Python 模版(四)
2015-12-08 17:24
579 查看
九、time
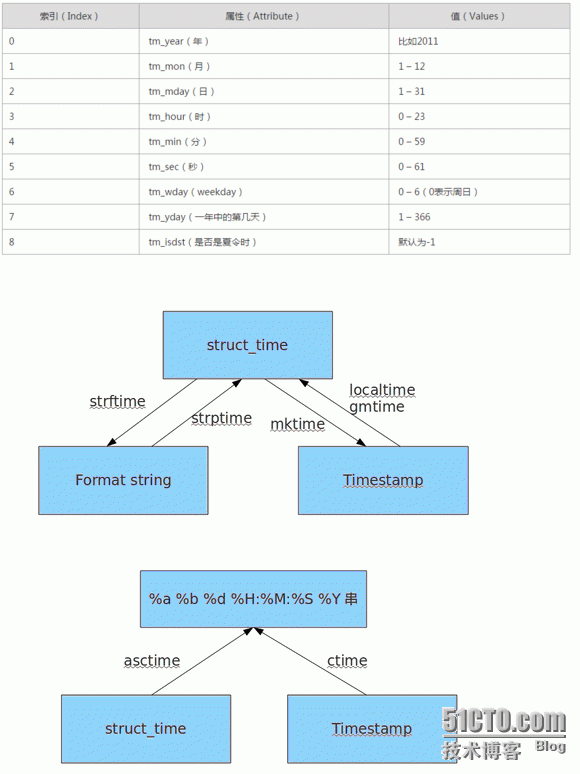
时间相关的操作,时间有三种表示方式:
时间戳 1970年1月1日之后的秒,即:time.time()
格式化的字符串 2014-11-11 11:11, 即:time.strftime('%Y-%m-%d')
结构化时间 元组包含了:年、日、星期等... time.struct_time 即: time.localtime()
十、re
re模块用于对python的正则表达式的操作。
字符:
. 匹配除换行符以外的任意字符
\w 匹配字母或数字或下划线或汉字
\s 匹配任意的空白符
\d 匹配数字
\b 匹配单词的开始或结束
^ 匹配字符串的开始
$ 匹配字符串的结束
次数:
* 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
从起始位置开始根据模型去字符串中匹配指定内容,匹配单个
正则表达式
要匹配的字符串
标志位,用于控制正则表达式的匹配方式
根据模型去字符串中匹配指定内容,匹配单个
上述两中方式均用于匹配单值,即:只能匹配字符串中的一个,如果想要匹配到字符串中所有符合条件的元素,则需要使用 findall。
5、sub(pattern, repl, string, count=0, flags=0)
用于替换匹配的字符串
相比于str.replace功能更加强大
6、split(pattern, string, maxsplit=0, flags=0)
根据指定匹配进行分组
随机数
时间相关的操作,时间有三种表示方式:
时间戳 1970年1月1日之后的秒,即:time.time()
格式化的字符串 2014-11-11 11:11, 即:time.strftime('%Y-%m-%d')
结构化时间 元组包含了:年、日、星期等... time.struct_time 即: time.localtime()
print time.time()
print time.mktime(time.localtime())
print time.gmtime() #可加时间戳参数
print time.localtime() #可加时间戳参数
print time.strptime('2014-11-11', '%Y-%m-%d')
print time.strftime('%Y-%m-%d') #默认当前时间
print time.strftime('%Y-%m-%d',time.localtime()) #默认当前时间
print time.asctime()
print time.asctime(time.localtime())
print time.ctime(time.time())
import datetime
'''
datetime.date:表示日期的类。常用的属性有year, month, day
datetime.time:表示时间的类。常用的属性有hour, minute, second, microsecond
datetime.datetime:表示日期时间
datetime.timedelta:表示时间间隔,即两个时间点之间的长度
timedelta([days[, seconds[, microseconds[, milliseconds[, minutes[, hours[, weeks]]]]]]])
strftime("%Y-%m-%d")
'''
import datetime
print datetime.datetime.now()
print datetime.datetime.now() - datetime.timedelta(days=5)十、re
re模块用于对python的正则表达式的操作。
字符:
. 匹配除换行符以外的任意字符
\w 匹配字母或数字或下划线或汉字
\s 匹配任意的空白符
\d 匹配数字
\b 匹配单词的开始或结束
^ 匹配字符串的开始
$ 匹配字符串的结束
次数:
* 重复零次或更多次
+ 重复一次或更多次
? 重复零次或一次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
IP:
^(25[0-5]|2[0-4]\d|[0-1]?\d?\d)(\.(25[0-5]|2[0-4]\d|[0-1]?\d?\d)){3}$
手机号:
^1[3|4|5|8][0-9]\d{8}$1、match(pattern, string, flags=0)从起始位置开始根据模型去字符串中匹配指定内容,匹配单个
正则表达式
要匹配的字符串
标志位,用于控制正则表达式的匹配方式
import re
obj = re.match('\d+', '123uuasf')
if obj:
print obj.group()# flags I = IGNORECASE = sre_compile.SRE_FLAG_IGNORECASE # ignore case L = LOCALE = sre_compile.SRE_FLAG_LOCALE # assume current 8-bit locale U = UNICODE = sre_compile.SRE_FLAG_UNICODE # assume unicode locale M = MULTILINE = sre_compile.SRE_FLAG_MULTILINE # make anchors look for newline S = DOTALL = sre_compile.SRE_FLAG_DOTALL # make dot match newline X = VERBOSE = sre_compile.SRE_FLAG_VERBOSE # ignore whitespace and comments2、search(pattern, string, flags=0)
根据模型去字符串中匹配指定内容,匹配单个
import re
obj = re.search('\d+', 'u123uu888asf')
if obj:
print obj.group()3、group和groupsa = "123abc456"
print re.search("([0-9]*)([a-z]*)([0-9]*)", a).group()
print re.search("([0-9]*)([a-z]*)([0-9]*)", a).group(0)
print re.search("([0-9]*)([a-z]*)([0-9]*)", a).group(1)
print re.search("([0-9]*)([a-z]*)([0-9]*)", a).group(2)
print re.search("([0-9]*)([a-z]*)([0-9]*)", a).groups()4、findall(pattern, string, flags=0)上述两中方式均用于匹配单值,即:只能匹配字符串中的一个,如果想要匹配到字符串中所有符合条件的元素,则需要使用 findall。
import re
obj = re.findall('\d+', 'fa123uu888asf')
print obj5、sub(pattern, repl, string, count=0, flags=0)
用于替换匹配的字符串
content = "123abc456"
new_content = re.sub('\d+', 'sb', content)
# new_content = re.sub('\d+', 'sb', content, 1)
print new_content相比于str.replace功能更加强大
6、split(pattern, string, maxsplit=0, flags=0)
根据指定匹配进行分组
content = "'1 - 2 * ((60-30+1*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2) )'"
new_content = re.split('\*', content)
# new_content = re.split('\*', content, 1)
print new_content
content = "'1 - 2 * ((60-30+1*(9-2*5/3+7/3*99/4*2998+10*568/14))-(-4*3)/(16-3*2) )'"
new_content = re.split('[\+\-\*\/]+', content)
# new_content = re.split('\*', content, 1)
print new_content
inpp = '1-2*((60-30 +(-40-5)*(9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2))'
inpp = re.sub('\s*','',inpp)
new_content = re.split('\(([\+\-\*\/]?\d+[\+\-\*\/]?\d+){1}\)', inpp, 1)
print new_content十一、random随机数
mport random print random.random() print random.randint(1,2) print random.randrange(1,10)随机验证码实例:
import random checkcode = '' for i in range(4): current = random.randrange(0,4) if current != i: temp = chr(random.randint(65,90)) else: temp = random.randint(0,9) checkcode += str(temp) print checkcode

相关文章推荐
- 数据库链接字符串查询网站
- Flex字符串比较 还有Flex字符串操作
- Ruby中创建字符串的一些技巧小结
- ASP下经常用的字符串等函数参考资料
- 将字符串小写转大写并延时输出的批处理代码
- 将字符串转换成System.Drawing.Color类型的方法
- Lua源码中字符串类型的实现
- Lua性能优化技巧(四):关于字符串
- 字符串聚合函数(去除重复值)
- Ruby中的字符串编写示例
- 总结的5个C#字符串操作方法分享
- sqlserver中求字符串中汉字的个数的sql语句
- sql server字符串非空判断实现方法
- VBS的字符串及日期操作相关函数
- C#实现将千分位字符串转换成数字的方法
- jquery 删除字符串最后一个字符的方法解析
- PowerShell实现在字符串中查找大写字母
- PowerShell中使用Out-String命令把对象转换成字符串输出的例子
- PowerShell中字符串使用单引号和双引号的区别
- Powershell小技巧之获取字符串的行数