独立成分分析(Independent Component Analysis)
2015-12-15 17:15
274 查看
http://blog.csdn.net/ffeng271/article/details/7353881
1. 问题:
1、上节提到的PCA是一种数据降维的方法,但是只对符合高斯分布的样本点比较有效,那么对于其他分布的样本,有没有主元分解的方法呢?
2、经典的鸡尾酒宴会问题(cocktail party problem)。假设在party中有n个人,他们可以同时说话,我们也在房间中一些角落里共放置了n个声音接收器(Microphone)用来记录声音。宴会过后,我们从n个麦克风中得到了一组数据
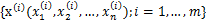
,i表示采样的时间顺序,也就是说共得到了m组采样,每一组采样都是n维的。我们的目标是单单从这m组采样数据中分辨出每个人说话的信号。
将第二个问题细化一下,有n个信号源
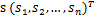
,
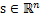
,每一维都是一个人的声音信号,每个人发出的声音信号独立。A是一个未知的混合矩阵(mixing
matrix),用来组合叠加信号s,那么
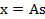
x的意义在上文解释过,这里的x不是一个向量,是一个矩阵。其中每个列向量是
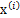
,
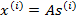
表示成图就是
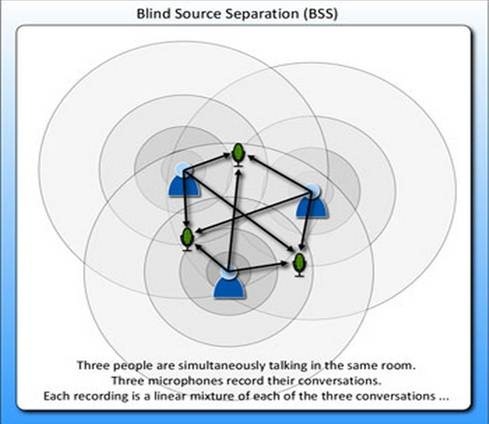
这张图来自
http://amouraux.webnode.com/research-interests/research-interests-erp-analysis/blind-source-separation-bss-of-erps-using-independent-component-analysis-ica/
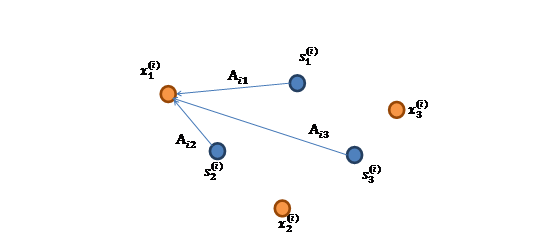
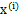
的每个分量都由
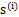
的分量线性表示。A和s都是未知的,x是已知的,我们要想办法根据x来推出s。这个过程也称作为盲信号分离。
令
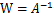
,那么
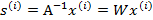
将W表示成
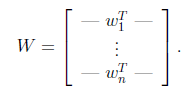
其中
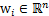
,其实就是将
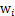
写成行向量形式。那么得到:
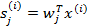
2. ICA的不确定性(ICA ambiguities)
由于w和s都不确定,那么在没有先验知识的情况下,无法同时确定这两个相关参数。比如上面的公式s=wx。当w扩大两倍时,s只需要同时扩大两倍即可,等式仍然满足,因此无法得到唯一的s。同时如果将人的编号打乱,变成另外一个顺序,如上图的蓝色节点的编号变为3,2,1,那么只需要调换A的列向量顺序即可,因此也无法单独确定s。这两种情况称为原信号不确定。
还有一种ICA不适用的情况,那就是信号不能是高斯分布的。假设只有两个人发出的声音信号符合多值正态分布,
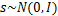
,I是2*2的单位矩阵,s的概率密度函数就不用说了吧,以均值0为中心,投影面是椭圆的山峰状(参见多值高斯分布)。因为
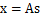
,因此,x也是高斯分布的,均值为0,协方差为
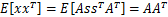
。
令R是正交阵
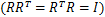
,
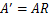
。如果将A替换成A’。那么
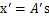
。s分布没变,因此x’仍然是均值为0,协方差
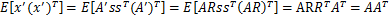
。
因此,不管混合矩阵是A还是A’,x的分布情况是一样的,那么就无法确定混合矩阵,也就无法确定原信号。
3. 密度函数和线性变换
在讨论ICA具体算法之前,我们先来回顾一下概率和线性代数里的知识。
假设我们的随机变量s有概率密度函数
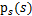
(连续值是概率密度函数,离散值是概率)。为了简单,我们再假设s是实数,还有一个随机变量x=As,A和x都是实数。令
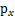
是x的概率密度,那么怎么求
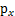
?
令
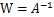
,首先将式子变换成
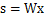
,然后得到
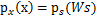
,求解完毕。可惜这种方法是错误的。比如s符合均匀分布的话(
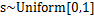
),那么s的概率密度是
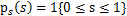
,现在令A=2,即x=2s,也就是说x在[0,2]上均匀分布,可知
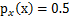
。然而,前面的推导会得到
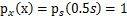
。正确的公式应该是
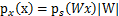
推导方法
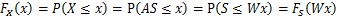
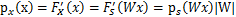
更一般地,如果s是向量,A可逆的方阵,那么上式子仍然成立。
4. ICA算法
ICA算法归功于Bell和Sejnowski,这里使用最大似然估计来解释算法,原始的论文中使用的是一个复杂的方法Infomax principal。
我们假定每个
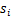
有概率密度
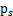
,那么给定时刻原信号的联合分布就是
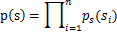
这个公式代表一个假设前提:每个人发出的声音信号各自独立。有了p(s),我们可以求得p(x)
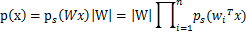
左边是每个采样信号x(n维向量)的概率,右边是每个原信号概率的乘积的|W|倍。
前面提到过,如果没有先验知识,我们无法求得W和s。因此我们需要知道
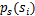
,我们打算选取一个概率密度函数赋给s,但是我们不能选取高斯分布的密度函数。在概率论里我们知道密度函数p(x)由累计分布函数(cdf)F(x)求导得到。F(x)要满足两个性质是:单调递增和在[0,1]。我们发现sigmoid函数很适合,定义域负无穷到正无穷,值域0到1,缓慢递增。我们假定s的累积分布函数符合sigmoid函数
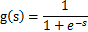
求导后
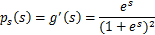
这就是s的密度函数。这里s是实数。
如果我们预先知道s的分布函数,那就不用假设了,但是在缺失的情况下,sigmoid函数能够在大多数问题上取得不错的效果。由于上式中
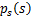
是个对称函数,因此E[s]=0(s的均值为0),那么E[x]=E[As]=0,x的均值也是0。
知道了
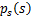
,就剩下W了。给定采样后的训练样本
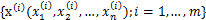
,样本对数似然估计如下:
使用前面得到的x的概率密度函数,得
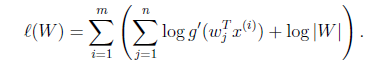
大括号里面是
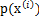
。
接下来就是对W求导了,这里牵涉一个问题是对行列式|W|进行求导的方法,属于矩阵微积分。这里先给出结果,在文章最后再给出推导公式。
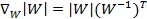
最终得到的求导后公式如下,
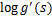
的导数为
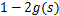
(可以自己验证):
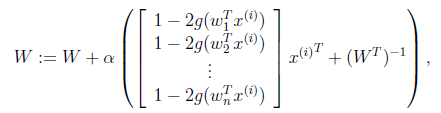
其中
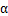
是梯度上升速率,人为指定。
当迭代求出W后,便可得到
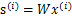
来还原出原始信号。
注意:我们计算最大似然估计时,假设了
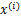
与
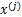
之间是独立的,然而对于语音信号或者其他具有时间连续依赖特性(比如温度)上,这个假设不能成立。但是在数据足够多时,假设独立对效果影响不大,同时如果事先打乱样例,并运行随机梯度上升算法,那么能够加快收敛速度。
回顾一下鸡尾酒宴会问题,s是人发出的信号,是连续值,不同时间点的s不同,每个人发出的信号之间独立(
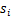
和
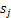
之间独立)。s的累计概率分布函数是sigmoid函数,但是所有人发出声音信号都符合这个分布。A(W的逆阵)代表了s相对于x的位置变化,x是s和A变化后的结果。
5. 实例
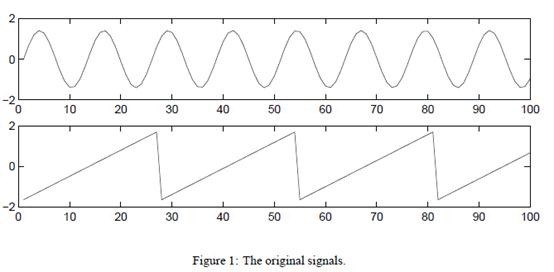
s=2时的原始信号
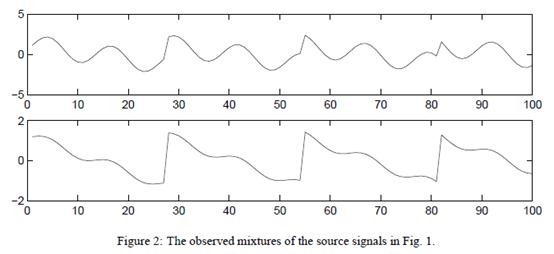
观察到的x信号
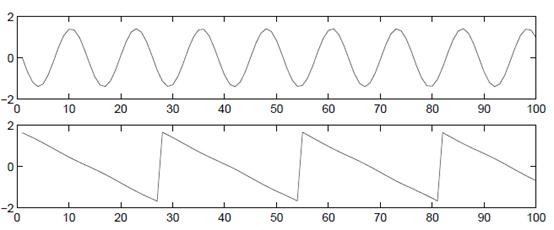
使用ICA还原后的s信号
6. 行列式的梯度
对行列式求导,设矩阵A是n×n的,我们知道行列式与代数余子式有关,
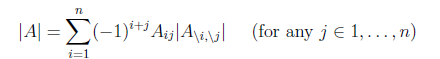
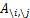
是去掉第i行第j列后的余子式,那么对
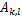
求导得
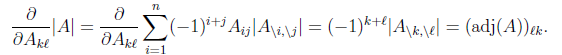
adj(A)跟我们线性代数中学的
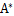
是一个意思,因此
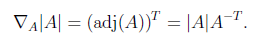
7. ICA算法扩展描述
上面介绍的内容基本上是讲义上的,与我看的另一篇《Independent Component Analysis:
Algorithms and Applications》(Aapo Hyvärinen and Erkki Oja)有点出入。下面总结一下这篇文章里提到的一些内容(有些我也没看明白)。
首先里面提到了一个与“独立”相似的概念“不相关(uncorrelated)”。Uncorrelated属于部分独立,而不是完全独立,怎么刻画呢?
如果随机变量
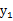
和
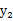
是独立的,当且仅当
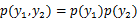
。
如果随机变量
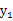
和
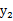
是不相关的,当且仅当
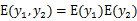
第二个不相关的条件要比第一个独立的条件“松”一些。因为独立能推出不相关,不相关推不出独立。
证明如下:

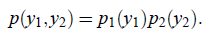
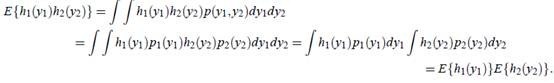
反过来不能推出。
比如,
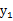
和
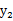
的联合分布如下(0,1),(0,-1),(1,0),(-1,0)。
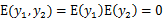
因此
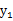
和
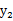
不相关,但是
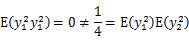
因此
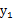
和
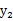
不满足上面的积分公式,
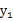
和
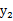
不是独立的。
上面提到过,如果
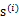
是高斯分布的,A是正交的,那么
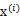
也是高斯分布的,且
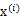
与
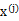
之间是独立的。那么无法确定A,因为任何正交变换都可以让
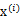
达到同分布的效果。但是如果
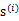
中只有一个分量是高斯分布的,仍然可以使用ICA。
那么ICA要解决的问题变为:如何从x中推出s,使得s最不可能满足高斯分布?
中心极限定理告诉我们:大量独立同分布随机变量之和满足高斯分布。
我们一直假设的是
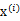
是由独立同分布的主元
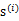
经过混合矩阵A生成。那么为了求
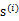
,我们需要计算
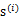
的每个分量
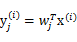
。定义
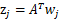
,那么
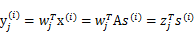
,之所以这么麻烦再定义z是想说明一个关系,我们想通过整出一个
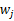
来对
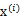
进行线性组合,得出y。而我们不知道得出的y是否是真正的s的分量,但我们知道y是s的真正分量的线性组合。由于我们不能使s的分量成为高斯分布,因此我们的目标求是让y(也就是
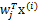
)最不可能是高斯分布时的w。
那么问题递归到如何度量y是否是高斯分布的了。
一种度量方法是kurtosis方法,公式如下:
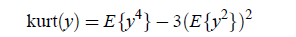
如果y是高斯分布,那么该函数值为0,否则绝大多数情况下值不为0。
但这种度量方法不怎么好,有很多问题。看下一种方法:
负熵(Negentropy)度量方法。
我们在信息论里面知道对于离散的随机变量Y,其熵是
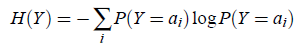
连续值时是
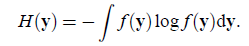
在信息论里有一个强有力的结论是:高斯分布的随机变量是同方差分布中熵最大的。也就是说对于一个随机变量来说,满足高斯分布时,最随机。
定义负熵的计算公式如下:
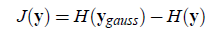
也就是随机变量y相对于高斯分布时的熵差,这个公式的问题就是直接计算时较为复杂,一般采用逼近策略。
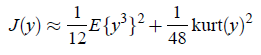
这种逼近策略不够好,作者提出了基于最大熵的更优的公式:
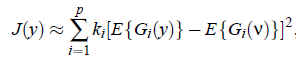
之后的FastICA就基于这个公式。
另外一种度量方法是最小互信息方法:
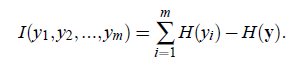
这个公式可以这样解释,前一个H是
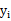
的编码长度(以信息编码的方式理解),第二个H是y成为随机变量时的平均编码长度。之后的内容包括FastICA就不再介绍了,我也没看懂。
8. ICA的投影追踪解释(Projection Pursuit)
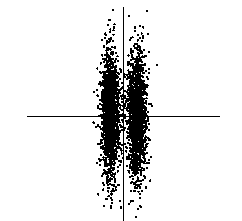
投影追踪在统计学中的意思是去寻找多维数据的“interesting”投影。这些投影可用在数据可视化、密度估计和回归中。比如在一维的投影追踪中,我们寻找一条直线,使得所有的数据点投影到直线上后,能够反映出数据的分布。然而我们最不想要的是高斯分布,最不像高斯分布的数据点最interesting。这个与我们的ICA思想是一直的,寻找独立的最不可能是高斯分布的s。
在下图中,主元是纵轴,拥有最大的方差,但最interesting的是横轴,因为它可以将两个类分开(信号分离)。
9. ICA算法的前处理步骤
1、中心化:也就是求x均值,然后让所有x减去均值,这一步与PCA一致。
2、漂白:目的是将x乘以一个矩阵变成
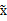
,使得
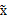
的协方差矩阵是
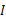
。解释一下吧,原始的向量是x。转换后的是
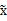
。
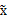
的协方差矩阵是
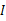
,即
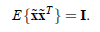
我们只需用下面的变换,就可以从x得到想要的
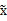
。
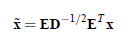
其中使用特征值分解来得到E(特征向量矩阵)和D(特征值对角矩阵),计算公式为
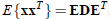
下面用个图来直观描述一下:
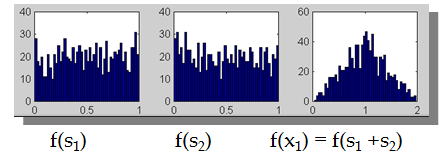
假设信号源s1和s2是独立的,比如下图横轴是s1,纵轴是s2,根据s1得不到s2。

我们只知道他们合成后的信号x,如下
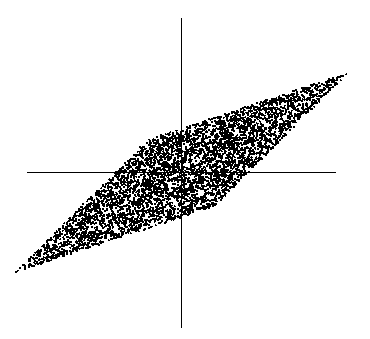
此时x1和x2不是独立的(比如看最上面的尖角,知道了x1就知道了x2)。那么直接代入我们之前的极大似然概率估计会有问题,因为我们假定x是独立的。
因此,漂白这一步为了让x独立。漂白结果如下:
可以看到数据变成了方阵,在
的维度上已经达到了独立。
然而这时x分布很好的情况下能够这样转换,当有噪音时怎么办呢?可以先使用前面提到的PCA方法来对数据进行降维,滤去噪声信号,得到k维的正交向量,然后再使用ICA。
10. 小结
ICA的盲信号分析领域的一个强有力方法,也是求非高斯分布数据隐含因子的方法。从之前我们熟悉的样本-特征角度看,我们使用ICA的前提条件是,认为样本数据由独立非高斯分布的隐含因子产生,隐含因子个数等于特征数,我们要求的是隐含因子。
而PCA认为特征是由k个正交的特征(也可看作是隐含因子)生成的,我们要求的是数据在新特征上的投影。同是因子分析,一个用来更适合用来还原信号(因为信号比较有规律,经常不是高斯分布的),一个更适合用来降维(用那么多特征干嘛,k个正交的即可)。有时候也需要组合两者一起使用。这段是我的个人理解,仅供参考。
/content/4665907.html
独立成分分析(Independent Component Analysis)
1. 问题:1、上节提到的PCA是一种数据降维的方法,但是只对符合高斯分布的样本点比较有效,那么对于其他分布的样本,有没有主元分解的方法呢?
2、经典的鸡尾酒宴会问题(cocktail party problem)。假设在party中有n个人,他们可以同时说话,我们也在房间中一些角落里共放置了n个声音接收器(Microphone)用来记录声音。宴会过后,我们从n个麦克风中得到了一组数据
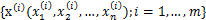
,i表示采样的时间顺序,也就是说共得到了m组采样,每一组采样都是n维的。我们的目标是单单从这m组采样数据中分辨出每个人说话的信号。
将第二个问题细化一下,有n个信号源
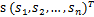
,
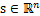
,每一维都是一个人的声音信号,每个人发出的声音信号独立。A是一个未知的混合矩阵(mixing
matrix),用来组合叠加信号s,那么
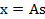
x的意义在上文解释过,这里的x不是一个向量,是一个矩阵。其中每个列向量是
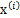
,
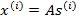
表示成图就是

这张图来自
http://amouraux.webnode.com/research-interests/research-interests-erp-analysis/blind-source-separation-bss-of-erps-using-independent-component-analysis-ica/


的每个分量都由
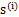
的分量线性表示。A和s都是未知的,x是已知的,我们要想办法根据x来推出s。这个过程也称作为盲信号分离。
令
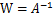
,那么
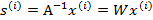
将W表示成
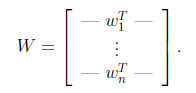
其中

,其实就是将
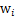
写成行向量形式。那么得到:
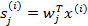
2. ICA的不确定性(ICA ambiguities)
由于w和s都不确定,那么在没有先验知识的情况下,无法同时确定这两个相关参数。比如上面的公式s=wx。当w扩大两倍时,s只需要同时扩大两倍即可,等式仍然满足,因此无法得到唯一的s。同时如果将人的编号打乱,变成另外一个顺序,如上图的蓝色节点的编号变为3,2,1,那么只需要调换A的列向量顺序即可,因此也无法单独确定s。这两种情况称为原信号不确定。
还有一种ICA不适用的情况,那就是信号不能是高斯分布的。假设只有两个人发出的声音信号符合多值正态分布,

,I是2*2的单位矩阵,s的概率密度函数就不用说了吧,以均值0为中心,投影面是椭圆的山峰状(参见多值高斯分布)。因为

,因此,x也是高斯分布的,均值为0,协方差为
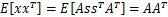
。
令R是正交阵

,
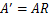
。如果将A替换成A’。那么

。s分布没变,因此x’仍然是均值为0,协方差
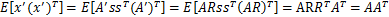
。
因此,不管混合矩阵是A还是A’,x的分布情况是一样的,那么就无法确定混合矩阵,也就无法确定原信号。
3. 密度函数和线性变换
在讨论ICA具体算法之前,我们先来回顾一下概率和线性代数里的知识。
假设我们的随机变量s有概率密度函数

(连续值是概率密度函数,离散值是概率)。为了简单,我们再假设s是实数,还有一个随机变量x=As,A和x都是实数。令
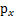
是x的概率密度,那么怎么求
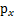
?
令
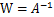
,首先将式子变换成
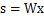
,然后得到
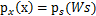
,求解完毕。可惜这种方法是错误的。比如s符合均匀分布的话(

),那么s的概率密度是
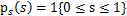
,现在令A=2,即x=2s,也就是说x在[0,2]上均匀分布,可知
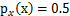
。然而,前面的推导会得到
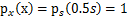
。正确的公式应该是

推导方法
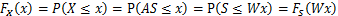

更一般地,如果s是向量,A可逆的方阵,那么上式子仍然成立。
4. ICA算法
ICA算法归功于Bell和Sejnowski,这里使用最大似然估计来解释算法,原始的论文中使用的是一个复杂的方法Infomax principal。
我们假定每个

有概率密度
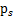
,那么给定时刻原信号的联合分布就是
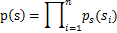
这个公式代表一个假设前提:每个人发出的声音信号各自独立。有了p(s),我们可以求得p(x)
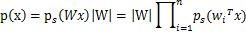
左边是每个采样信号x(n维向量)的概率,右边是每个原信号概率的乘积的|W|倍。
前面提到过,如果没有先验知识,我们无法求得W和s。因此我们需要知道
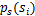
,我们打算选取一个概率密度函数赋给s,但是我们不能选取高斯分布的密度函数。在概率论里我们知道密度函数p(x)由累计分布函数(cdf)F(x)求导得到。F(x)要满足两个性质是:单调递增和在[0,1]。我们发现sigmoid函数很适合,定义域负无穷到正无穷,值域0到1,缓慢递增。我们假定s的累积分布函数符合sigmoid函数

求导后

这就是s的密度函数。这里s是实数。
如果我们预先知道s的分布函数,那就不用假设了,但是在缺失的情况下,sigmoid函数能够在大多数问题上取得不错的效果。由于上式中
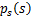
是个对称函数,因此E[s]=0(s的均值为0),那么E[x]=E[As]=0,x的均值也是0。
知道了
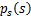
,就剩下W了。给定采样后的训练样本
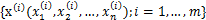
,样本对数似然估计如下:
使用前面得到的x的概率密度函数,得
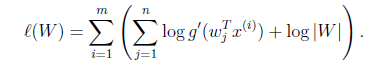
大括号里面是

。
接下来就是对W求导了,这里牵涉一个问题是对行列式|W|进行求导的方法,属于矩阵微积分。这里先给出结果,在文章最后再给出推导公式。

最终得到的求导后公式如下,

的导数为
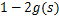
(可以自己验证):

其中
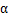
是梯度上升速率,人为指定。
当迭代求出W后,便可得到

来还原出原始信号。
注意:我们计算最大似然估计时,假设了
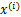
与
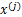
之间是独立的,然而对于语音信号或者其他具有时间连续依赖特性(比如温度)上,这个假设不能成立。但是在数据足够多时,假设独立对效果影响不大,同时如果事先打乱样例,并运行随机梯度上升算法,那么能够加快收敛速度。
回顾一下鸡尾酒宴会问题,s是人发出的信号,是连续值,不同时间点的s不同,每个人发出的信号之间独立(
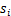
和

之间独立)。s的累计概率分布函数是sigmoid函数,但是所有人发出声音信号都符合这个分布。A(W的逆阵)代表了s相对于x的位置变化,x是s和A变化后的结果。
5. 实例

s=2时的原始信号
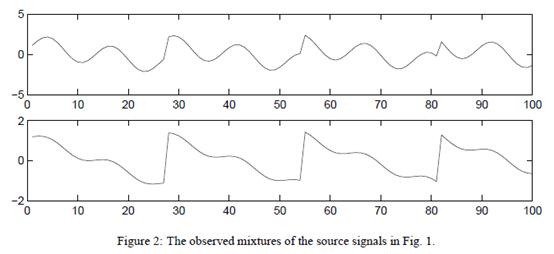
观察到的x信号

使用ICA还原后的s信号
6. 行列式的梯度
对行列式求导,设矩阵A是n×n的,我们知道行列式与代数余子式有关,

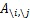
是去掉第i行第j列后的余子式,那么对

求导得
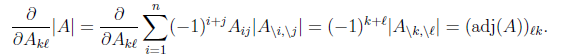
adj(A)跟我们线性代数中学的
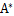
是一个意思,因此
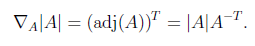
7. ICA算法扩展描述
上面介绍的内容基本上是讲义上的,与我看的另一篇《Independent Component Analysis:
Algorithms and Applications》(Aapo Hyvärinen and Erkki Oja)有点出入。下面总结一下这篇文章里提到的一些内容(有些我也没看明白)。
首先里面提到了一个与“独立”相似的概念“不相关(uncorrelated)”。Uncorrelated属于部分独立,而不是完全独立,怎么刻画呢?
如果随机变量
和

是独立的,当且仅当

。
如果随机变量
和
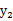
是不相关的,当且仅当

第二个不相关的条件要比第一个独立的条件“松”一些。因为独立能推出不相关,不相关推不出独立。
证明如下:
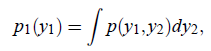
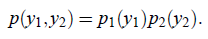
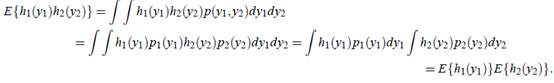
反过来不能推出。
比如,

和
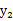
的联合分布如下(0,1),(0,-1),(1,0),(-1,0)。
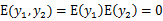
因此
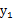
和
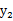
不相关,但是
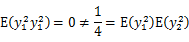
因此
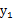
和

不满足上面的积分公式,

和

不是独立的。
上面提到过,如果
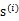
是高斯分布的,A是正交的,那么

也是高斯分布的,且
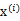
与
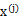
之间是独立的。那么无法确定A,因为任何正交变换都可以让
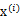
达到同分布的效果。但是如果
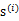
中只有一个分量是高斯分布的,仍然可以使用ICA。
那么ICA要解决的问题变为:如何从x中推出s,使得s最不可能满足高斯分布?
中心极限定理告诉我们:大量独立同分布随机变量之和满足高斯分布。
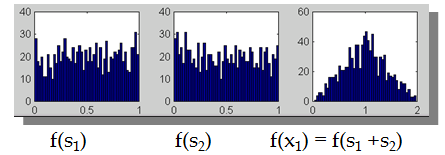
我们一直假设的是
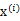
是由独立同分布的主元
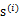
经过混合矩阵A生成。那么为了求

,我们需要计算
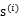
的每个分量
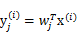
。定义
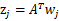
,那么

,之所以这么麻烦再定义z是想说明一个关系,我们想通过整出一个
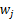
来对
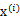
进行线性组合,得出y。而我们不知道得出的y是否是真正的s的分量,但我们知道y是s的真正分量的线性组合。由于我们不能使s的分量成为高斯分布,因此我们的目标求是让y(也就是
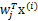
)最不可能是高斯分布时的w。
那么问题递归到如何度量y是否是高斯分布的了。
一种度量方法是kurtosis方法,公式如下:
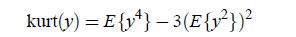
如果y是高斯分布,那么该函数值为0,否则绝大多数情况下值不为0。
但这种度量方法不怎么好,有很多问题。看下一种方法:
负熵(Negentropy)度量方法。
我们在信息论里面知道对于离散的随机变量Y,其熵是
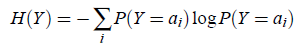
连续值时是
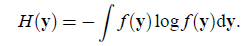
在信息论里有一个强有力的结论是:高斯分布的随机变量是同方差分布中熵最大的。也就是说对于一个随机变量来说,满足高斯分布时,最随机。
定义负熵的计算公式如下:
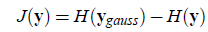
也就是随机变量y相对于高斯分布时的熵差,这个公式的问题就是直接计算时较为复杂,一般采用逼近策略。

这种逼近策略不够好,作者提出了基于最大熵的更优的公式:
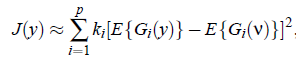
之后的FastICA就基于这个公式。
另外一种度量方法是最小互信息方法:
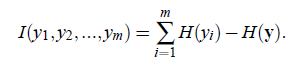
这个公式可以这样解释,前一个H是
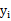
的编码长度(以信息编码的方式理解),第二个H是y成为随机变量时的平均编码长度。之后的内容包括FastICA就不再介绍了,我也没看懂。
8. ICA的投影追踪解释(Projection Pursuit)
投影追踪在统计学中的意思是去寻找多维数据的“interesting”投影。这些投影可用在数据可视化、密度估计和回归中。比如在一维的投影追踪中,我们寻找一条直线,使得所有的数据点投影到直线上后,能够反映出数据的分布。然而我们最不想要的是高斯分布,最不像高斯分布的数据点最interesting。这个与我们的ICA思想是一直的,寻找独立的最不可能是高斯分布的s。
在下图中,主元是纵轴,拥有最大的方差,但最interesting的是横轴,因为它可以将两个类分开(信号分离)。

9. ICA算法的前处理步骤
1、中心化:也就是求x均值,然后让所有x减去均值,这一步与PCA一致。
2、漂白:目的是将x乘以一个矩阵变成
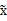
,使得
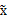
的协方差矩阵是
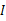
。解释一下吧,原始的向量是x。转换后的是

。

的协方差矩阵是
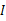
,即
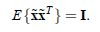
我们只需用下面的变换,就可以从x得到想要的
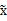
。
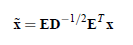
其中使用特征值分解来得到E(特征向量矩阵)和D(特征值对角矩阵),计算公式为
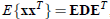
下面用个图来直观描述一下:
假设信号源s1和s2是独立的,比如下图横轴是s1,纵轴是s2,根据s1得不到s2。

我们只知道他们合成后的信号x,如下

此时x1和x2不是独立的(比如看最上面的尖角,知道了x1就知道了x2)。那么直接代入我们之前的极大似然概率估计会有问题,因为我们假定x是独立的。
因此,漂白这一步为了让x独立。漂白结果如下:

可以看到数据变成了方阵,在

的维度上已经达到了独立。
然而这时x分布很好的情况下能够这样转换,当有噪音时怎么办呢?可以先使用前面提到的PCA方法来对数据进行降维,滤去噪声信号,得到k维的正交向量,然后再使用ICA。
10. 小结
ICA的盲信号分析领域的一个强有力方法,也是求非高斯分布数据隐含因子的方法。从之前我们熟悉的样本-特征角度看,我们使用ICA的前提条件是,认为样本数据由独立非高斯分布的隐含因子产生,隐含因子个数等于特征数,我们要求的是隐含因子。
而PCA认为特征是由k个正交的特征(也可看作是隐含因子)生成的,我们要求的是数据在新特征上的投影。同是因子分析,一个用来更适合用来还原信号(因为信号比较有规律,经常不是高斯分布的),一个更适合用来降维(用那么多特征干嘛,k个正交的即可)。有时候也需要组合两者一起使用。这段是我的个人理解,仅供参考。
/content/4665907.html

相关文章推荐
- 有效的用例编写规则
- PTAM调试 win7+VS2010
- 如何在Windows版的ScaleIO的节点中添加磁盘
- 在cmd命令行中弹出Windows对话框
- C++工程编译之“error LNK2001: 无法解析的外部符号”
- window.name跨域实现
- SWFUpload文件上传详解
- js提交表单kindeditor编辑器textarea为空解决办法
- 老李分享:shell 监控cpu,memory,load average 2
- Ansible :一个配置管理和IT自动化工具
- 关于分布式事务、两阶段提交、一阶段提交、Best Efforts 1PC模式和事务补偿机制的研究
- Android多线程之AsyncTask
- Qt中常用快捷键
- UVA-10806 Dijkstra, Dijkstra. (最小费用流,网络流建模)
- spark读写Sequoiadb
- Facebook SDK集成之纲要篇
- 藏在優酪乳裏的純白時光
- MySQL Sending data导致查询很慢的问题详细分析
- ios NSString 与 char[] 互转--char数组
- android KitKat Translucent 4.4版本支持消息栏半透明