Canopy聚类算法与Mahout中的实现
2015-12-09 16:14
531 查看
前面提到的kmeans 算法需要提前设定簇的个数,我们也可以根据数据进行简单簇数目估计,但是有一类称为近似聚类算法技术可以根据给定数据集估计簇的数量以及近似的中心位置,其中有一个典型算法就是canopy生成算法。
Mahout中kmeans 算法实现使用RandomSeedGenerator类生成包含k个向量的SequenceFile。尽管随机中心生成速度很快,但是无法保证为k个簇估计出好的中心。中心估计极大的影响着kmeans算法的执行时间。好的估计有助于算法更快的收敛,对数据遍历次数会更少。
canopy生成算法称为canopy聚类,是一种快速近似的聚类技术。它将输入数据点划分为一些重叠簇,称为canopy。在上下文中canopy指一组相近的点,或一个簇。canopy聚类基于两个距离阈值试图估计出可能的簇中心(或canopy中心)。
canopy聚类优势在于它得到簇的速度非常快,只需遍历一次数据即可获得结果。这个优势也是它的弱点。该算法无法给出精准的簇结果。但是它可以给出最优的簇数量,不需要像kmeans预先指定簇数量k。
算法流程:使用一个快速的距离测度两个距离阈值(T1和T2,其中T1>T2。它从一个包含一些点数据集和空的canopy列表开始,然后迭代这些数据,并在迭代过程中生成canopy。在每一轮迭代中,它从数据集中移除一个点并将一个以该点为中心的canopy加入列表。然后遍历数据集中剩下的数据点。对每一个点,它会计算其到列表中每个canopy的中心距离。如果距离均小于T1,则将该点加入该canopy。如果距离小于T2,则将其移除数据集,以免接下来的循环中用它建立新的canopy。重复上述过程直到数据集为空)
这种方法防止了紧邻一个现有canopy的点(距离小于T2)称为新的canopy中心。
网上抓了一个算法流程图:
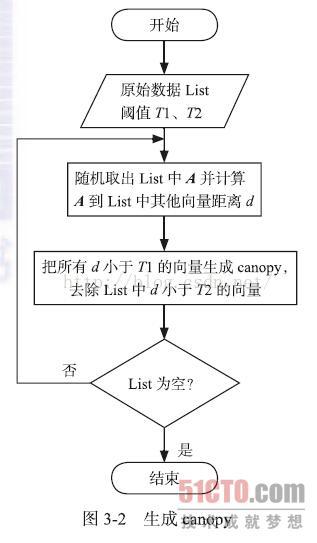
canopy算法在Mahout中通过CanopyClusterer或CanopyDriver 类来实现,前者是基于in-memory算法进行聚类,后者是基于mapreduce 方法进行算法实现。这些实现既可以读写磁盘上的数据,也可以运行在hadoop集群上读写HDFS的数据。
首先定义了一个描述canopy的类。
package org.apache.mahout.clustering.canopy;
import org.apache.mahout.clustering.iterator.DistanceMeasureCluster;
import org.apache.mahout.common.distance.DistanceMeasure;
import org.apache.mahout.math.Vector;
/**
* This class models a canopy as a center point, the number of points that are contained within it according
* to the application of some distance metric, and a point total which is the sum of all the points and is
* used to compute the centroid when needed.
*/
public class Canopy extends DistanceMeasureCluster {
/** Used for deserialization as a writable */
public Canopy() { }
/**
* Create a new Canopy containing the given point and canopyId
*
* @param center a point in vector space
* @param canopyId an int identifying the canopy local to this process only
* @param measure a DistanceMeasure to use
*/
public Canopy(Vector center, int canopyId, DistanceMeasure measure) {
super(center, canopyId, measure);
observe(center);
}
public String asFormatString() {
return "C" + this.getId() + ": " + this.computeCentroid().asFormatString();
}
@Override
public String toString() {
return getIdentifier() + ": " + getCenter().asFormatString();
}
@Override
public String getIdentifier() {
return "C-" + getId();
}
}
CanopyClusterer中算法核心部分的实现
/**
* Iterate through the points, adding new canopies. Return the canopies.
*
* @param points
* a list<Vector> defining the points to be clustered
* @param measure
* a DistanceMeasure to use
* @param t1
* the T1 distance threshold
* @param t2
* the T2 distance threshold
* @return the List<Canopy> created
*/
public static List<Canopy> createCanopies(List<Vector> points,
DistanceMeasure measure,
double t1,
double t2) {
List<Canopy> canopies = Lists.newArrayList();
/**
* Reference Implementation: Given a distance metric, one can create
* canopies as follows: Start with a list of the data points in any
* order, and with two distance thresholds, T1 and T2, where T1 > T2.
* (These thresholds can be set by the user, or selected by
* cross-validation.) Pick a point on the list and measure its distance
* to all other points. Put all points that are within distance
* threshold T1 into a canopy. Remove from the list all points that are
* within distance threshold T2. Repeat until the list is empty.
*/
int nextCanopyId = 0;
while (!points.isEmpty()) {
Iterator<Vector> ptIter = points.iterator();
Vector p1 = ptIter.next();
ptIter.remove();
Canopy canopy = new Canopy(p1, nextCanopyId++, measure);
canopies.add(canopy);
while (ptIter.hasNext()) {
Vector p2 = ptIter.next();
double dist = measure.distance(p1, p2);
// Put all points that are within distance threshold T1 into the
// canopy
if (dist < t1) {
canopy.observe(p2);
}
// Remove from the list all points that are within distance
// threshold T2
if (dist < t2) {
ptIter.remove();
}
}
for (Canopy c : canopies) {
c.computeParameters();
}
}
return canopies;
}
代码中发现最关键就是canopy两个操作:observe和computerParameters方法。
canopy类前面知道 通过多层extend 自Model接口,该接口如下:
package org.apache.mahout.clustering;
import org.apache.hadoop.io.Writable;
import org.apache.mahout.math.VectorWritable;
/**
* A model is a probability distribution over observed data points and allows
* the probability of any data point to be computed. All Models have a
* persistent representation and extend
* WritablesampleFromPosterior(Model<VectorWritable>[])
*/
public interface Model<O> extends Writable {
/**
* Return the probability that the observation is described by this model
*
* @param x
* an Observation from the posterior
* @return the probability that x is in the receiver
*/
double pdf(O x);
/**
* Observe the given observation, retaining information about it
*
* @param x
* an Observation from the posterior
*/
void observe(O x);
/**
* Observe the given observation, retaining information about it
*
* @param x
* an Observation from the posterior
* @param weight
* a double weighting factor
*/
void observe(O x, double weight);
/**
* Observe the given model, retaining information about its observations
*
* @param x
* a Model<0>
*/
void observe(Model<O> x);
/**
* Compute a new set of posterior parameters based upon the Observations that
* have been observed since my creation
*/
void computeParameters();
/**
* Return the number of observations that this model has seen since its
* parameters were last computed
*
* @return a long
*/
long getNumObservations();
/**
* Return the number of observations that this model has seen over its
* lifetime
*
* @return a long
*/
long getTotalObservations();
/**
* @return a sample of my posterior model
*/
Model<VectorWritable> sampleFromPosterior();
}
而具体到AbstractCluster类中是这样实现:
public void observe(Vector x) {
setS0(getS0() + 1);
if (getS1() == null) {
setS1(x.clone());
} else {
getS1().assign(x, Functions.PLUS);
}
Vector x2 = x.times(x);
if (getS2() == null) {
setS2(x2);
} else {
getS2().assign(x2, Functions.PLUS);
}
}
@Override
public void computeParameters() {
if (getS0() == 0) {
return;
}
setNumObservations((long) getS0());
setTotalObservations(getTotalObservations() + getNumObservations());
setCenter(getS1().divide(getS0()));
// compute the component stds
if (getS0() > 1) {
setRadius(getS2().times(getS0()).minus(getS1().times(getS1())).assign(new SquareRootFunction()).divide(getS0()));
}
setS0(0);
setS1(center.like());
setS2(center.like());
}
就是把簇的多个数学统计量进行保存更新(主要是均值和方差)。
Canopy聚类不要求指定簇个数,中心个数主要依赖于距离度量T1和T2的选择。如果数据集很大无法装入memory时,这时需要mapreduce框架进行执行,mapreduce实现使用了近似估算,所以对于同一个数据集来说,生成结果与in-memory的结果有细微差别。但是当数据集很大时这点区别可以忽略。Canopy聚类输出的Canopy中心很适合用来作为kmeans算法起始点,因为初始中心点准确率比随机选择要高,所以能够改善聚类结果并且加快算法速度。
Canopy聚类是一种很好的近似聚类技术,但是它有内存限制。如果距离阈值很接近,就会产生过多的Canopy中心,这样可能会超出内存范围。在实际当中算法应用时需要调优参数以适应数据集和聚类问题。
mapreduce实现中:
每个mapper处理其相应的数据,在这里处理的意思是使用Canopy算法来对所有的数据进行遍历,得到canopy。具体如下:首先随机取出一个样本向量作为一个canopy的中心向量,然后遍历样本数据向量集,若样本数据向量和随机样本向量的距离小于T1,则把该样本数据向量归入此canopy中,若距离小于T2,则把该样本数据从原始样本数据向量集中去除,直到整个样本数据向量集为空为止,输出所有的canopy的中心向量。reducer调用Reduce过程处理Map过程的输出,即整合所有Map过程产生的canopy的中心向量,生成新的canopy的中心向量,即最终的结果。
Mahout中kmeans 算法实现使用RandomSeedGenerator类生成包含k个向量的SequenceFile。尽管随机中心生成速度很快,但是无法保证为k个簇估计出好的中心。中心估计极大的影响着kmeans算法的执行时间。好的估计有助于算法更快的收敛,对数据遍历次数会更少。
canopy生成算法称为canopy聚类,是一种快速近似的聚类技术。它将输入数据点划分为一些重叠簇,称为canopy。在上下文中canopy指一组相近的点,或一个簇。canopy聚类基于两个距离阈值试图估计出可能的簇中心(或canopy中心)。
canopy聚类优势在于它得到簇的速度非常快,只需遍历一次数据即可获得结果。这个优势也是它的弱点。该算法无法给出精准的簇结果。但是它可以给出最优的簇数量,不需要像kmeans预先指定簇数量k。
算法流程:使用一个快速的距离测度两个距离阈值(T1和T2,其中T1>T2。它从一个包含一些点数据集和空的canopy列表开始,然后迭代这些数据,并在迭代过程中生成canopy。在每一轮迭代中,它从数据集中移除一个点并将一个以该点为中心的canopy加入列表。然后遍历数据集中剩下的数据点。对每一个点,它会计算其到列表中每个canopy的中心距离。如果距离均小于T1,则将该点加入该canopy。如果距离小于T2,则将其移除数据集,以免接下来的循环中用它建立新的canopy。重复上述过程直到数据集为空)
这种方法防止了紧邻一个现有canopy的点(距离小于T2)称为新的canopy中心。
网上抓了一个算法流程图:
canopy算法在Mahout中通过CanopyClusterer或CanopyDriver 类来实现,前者是基于in-memory算法进行聚类,后者是基于mapreduce 方法进行算法实现。这些实现既可以读写磁盘上的数据,也可以运行在hadoop集群上读写HDFS的数据。
首先定义了一个描述canopy的类。
package org.apache.mahout.clustering.canopy;
import org.apache.mahout.clustering.iterator.DistanceMeasureCluster;
import org.apache.mahout.common.distance.DistanceMeasure;
import org.apache.mahout.math.Vector;
/**
* This class models a canopy as a center point, the number of points that are contained within it according
* to the application of some distance metric, and a point total which is the sum of all the points and is
* used to compute the centroid when needed.
*/
public class Canopy extends DistanceMeasureCluster {
/** Used for deserialization as a writable */
public Canopy() { }
/**
* Create a new Canopy containing the given point and canopyId
*
* @param center a point in vector space
* @param canopyId an int identifying the canopy local to this process only
* @param measure a DistanceMeasure to use
*/
public Canopy(Vector center, int canopyId, DistanceMeasure measure) {
super(center, canopyId, measure);
observe(center);
}
public String asFormatString() {
return "C" + this.getId() + ": " + this.computeCentroid().asFormatString();
}
@Override
public String toString() {
return getIdentifier() + ": " + getCenter().asFormatString();
}
@Override
public String getIdentifier() {
return "C-" + getId();
}
}
CanopyClusterer中算法核心部分的实现
/**
* Iterate through the points, adding new canopies. Return the canopies.
*
* @param points
* a list<Vector> defining the points to be clustered
* @param measure
* a DistanceMeasure to use
* @param t1
* the T1 distance threshold
* @param t2
* the T2 distance threshold
* @return the List<Canopy> created
*/
public static List<Canopy> createCanopies(List<Vector> points,
DistanceMeasure measure,
double t1,
double t2) {
List<Canopy> canopies = Lists.newArrayList();
/**
* Reference Implementation: Given a distance metric, one can create
* canopies as follows: Start with a list of the data points in any
* order, and with two distance thresholds, T1 and T2, where T1 > T2.
* (These thresholds can be set by the user, or selected by
* cross-validation.) Pick a point on the list and measure its distance
* to all other points. Put all points that are within distance
* threshold T1 into a canopy. Remove from the list all points that are
* within distance threshold T2. Repeat until the list is empty.
*/
int nextCanopyId = 0;
while (!points.isEmpty()) {
Iterator<Vector> ptIter = points.iterator();
Vector p1 = ptIter.next();
ptIter.remove();
Canopy canopy = new Canopy(p1, nextCanopyId++, measure);
canopies.add(canopy);
while (ptIter.hasNext()) {
Vector p2 = ptIter.next();
double dist = measure.distance(p1, p2);
// Put all points that are within distance threshold T1 into the
// canopy
if (dist < t1) {
canopy.observe(p2);
}
// Remove from the list all points that are within distance
// threshold T2
if (dist < t2) {
ptIter.remove();
}
}
for (Canopy c : canopies) {
c.computeParameters();
}
}
return canopies;
}
代码中发现最关键就是canopy两个操作:observe和computerParameters方法。
canopy类前面知道 通过多层extend 自Model接口,该接口如下:
package org.apache.mahout.clustering;
import org.apache.hadoop.io.Writable;
import org.apache.mahout.math.VectorWritable;
/**
* A model is a probability distribution over observed data points and allows
* the probability of any data point to be computed. All Models have a
* persistent representation and extend
* WritablesampleFromPosterior(Model<VectorWritable>[])
*/
public interface Model<O> extends Writable {
/**
* Return the probability that the observation is described by this model
*
* @param x
* an Observation from the posterior
* @return the probability that x is in the receiver
*/
double pdf(O x);
/**
* Observe the given observation, retaining information about it
*
* @param x
* an Observation from the posterior
*/
void observe(O x);
/**
* Observe the given observation, retaining information about it
*
* @param x
* an Observation from the posterior
* @param weight
* a double weighting factor
*/
void observe(O x, double weight);
/**
* Observe the given model, retaining information about its observations
*
* @param x
* a Model<0>
*/
void observe(Model<O> x);
/**
* Compute a new set of posterior parameters based upon the Observations that
* have been observed since my creation
*/
void computeParameters();
/**
* Return the number of observations that this model has seen since its
* parameters were last computed
*
* @return a long
*/
long getNumObservations();
/**
* Return the number of observations that this model has seen over its
* lifetime
*
* @return a long
*/
long getTotalObservations();
/**
* @return a sample of my posterior model
*/
Model<VectorWritable> sampleFromPosterior();
}
而具体到AbstractCluster类中是这样实现:
public void observe(Vector x) {
setS0(getS0() + 1);
if (getS1() == null) {
setS1(x.clone());
} else {
getS1().assign(x, Functions.PLUS);
}
Vector x2 = x.times(x);
if (getS2() == null) {
setS2(x2);
} else {
getS2().assign(x2, Functions.PLUS);
}
}
@Override
public void computeParameters() {
if (getS0() == 0) {
return;
}
setNumObservations((long) getS0());
setTotalObservations(getTotalObservations() + getNumObservations());
setCenter(getS1().divide(getS0()));
// compute the component stds
if (getS0() > 1) {
setRadius(getS2().times(getS0()).minus(getS1().times(getS1())).assign(new SquareRootFunction()).divide(getS0()));
}
setS0(0);
setS1(center.like());
setS2(center.like());
}
就是把簇的多个数学统计量进行保存更新(主要是均值和方差)。
Canopy聚类不要求指定簇个数,中心个数主要依赖于距离度量T1和T2的选择。如果数据集很大无法装入memory时,这时需要mapreduce框架进行执行,mapreduce实现使用了近似估算,所以对于同一个数据集来说,生成结果与in-memory的结果有细微差别。但是当数据集很大时这点区别可以忽略。Canopy聚类输出的Canopy中心很适合用来作为kmeans算法起始点,因为初始中心点准确率比随机选择要高,所以能够改善聚类结果并且加快算法速度。
Canopy聚类是一种很好的近似聚类技术,但是它有内存限制。如果距离阈值很接近,就会产生过多的Canopy中心,这样可能会超出内存范围。在实际当中算法应用时需要调优参数以适应数据集和聚类问题。
mapreduce实现中:
每个mapper处理其相应的数据,在这里处理的意思是使用Canopy算法来对所有的数据进行遍历,得到canopy。具体如下:首先随机取出一个样本向量作为一个canopy的中心向量,然后遍历样本数据向量集,若样本数据向量和随机样本向量的距离小于T1,则把该样本数据向量归入此canopy中,若距离小于T2,则把该样本数据从原始样本数据向量集中去除,直到整个样本数据向量集为空为止,输出所有的canopy的中心向量。reducer调用Reduce过程处理Map过程的输出,即整合所有Map过程产生的canopy的中心向量,生成新的canopy的中心向量,即最终的结果。

相关文章推荐
- Hadoop_2.1.0 MapReduce序列图
- MongoDB中的MapReduce简介
- MongoDB学习笔记之MapReduce使用示例
- MongoDB中MapReduce编程模型使用实例
- MapReduce中ArrayWritable 使用指南
- Java函数式编程(七):MapReduce
- java连接hdfs ha和调用mapreduce jar示例
- 用PHP和Shell写Hadoop的MapReduce程序
- JavaScript mapreduce工作原理简析
- python中kmeans聚类实现代码
- mongodb mapredReduce 多个条件分组(group by)
- HBase基本原理
- HDFS DatanodeProtocol——sendHeartbeat
- HDFS DatanodeProtocol——register
- Hadoop集群提交作业问题总结
- Hadoop源码分析 HDFS ClientProtocol——addBlock
- Hadoop源码分析HDFS ClientProtocol——create
- Hadoop源码分析FSNamesystem几个重要的成员变量
- Hadoop源码分析HDFS ClientProtocol——getBlockLocations
- Hadoop源码分析HDFS Client向HDFS写入数据的过程解析