sense2vec - a fast and accurate method for word sense disambiguation in neural word embeddings.
2015-12-14 15:35
453 查看
Despite these advancements, most word embedding techniques share a common problem in that each word must encode all of its potential meanings into a single vector.
This technique is inspired by the work of Huang et al. (2012), which uses a multi-prototype neural vector-space model that clusters contexts to generate prototypes. Given a pre-trained word embedding model, each context embedding is generated by computing a weighted sum of the words in the context (weighted by tf-idf). Then, for each term, the associated context embeddings are clustered. The clusters are used to re-label each occurrence of each word in the corpus. Once these terms have been re-labeled with the cluster’s number, a new word model is trained on the labeled embeddings (with a different vector for each) generating the word-sense embeddings.
We expand on the work of Huang et al. (2012) by leveraging supervised NLP labels instead of unsupervised clusters to determine a particular word nstance’s sense. This eliminates the need to train embeddings multiple times, eliminates the need for a clustering step, and creates an efficient method by which a supervised classifier may consume the appropriate word-sense embedding.
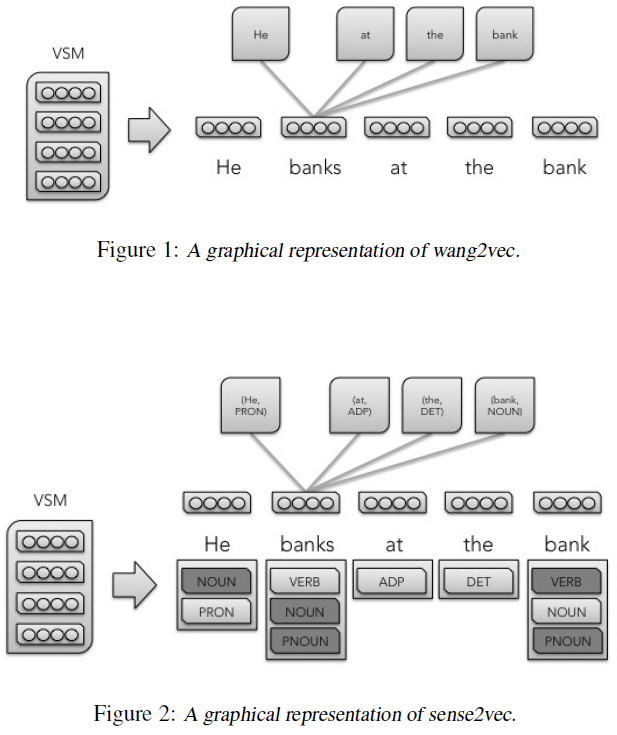
Given a labeled corpus (either by hand or by a model) with one or more labels per word, the sense2vec model first counts the number of uses (where a unique word maps set of one or more labels/uses) of each word and generates a random ”sense embedding” for each use. A model is then trained using either the CBOW, Skip-gram, or Structured Skip-gram model onfigurations. Instead of predicting a token given surrounding tokens, this model predicts a word sense given surrounding senses.
This technique is inspired by the work of Huang et al. (2012), which uses a multi-prototype neural vector-space model that clusters contexts to generate prototypes. Given a pre-trained word embedding model, each context embedding is generated by computing a weighted sum of the words in the context (weighted by tf-idf). Then, for each term, the associated context embeddings are clustered. The clusters are used to re-label each occurrence of each word in the corpus. Once these terms have been re-labeled with the cluster’s number, a new word model is trained on the labeled embeddings (with a different vector for each) generating the word-sense embeddings.
We expand on the work of Huang et al. (2012) by leveraging supervised NLP labels instead of unsupervised clusters to determine a particular word nstance’s sense. This eliminates the need to train embeddings multiple times, eliminates the need for a clustering step, and creates an efficient method by which a supervised classifier may consume the appropriate word-sense embedding.
Given a labeled corpus (either by hand or by a model) with one or more labels per word, the sense2vec model first counts the number of uses (where a unique word maps set of one or more labels/uses) of each word and generates a random ”sense embedding” for each use. A model is then trained using either the CBOW, Skip-gram, or Structured Skip-gram model onfigurations. Instead of predicting a token given surrounding tokens, this model predicts a word sense given surrounding senses.

相关文章推荐
- End-To-End Memory Networks
- word2vec
- Python适合大数据量的处理吗?
- angular debounce throttle
- 浏览器解析json数据
- EL表达式简介
- PHP 页面编码声明方法详解(header或meta)
- css3隔行变换色实现示例
- 如何调用别人提供的接口
- 参数编码规范
- 51、组播Multicast简介
- Retrofit+RxJava+lambda使用示例
- (转)java序列化时候序列ID作用(结合实际场景)
- js通过classname来获取元素
- 2015科技公司收购大盘点
- 自己的笔记___摘自别人(Android数据库中查找一条数据 query方法详解)
- 常见40个常用的js页面效果图
- 自动注入注解
- window.navigate 与 window.location.href 的使用区别介绍
- 上传文件大小限制