': 'it', 'age': 40, 'name': 'wang', 'sex': 'm'}
>>> dict_deep
{'info': ['a', 'b', 1, 2], 'job': 'it', 'age': 40, 'name': 'wang', 'sex': 'm'}
#改变、删除原有的第二层的对象键值,浅复制受影响,而深复制都不受影响
>>> dict['info'][2] = 100
>>> dict
{'info': ['a', 'b', 100, 2], 'job': 'it', 'age': 32, 'name': 'wang'}
>>> dict_alias
{'info': ['a', 'b', 100, 2], 'job': 'it', 'age': 32, 'name': 'wang'}
>>> dict_copy
{'info': ['a', 'b', 100, 2], 'job': 'it', 'age': 40, 'name': 'wang', 'sex': 'm'}
>>> dict_deep
{'info': ['a', 'b', 1, 2], 'job': 'it', 'age': 40, 'name': 'wang', 'sex': 'm'}
#添加第二层的对象,浅复制和深复制都不受影响
>>> dict['new'] = {'a':1, 'b':2, 'c':5}
>>> dict
{'info': ['a', 'b', 100, 2], 'name': 'wang', 'age': 32, 'job': 'it', 'new': {'a': 1, 'c': 5, 'b': 2}}
>>> dict_alias
{'info': ['a', 'b', 100, 2], 'name': 'wang', 'age': 32, 'job': 'it', 'new': {'a': 1, 'c': 5, 'b': 2}}
>>> dict_copy
{'info': ['a', 'b', 100, 2], 'job': 'it', 'age': 40, 'name': 'wang', 'sex': 'm'}
>>> dict_deep
{'info': ['a', 'b', 1, 2], 'job': 'it', 'age': 40, 'name': 'wang', 'sex': 'm'}
9、内置函数说明:
__name__:主文件时返回main,否则返回文件名,可用来判断是否说主文件还是导入模块;
__file__:文件的绝对路径;
__doc__:文件开头的注释说明
例:
'''
created by 2015-12-18
@author: kevin
'''
if __name__ == '__main__':
print('this is main file')
print(__file__)
print(__doc__)
http://www.cnblogs.com/wupeiqi/articles/4911365.html
1、编码转换介绍
unicode是最底层、最纯的,会根据终端的编码进行转化展示
一般硬盘存储或传输为utf-8(因为省空间、省带宽),读入内存中为unicode,二者如何转换
a = '你好' '\xe4\xbd\xa0\xe5\xa5\xbd' <type 'str'>
b = u'你好' u'\u4f60\u597d' <type 'unicode'>
a.decode('utf-8') u'\u4f60\u597d' (utf-8格式解码为unicode)
b.encode('utf-8') '\xe4\xbd\xa0\xe5\xa5\xbd' (unicode格式加密为utf-8)
注:在python2.7版本中需要如上转换,在脚本中如要显示中文,
只要在文件开头加入 # _*_ coding: UTF-8 _*_ 或者 #coding=utf-8 就行了
在python3.4以后版本,无需转换
2、字符串的常用函数format:
S.format(*args, **kwargs) -> string
Return a formatted version of S, using substitutions from args and kwargs.
The substitutions are identified by braces ('{' and '}').
name1 = "I am {0},age is {1}"
name1.format('kevin',33)
li = ['kevin',33]
name1.format(*li)
name2 = "I am {ss},age is {dd}"
name2.format(ss='kevin',dd=33)
dic = {'ss': 'kevin','dd':33}
name2.format(**dic)3、元组的元素是不能被修改,但元素的元素能可以被被修改的
>>> aa = (1,2,'a','b',['a',1,'b',2])
>>> aa
(1, 2, 'a', 'b', ['a', 1, 'b', 2])
>>> aa[-1]
['a', 1, 'b', 2]
>>> aa[-1].append('aaaa')
>>> aa
(1, 2, 'a', 'b', ['a', 1, 'b', 2, 'aaaa'])4、字典的循环
当数据量达到上百万时,循环字典就不适合用dict.items(),因为首先会把一对对key和value转化为列表,然后在循环遍历输出,会增加内存使用。建议使用如下:
>>> a = {1:'a',2:'b'}
>>> for k in aa:print(k,aa[k])
(1, 'a')
(2, 'b')
>>> for k in aa.keys():print(k,aa[k])
(1, 'a')
(2, 'b')5、调用系统命令,并存入变量:
1.import os
a = os.system('df -Th')
b = os.popen('df -Th','r') 返回一个文件对象
c = os.path.dirname(os.path.abspath(__file__)) 获取当前的目录
2.import commands
c = commands.getoutput('df -Th') 返回一个字符串
6、sys调用
import sys
sys.exit
print sys.argv
sys.path
7、导入模板方法:
1.import sys [as newname]
多次重复使用import语句时,不会重新加载被指定的模块,只是把对该模块的内存地址给引用到本地变量环境。
2.from sys import argv或(*)
3.reload()
reload会重新加载已加载的模块,但原来已经使用的实例还是会使用旧的模块,而新生产的实例会使用新的模块;reload后还是用原来的内存地址;不能支持from。。import。。格式的模块进行重新加载。
建议使用第一种,第二种导入的对象或变量会与当前的变量会冲突。
8、字典复制:
dict = {'name':'wang', 'sex':'m', 'age':34, 'job':'it'}
info = dict ##别名 (二个字典指向内存的同一地址空间)
info1 = dict.copy() #shadow copy 浅复制(嵌套字典第一层独立,第二层以下相关联)
import copy
copy.copy() #shadow copy 浅复制
copy.deepcopy() #deep copy 深复制(完全独立)
注:浅复制下的关联只是针对字典初始状态包含的嵌套对象,后新加的不会
例:
>>> dict
{'info': ['a', 'b', 1, 2], 'job': 'it', 'sex': 'm', 'age': 40, 'name': 'wang'}
>>> dict_alias = dict
>>> dict_copy = copy.copy(dict)
>>> dict_deep = copy.deepcopy(dict)
#添加、改变、删除第一层的对象键值,浅复制和深复制都不受影响
>>> dict['age'] = 32
>>> del dict['sex']
>>> dict
{'info': ['a', 'b', 1, 2], 'job': 'it', 'age': 32, 'name': 'wang'}
>>> dict_alias
{'info': ['a', 'b', 1, 2], 'job': 'it', 'age': 32, 'name': 'wang'}
>>> dict_copy
{'info': ['a', 'b', 1, 2], 'job': 'it', 'age': 40, 'name': 'wang', 'sex': 'm'}
>>> dict_deep
{'info': ['a', 'b', 1, 2], 'job': 'it', 'age': 40, 'name': 'wang', 'sex': 'm'}
#改变、删除原有的第二层的对象键值,浅复制受影响,而深复制都不受影响
>>> dict['info'][2] = 100
>>> dict
{'info': ['a', 'b', 100, 2], 'job': 'it', 'age': 32, 'name': 'wang'}
>>> dict_alias
{'info': ['a', 'b', 100, 2], 'job': 'it', 'age': 32, 'name': 'wang'}
>>> dict_copy
{'info': ['a', 'b', 100, 2], 'job': 'it', 'age': 40, 'name': 'wang', 'sex': 'm'}
>>> dict_deep
{'info': ['a', 'b', 1, 2], 'job': 'it', 'age': 40, 'name': 'wang', 'sex': 'm'}
#添加第二层的对象,浅复制和深复制都不受影响
>>> dict['new'] = {'a':1, 'b':2, 'c':5}
>>> dict
{'info': ['a', 'b', 100, 2], 'name': 'wang', 'age': 32, 'job': 'it', 'new': {'a': 1, 'c': 5, 'b': 2}}
>>> dict_alias
{'info': ['a', 'b', 100, 2], 'name': 'wang', 'age': 32, 'job': 'it', 'new': {'a': 1, 'c': 5, 'b': 2}}
>>> dict_copy
{'info': ['a', 'b', 100, 2], 'job': 'it', 'age': 40, 'name': 'wang', 'sex': 'm'}
>>> dict_deep
{'info': ['a', 'b', 1, 2], 'job': 'it', 'age': 40, 'name': 'wang', 'sex': 'm'}
9、内置函数说明:
__name__:主文件时返回main,否则返回文件名,可用来判断是否说主文件还是导入模块;
__file__:文件的绝对路径;
__doc__:文件开头的注释说明
例:
'''
created by 2015-12-18
@author: kevin
'''
if __name__ == '__main__':
print('this is main file')
print(__file__)
print(__doc__)

相关文章推荐
- 最短路径算法—Floyd(弗洛伊德)算法分析与实现(Python)
- python
- python基础学习笔记1
- python基础知识---抽象--函数
- python中的列表的复制
- python编写的维吉尼亚密码加解密程序
- python 开发工具搭建
- LeetCode 3Sum Closest
- 5.2 calendar--通用日期的相关函数(4)
- python 正则表达式精华 re.match与re.search的区别
- 《利用python进行数据分析》读书笔记--第十章 时间序列(三)
- Python基本数据类型之int 、 float
- mac-os MySQL_python-1.2.4b4
- python 安装PIL
- python 中的list 定位下标可以用负数
- leetcode Valid Sudoku python
- python运算符使用规律
- python基础
- python基础
- Python连接Mysql