C开发 中原子性操作 , 除了快什么都不剩下了
2015-12-06 20:12
405 查看
[b]题外话[/b]
今天,听歌曲听到一首缅怀迈克尔·杰克逊的歌曲 如下:
http://music.163.com/#/song?id=1696048 Breaking News

每次听迈克尔 音乐,特别有战斗力,特别兴奋,学起技术来也特别带感,推荐喜欢的人试试.
[b]前言[/b]
今天要说的是
1. 通过实际例子开头 说明 互斥量, 原子操作, 原子互斥锁 性能对比
2. 简单 说一下Linux 同样的性能对比
3. 构建一个跨平台的简单原子操作框架
4. Window 和 Linux 都简单测试一下
预备知识
1.线程的使用 最好是 posix线程库
2.简单C基础(说个 题外话,将C之父 那本书来回看个3遍,多写几遍,基本就是一个合格C程序员了)
参照资料
1. gcc 原子操作帮助文档 https://gcc.gnu.org/onlinedocs/gcc-4.1.1/gcc/Atomic-Builtins.html
2. Window 提供的原子操作API https://msdn.microsoft.com/en-us/library/windows/desktop/ms686360(v=vs.85).aspx#interlocked_functions
[b]正文[/b]
首先我们直奔 任务1, 通过实际例子开头 说明 互斥量, 原子操作, 原子互斥锁 性能对比
1.0 pthread 预备
需要会使用pthread 线程库,特别是在Window上, 在 Linux 默认就是posix 线程库,只需要在gcc 后面 加上 -lpthread 例如如下
没使用的可以 参照 我的其它博文,好像是一个介绍 printf 函数一个博文中简单讲解了,怎么 在Window上使用 pthread的全过程.
这里 再 简单说一下,为什么 要在 Window上折腾,是这样的 毕竟 是从开机 -> 走上程序开发道路 , 那时候 上大一,第一次了解Window其实个操作系统.
以前心里默认以为 window 就是 电脑,电脑就是window 二者是一个对映关系. 后来常在 Linux工作,开发学习. 还是觉得 Window有很多优点,是不错的操作系统.
其实 再闲扯一点(个人比较菜 望见谅)
Window 挺难的,源码 看得好恶心 工资低
Linux 简单,源码容易看,工资高一点
这 业界 喜好 就出来了.简单回报高,谁不喜欢.
1.1 简单看代码
这里先看下面代码 ,第一段 普通 pthread_mutex 互斥量
上面代码 特别标准,一般多线程程序代码,基本就是上面结构,扯一点 对于下面多线程函数
只有 在 通过
初始化的互斥量,才需要调用,对于直接 通过 初始化值初始化的互斥量就不需要调用了.
现在介绍 一个 原子操作的版本,先看Windows 的
这里函数 InterlockedExchangeAdd 是 Window.h 中提供的 具体的意思 如下
可以理解为,下面一起执行的操作命令集
最后介绍一个 利用原子操作 实现的互斥锁
这里同样简单 解释一下
上面函数 等价于 下面指令集一起执行.
对于
相当加锁 , 例如当 __lk 为 0 的时候,先进入的线程 设置为1,返回0它进入了,别的线程来了,返回的值可能是1,那么 就执行
Sleep(0),等待.假如你要是写成下面这样
就是 出名的 "忙等待 ",语言层等待函数, 测试结果是程序 基本上卡死. 这就 人一样,需要 休息 一下,才更有精力和动力 去做其它的事. 老是 加班效果不好. 但 没办法 , 因为自己只是个打工仔,,,,,
后面使用
将这个变量设置为 0 ,那么 另一个线程 执行 set 1时候,返回 0 while 退出,获得线程资源,就这样 循环起来了,是不是 恍然大悟!!!
上面三种实现 多线程竞争的访问资源的方式 ,都比较安全, 我们具体的看一下 测试结果 采用 Window 10 x64 + VS 2015 + Release + x86 模式 测试 截图如下:
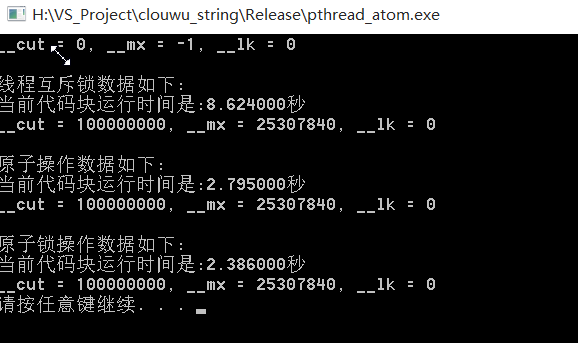
是不是很惊讶, 原子操作快 我也不说了,居然 原子互斥锁更快,但事实就是这样, 这里 可以更快一点 优化点在 Sleep(0), 这个函数 参数 以微秒记录. 更加优化,不同操作
系统,这个最优值不一样.这里 我就设了一个 性能可以的值. 大家可以尝试一下.
扯一点 在 Linux 中 有个函数 usleep 函数,在Window 上没有,但是也可以实现, 参照资料 如下
http://stackoverflow.com/questions/5801813/c-usleep-is-obsolete-workarounds-for-windows-mingw
觉得 Linux 的API 和 Window API 都各有所长,各有所短,综合而言还是 Linux API人性化一点,能够优化的东西更多.
完整的测试代码 如下
到这里 , 第一目标就告一段落,再扯一点,提升编程最好 手段 就是 临摹,如果人不聪明的话 多敲键盘.
2. 简单 说一下Linux 同样的性能对比
2.1 直接上代码
测试 代码 gcc_sync.c , 采用Ubuntu 15.10 操作系统,感觉挺好用的,比Centos 好用,好开发.大家试试
(这里,写的比较简单随意,我是先在Linux上测试的,测试之后再在Window上按照同样的设计思路写代码,开发中遇到比较难得问题,都是先用C写一遍稳固设计思路,再转成其它语言.)
编译命令是
测试结果 也 同样 ,所用时间 pthread_mutex > 原子加 > 原子互斥量
对于 上面代码 简单说一下
意思是 为__cut增加 1,并返回 原先的__cut值.
更加详细的关于 gcc 提供的原子操作,可以看 前言 中 参照资料的第一个.其实 gcc 提供的原子操作 "函数",真的 是魔法函数,是编译器层的不是语言层的.
Windows 上的 InterlockedExchangeAdd 还是 语言层的,有固定的返回类型.
对于下面函数,详细说一下
对于
等同于
对于 usleep(0), 这个自己也在测试 目前 测了一下 感觉 usleep(2) 效果比较好, 和操作系统和 硬件和 代码复杂度 关系大, 自己 目前就用 usleep(2); 这是个优化点.
最后一个是
将值设为0,和 __sync_lock_test_and_set 配套使用
等价于 下面原子操作
到这里 大概 原子操作的概念就建立起来,至少知道 原子操作怎么搞了.
3. 构建一个跨平台的简单原子操作框架
这里 同样直接上代码 ,再挨个解释. 代码总感觉有点难看, 但不知道怎么改,下次再优化
文件名 sc_atom.h
先将 这节的上面没出现过的api解析一下
首先是
这里
( c == InterlockedCompareExchange(&(v), (a), c)) 等价于
继续看看
对于
第一条api意思就是
第二个直接返回 tmp.
其实说的很简单,当你看到这你需要 看更多的资料,写 一点代码,才能 理解 它的作用,并可以在 以后的代码中使用它,轻巧的完成一些特定代码了.
到这里 不知道你是否和我一样兴奋,以后写 代码的速率又快乐一点. 扯一点,有一天去逛 一个 技术 站在云端的人的博文,底下有人评价 是这样的意思 "你也就是一个干了一辈子的技术狗".
思来思去,发现 能当一只 "狗" 也挺好, 至少 "狗的忠诚,狗的勇敢,狗对待朋友的热情" 太难得了.
最后总结,要想走得更远,还是少生气,少骂人的好,多行动,多给世界一点 热.
4. Window 和 Linux 都简单测试一下
这个就轻松了,首先 是 Window 上测试案例 如下
运行的没有问题,效果理想 运行图如下:
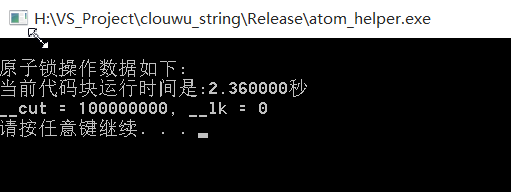
速度还可以.采用 Window 10 x64 + VS2015 + Release + x86
下面是Linux 上 测试 案例
环境是 Ubuntu 15.10 x64 + gcc 5.2.1
测试效果截图如下
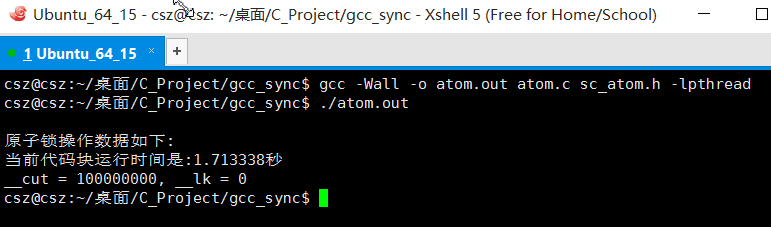
到这里 我们关于C中原子操作就告一段落,欢迎交流,互相提高. 有错误是肯定,指正之后马上改!
[b]后记[/b]
一天过得好快,下次继续分享,一些关于C开发中一些技巧. 有好博文的同行多发广告,不加班就去贵空间中拜访交流学习的.
今天,听歌曲听到一首缅怀迈克尔·杰克逊的歌曲 如下:
http://music.163.com/#/song?id=1696048 Breaking News
每次听迈克尔 音乐,特别有战斗力,特别兴奋,学起技术来也特别带感,推荐喜欢的人试试.
#include <stdio.h>
int man(int argc, char* argv[])
{
printf("Hope you are better %s\n","Michael Jackson");
return 0;
}[b]前言[/b]
今天要说的是
1. 通过实际例子开头 说明 互斥量, 原子操作, 原子互斥锁 性能对比
2. 简单 说一下Linux 同样的性能对比
3. 构建一个跨平台的简单原子操作框架
4. Window 和 Linux 都简单测试一下
预备知识
1.线程的使用 最好是 posix线程库
2.简单C基础(说个 题外话,将C之父 那本书来回看个3遍,多写几遍,基本就是一个合格C程序员了)
参照资料
1. gcc 原子操作帮助文档 https://gcc.gnu.org/onlinedocs/gcc-4.1.1/gcc/Atomic-Builtins.html
2. Window 提供的原子操作API https://msdn.microsoft.com/en-us/library/windows/desktop/ms686360(v=vs.85).aspx#interlocked_functions
[b]正文[/b]
首先我们直奔 任务1, 通过实际例子开头 说明 互斥量, 原子操作, 原子互斥锁 性能对比
1.0 pthread 预备
需要会使用pthread 线程库,特别是在Window上, 在 Linux 默认就是posix 线程库,只需要在gcc 后面 加上 -lpthread 例如如下
gcc -Wall -o atom.out atom.c sc_atom.h -lpthread
没使用的可以 参照 我的其它博文,好像是一个介绍 printf 函数一个博文中简单讲解了,怎么 在Window上使用 pthread的全过程.
这里 再 简单说一下,为什么 要在 Window上折腾,是这样的 毕竟 是从开机 -> 走上程序开发道路 , 那时候 上大一,第一次了解Window其实个操作系统.
以前心里默认以为 window 就是 电脑,电脑就是window 二者是一个对映关系. 后来常在 Linux工作,开发学习. 还是觉得 Window有很多优点,是不错的操作系统.
其实 再闲扯一点(个人比较菜 望见谅)
Window 挺难的,源码 看得好恶心 工资低
Linux 简单,源码容易看,工资高一点
这 业界 喜好 就出来了.简单回报高,谁不喜欢.
1.1 简单看代码
这里先看下面代码 ,第一段 普通 pthread_mutex 互斥量
//测试 pthread 互斥量
void* test_one(void* arg);
#define _INT_CUTS (2000000)
//测试 的全局区变量,默认值为0
static int __cut;
//全局的锁变量
static pthread_mutex_t __mx = PTHREAD_MUTEX_INITIALIZER;
void*
test_one(void* arg)
{
for (int i = 0; i < _INT_CUTS; ++i) {
pthread_mutex_lock(&__mx);
++__cut;
pthread_mutex_unlock(&__mx);
}
return NULL;
}上面代码 特别标准,一般多线程程序代码,基本就是上面结构,扯一点 对于下面多线程函数
PTW32_DLLPORT int PTW32_CDECL pthread_mutex_destroy (pthread_mutex_t * mutex);
只有 在 通过
PTW32_DLLPORT int PTW32_CDECL pthread_mutex_init (pthread_mutex_t * mutex, const pthread_mutexattr_t * attr);
初始化的互斥量,才需要调用,对于直接 通过 初始化值初始化的互斥量就不需要调用了.
现在介绍 一个 原子操作的版本,先看Windows 的
//测试 原子操作
void* test_two(void* arg);
#define _INT_CUTS (2000000)
//测试 的全局区变量,默认值为0
static int __cut;
//测试 原子操作
void*
test_two(void* arg)
{
for (int i = 0; i < _INT_CUTS; ++i) {
InterlockedExchangeAdd(&__cut, 1);
}
return NULL;
}这里函数 InterlockedExchangeAdd 是 Window.h 中提供的 具体的意思 如下
#define InterlockedExchangeAdd _InterlockedExchangeAdd /* * 原子操作,绑定在一起 完成 第一个数 = 第一个数+被加数 ,并返回开始加的时候第一个数 * Addend : 加数的地址 * Value : 被加数 */ LONG __cdecl InterlockedExchangeAdd ( _Inout_ _Interlocked_operand_ LONG volatile *Addend, _In_ LONG Value );
可以理解为,下面一起执行的操作命令集
tmp = old ; old = old + value ; return tmp ;
最后介绍一个 利用原子操作 实现的互斥锁
//测试 原子锁操作
void* test_three(void* arg);
#define _INT_CUTS (2000000)
//测试 的全局区变量,默认值为0
static int __cut;
//全局 锁
static int __lk;
//测试 原子锁操作
void*
test_three(void* arg)
{
for (int i = 0; i < _INT_CUTS; ++i) {
while (InterlockedExchange(&__lk, 1)) {
Sleep(0);
}
++__cut;
InterlockedExchange(&__lk, 0);
}
return NULL;
}这里同样简单 解释一下
#define InterlockedExchange _InterlockedExchange /* * 这个函数作用是 交换 *Target 和 Value 值,并返回老的值 * * Target : 目标值得地址 * Value : 待交换的值 * * return : 交换之前的 *Target 值 */ LONG __cdecl InterlockedExchange ( _Inout_ _Interlocked_operand_ LONG volatile *Target, _In_ LONG Value );
上面函数 等价于 下面指令集一起执行.
tmp = *Target ; *Target = Value ; Value = tmp ; return tmp ;
对于
while (InterlockedExchange(&__lk, 1)) {
Sleep(0);
}相当加锁 , 例如当 __lk 为 0 的时候,先进入的线程 设置为1,返回0它进入了,别的线程来了,返回的值可能是1,那么 就执行
Sleep(0),等待.假如你要是写成下面这样
while (InterlockedExchange(&__lk, 1)) { }就是 出名的 "忙等待 ",语言层等待函数, 测试结果是程序 基本上卡死. 这就 人一样,需要 休息 一下,才更有精力和动力 去做其它的事. 老是 加班效果不好. 但 没办法 , 因为自己只是个打工仔,,,,,
后面使用
InterlockedExchange(&__lk, 0);
将这个变量设置为 0 ,那么 另一个线程 执行 set 1时候,返回 0 while 退出,获得线程资源,就这样 循环起来了,是不是 恍然大悟!!!
上面三种实现 多线程竞争的访问资源的方式 ,都比较安全, 我们具体的看一下 测试结果 采用 Window 10 x64 + VS 2015 + Release + x86 模式 测试 截图如下:
是不是很惊讶, 原子操作快 我也不说了,居然 原子互斥锁更快,但事实就是这样, 这里 可以更快一点 优化点在 Sleep(0), 这个函数 参数 以微秒记录. 更加优化,不同操作
系统,这个最优值不一样.这里 我就设了一个 性能可以的值. 大家可以尝试一下.
扯一点 在 Linux 中 有个函数 usleep 函数,在Window 上没有,但是也可以实现, 参照资料 如下
http://stackoverflow.com/questions/5801813/c-usleep-is-obsolete-workarounds-for-windows-mingw
觉得 Linux 的API 和 Window API 都各有所长,各有所短,综合而言还是 Linux API人性化一点,能够优化的东西更多.
完整的测试代码 如下
#include "pthread.h"
#include <stdio.h>
#include <stdlib.h>
#include <Windows.h>
#include <time.h>
//1.0 简单的time帮助宏
#ifndef TIME_PRINT
#define TIME_PRINT(code) {\
clock_t __st,__et;\
__st=clock();\
code\
__et=clock();\
printf("当前代码块运行时间是:%lf秒\n",(0.0+__et-__st)/CLOCKS_PER_SEC);\
}
#endif /*!TIME_PRINT*/
//测试 pthread 互斥量
void* test_one(void* arg);
//测试 原子操作
void* test_two(void* arg);
//测试 原子锁操作
void* test_three(void* arg);
#define _INT_TIDS (50)
#define _INT_CUTS (2000000)
//测试 的全局区变量,默认值为0
static int __cut;
//全局的锁变量
static pthread_mutex_t __mx = PTHREAD_MUTEX_INITIALIZER;
//全局 锁
static int __lk;
static void __test_func(void* (*func)(void *))
{
pthread_t tids[_INT_TIDS];
int i;
for (i = 0; i < _INT_TIDS; ++i) {
pthread_create(tids + i, NULL, func, NULL);
}
//等待结束
for (i = 0; i < _INT_TIDS; ++i)
pthread_join(tids[i], NULL);
}
int main(int argc, char *argv[])
{
printf("__cut = %d, __mx = %d, __lk = %d\n", __cut, (int)__mx, __lk);
// 只为简单测试,没有做安全检查,假定都会调用成功
puts("\n线程互斥锁数据如下:");
__cut = 0;
TIME_PRINT({
__test_func(test_one);
});
printf("__cut = %d, __mx = %d, __lk = %d\n", __cut, (int)__mx, __lk);
puts("\n原子操作数据如下:");
__cut = 0;
TIME_PRINT({
__test_func(test_two);
});
printf("__cut = %d, __mx = %d, __lk = %d\n", __cut, (int)__mx, __lk);
puts("\n原子锁操作数据如下:");
__cut = 0;
TIME_PRINT({
__test_func(test_three);
});
printf("__cut = %d, __mx = %d, __lk = %d\n", __cut, (int)__mx, __lk);
system("pause");
return 0;
}
void*
test_one(void* arg)
{
for (int i = 0; i < _INT_CUTS; ++i) {
pthread_mutex_lock(&__mx);
++__cut;
pthread_mutex_unlock(&__mx);
}
return NULL;
}
//测试 原子操作
void*
test_two(void* arg)
{
for (int i = 0; i < _INT_CUTS; ++i) {
InterlockedExchangeAdd(&__cut, 1);
}
return NULL;
}
//测试 原子锁操作
void*
test_three(void* arg)
{
for (int i = 0; i < _INT_CUTS; ++i) {
while (InterlockedExchange(&__lk, 1)) {
Sleep(0);
}
++__cut;
InterlockedExchange(&__lk, 0);
}
return NULL;
}到这里 , 第一目标就告一段落,再扯一点,提升编程最好 手段 就是 临摹,如果人不聪明的话 多敲键盘.
2. 简单 说一下Linux 同样的性能对比
2.1 直接上代码
测试 代码 gcc_sync.c , 采用Ubuntu 15.10 操作系统,感觉挺好用的,比Centos 好用,好开发.大家试试
(这里,写的比较简单随意,我是先在Linux上测试的,测试之后再在Window上按照同样的设计思路写代码,开发中遇到比较难得问题,都是先用C写一遍稳固设计思路,再转成其它语言.)
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <time.h>
#include <unistd.h>
static int __cut = 0;
void* test_func(void* arg);
#define _INT_THREAD (30)
static pthread_mutex_t __mx = PTHREAD_MUTEX_INITIALIZER;
static int __lk = 0;
int main(int argc,char* argv[])
{
pthread_t tid[_INT_THREAD];
int i;
printf("__cut = %d\n",__cut);
clock_t st = clock();
for(i=0; i<20; ++i)
pthread_create(tid + i, NULL, test_func, NULL);
for(i=0; i<20; ++i)
pthread_join(tid[i], NULL);
clock_t et = clock();
printf("__cut = %d\n",__cut);
printf("经历了 %lf 秒\n",(et-st)*1.0/CLOCKS_PER_SEC);
return 0;
}
// 简单的测试 自增N次
void*
test_func(void* arg)
{
int i = 0;
while(i++<2000000){
//pthread_mutex_lock(&__mx);
//__sync_fetch_and_add(&__cut,1);
while(__sync_lock_test_and_set(&__lk,1)) {
usleep(0);
}
++__cut;
__sync_lock_release(&__lk);
//pthread_mutex_unlock(&__mx);
}
return NULL;
}编译命令是
gcc -g -Wall -o gcc_sync.out gcc_sync.c -lpthread
测试结果 也 同样 ,所用时间 pthread_mutex > 原子加 > 原子互斥量
对于 上面代码 简单说一下
__sync_fetch_and_add(&__cut,1);
意思是 为__cut增加 1,并返回 原先的__cut值.
更加详细的关于 gcc 提供的原子操作,可以看 前言 中 参照资料的第一个.其实 gcc 提供的原子操作 "函数",真的 是魔法函数,是编译器层的不是语言层的.
Windows 上的 InterlockedExchangeAdd 还是 语言层的,有固定的返回类型.
对于下面函数,详细说一下
while(__sync_lock_test_and_set(&__lk,1)) {
usleep(0);
}对于
/* * 原子操作,交换 *ptr 和 value ,并且返回交换后的 value值 * * type : 可以是1,2,4或8字节长度的int类型 , int8_t/uint64_t 都可以... * value : 目标 *ptr 交换的值 * ... : 后面的可扩展参数(...)用来指出哪些变量需要memory barrier,因为目前gcc实现的是full barrier,这个意思表示 这个函数之前的内存变量操作指令不会出现在这个函数之后执行. * * return : *ptr 之前的值就是 交换后的value */ type __sync_lock_test_and_set (type *ptr, type value, ...)
等同于
tmp = value ; value = *ptr ; *ptr = tmp ; return value ;
对于 usleep(0), 这个自己也在测试 目前 测了一下 感觉 usleep(2) 效果比较好, 和操作系统和 硬件和 代码复杂度 关系大, 自己 目前就用 usleep(2); 这是个优化点.
最后一个是
void __sync_lock_release (type *ptr, ...)This builtin releases the lock acquired by __sync_lock_test_and_set. Normally this means writing the constant 0 to *ptr.
将值设为0,和 __sync_lock_test_and_set 配套使用
等价于 下面原子操作
*ptr = 0
到这里 大概 原子操作的概念就建立起来,至少知道 原子操作怎么搞了.
3. 构建一个跨平台的简单原子操作框架
这里 同样直接上代码 ,再挨个解释. 代码总感觉有点难看, 但不知道怎么改,下次再优化
文件名 sc_atom.h
#ifndef _H_SC_ATOM
#define _H_SC_ATOM
/*
* 这段关于原子操作的宏 主要在 VS 和 GCC 中跑
*
* 为什么要用原子操作,因为它快,很快. 接近硬件层,怎么使用会做具体的注释
*/
#if defined(_MSC_VER)
//这里主要 _WIN32 操作 ,对于WIN64 没有做了,本质一样,函数后面加上64. 这里定位就是从简单的跨平台来来
#include <Windows.h>
//全部采用后置原子操作,先返回old的值 (前置等价 => tmp = v ; v = v + a ; return tmp)
#define SC_ATOM_ADD(v,a) \
InterlockedAdd(&(v),(a))
//将a的值设置给v,返回设置之前的值
#define SC_ATOM_SET(v,a) \
InterlockedExchange(&(v),(a))
// v == c ? swap(v,a) ; return true : return false.
#define SC_ATOM_COM(v,c,a) \
( c == InterlockedCompareExchange(&(v), (a), c))
//第一次使用 v最好是 0
#define SC_ATOM_LOCK(v) \
while(SC_ATOM_SET(v,1)) { \
Sleep(0); \
}
#define SC_ATOM_UNLOCK(v) \
SC_ATOM_SET(v,0)
#elif defined(__GNUC__)
#include <unistd.h>
//全部采用后置原子操作,先返回old的值 (前置等价 => a = i++)
#define SC_ATOM_ADD(v,a) \
__sync_fetch_and_add(&(v),(a))
//将a的值设置给v,返回设置之前的值
#define SC_ATOM_SET(v,a) \
__sync_lock_test_and_set(&(v),(a))
// v == c ? swap(v,a) return true : return false.
#define SC_ATOM_CMP(v,c,a) \
__sync_bool_compare_and_swap(&(v), (cmp), (val))
//等待的秒数,因环境而定 2是我自己测试的一个值
#define _INT_USLEEP (2)
#define SC_ATOM_LOCK(v) \
while(SC_ATOM_SET(v,1)) { \
usleep(_INT_USLEEP); \
}
#define SC_ATOM_UNLOCK(v) \
__sync_lock_release(&(v))
#endif /* _MSC_VER || __GNU__*/
#endif /*!_H_SC_ATOM*/先将 这节的上面没出现过的api解析一下
// v == c ? swap(v,a) ; return true : return false. #define SC_ATOM_COM(v,c,a) \ ( c == InterlockedCompareExchange(&(v), (a), c))
首先是
#define InterlockedCompareExchange _InterlockedCompareExchange /* * 原子操作,比较并交换,返回老的值 * *Destination == Comperand 就交换 *Destination 和 ExChange,并返回交换后的 * ExChange,如果不等 直接返回 *Destination */ LONG CDECL_NON_WVMPURE InterlockedCompareExchange ( _Inout_ _Interlocked_operand_ LONG volatile * Destination, _In_ LONG ExChange, _In_ LONG Comperand );
这里
( c == InterlockedCompareExchange(&(v), (a), c)) 等价于
tmp = v; v==c ? v =a : ; return c == tmp;
继续看看
#define SC_ATOM_CMP(v,c,a) \ __sync_bool_compare_and_swap(&(v), (cmp), (val))
对于
bool __sync_bool_compare_and_swap (type *ptr, type oldval type newval, ...); type __sync_val_compare_and_swap (type *ptr, type oldval type newval, ...); These builtins perform an atomic compare and swap. That is, if the current value of *ptr is oldval, then write newval into *ptr. The “bool” version returns true if the comparison is successful and newval was written. The “val” version returns the contents of *ptr before the operation.
第一条api意思就是
tmp = *ptr ; *ptr == oldval ? *ptr = newval : ; return tmp == oldval;
第二个直接返回 tmp.
其实说的很简单,当你看到这你需要 看更多的资料,写 一点代码,才能 理解 它的作用,并可以在 以后的代码中使用它,轻巧的完成一些特定代码了.
到这里 不知道你是否和我一样兴奋,以后写 代码的速率又快乐一点. 扯一点,有一天去逛 一个 技术 站在云端的人的博文,底下有人评价 是这样的意思 "你也就是一个干了一辈子的技术狗".
思来思去,发现 能当一只 "狗" 也挺好, 至少 "狗的忠诚,狗的勇敢,狗对待朋友的热情" 太难得了.
最后总结,要想走得更远,还是少生气,少骂人的好,多行动,多给世界一点 热.
4. Window 和 Linux 都简单测试一下
这个就轻松了,首先 是 Window 上测试案例 如下
#include <stdio.h>
#include <stdlib.h>
#include "sc_atom.h"
#include "pthread.h"
//1.0 简单的time帮助宏
#ifndef TIME_PRINT
#define TIME_PRINT(code) {\
clock_t __st,__et;\
__st=clock();\
code\
__et=clock();\
printf("当前代码块运行时间是:%lf秒\n",(0.0+__et-__st)/CLOCKS_PER_SEC);\
}
#endif /*!TIME_PRINT*/
//测试 的全局区变量,默认值为0
static int __cut;
//全局 锁
static int __lk;
//测试 原子锁操作
void* test_three(void* arg);
#define _INT_TIDS (50)
#define _INT_CUTS (2000000)
int main(int argc, char* argv[])
{
pthread_t tids[_INT_TIDS];
int i;
puts("\n原子锁操作数据如下:");
__cut = 0;
TIME_PRINT({
for (i = 0; i < _INT_TIDS; ++i) {
pthread_create(tids + i, NULL, test_three,NULL);
}
//等待结束
for (i = 0; i < _INT_TIDS; ++i)
pthread_join(tids[i],NULL);
});
printf("__cut = %d, __lk = %d\n", __cut, __lk);
system("pause");
return 0;
}
//测试 原子锁操作
void*
test_three(void* arg)
{
for (int i = 0; i < _INT_CUTS; ++i) {
SC_ATOM_LOCK(__lk);
++__cut;
SC_ATOM_UNLOCK(__lk);
}
return NULL;
}运行的没有问题,效果理想 运行图如下:
速度还可以.采用 Window 10 x64 + VS2015 + Release + x86
下面是Linux 上 测试 案例
环境是 Ubuntu 15.10 x64 + gcc 5.2.1
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include "sc_atom.h"
//1.0 简单的time帮助宏
#ifndef TIME_PRINT
#define TIME_PRINT(code) {\
clock_t __st,__et;\
__st=clock();\
code\
__et=clock();\
printf("当前代码块运行时间是:%lf秒\n",(0.0+__et-__st)/CLOCKS_PER_SEC);\
}
#endif /*!TIME_PRINT*/
//测试 的全局区变量,默认值为0
static int __cut;
//全局 锁
static int __lk;
//测试 原子锁操作
void* test_three(void* arg);
#define _INT_TIDS (50)
#define _INT_CUTS (2000000)
int main(int argc, char* argv[])
{
pthread_t tids[_INT_TIDS];
int i;
puts("\n原子锁操作数据如下:");
__cut = 0;
TIME_PRINT({
for (i = 0; i < _INT_TIDS; ++i) {
pthread_create(tids + i, NULL, test_three,NULL);
}
//等待结束
for (i = 0; i < _INT_TIDS; ++i)
pthread_join(tids[i],NULL);
});
printf("__cut = %d, __lk = %d\n", __cut, __lk);
return 0;
}
//测试 原子锁操作
void*
test_three(void* arg)
{
for (int i = 0; i < _INT_CUTS; ++i) {
SC_ATOM_LOCK(__lk);
++__cut;
SC_ATOM_UNLOCK(__lk);
}
return NULL;
}测试效果截图如下
到这里 我们关于C中原子操作就告一段落,欢迎交流,互相提高. 有错误是肯定,指正之后马上改!
[b]后记[/b]
一天过得好快,下次继续分享,一些关于C开发中一些技巧. 有好博文的同行多发广告,不加班就去贵空间中拜访交流学习的.

相关文章推荐
- 信息安全系统设计基础第十三周学习总结
- Struts2框架学习(一)
- Android -- List View
- 4、HQL
- String类型(字符串类型)
- 配置mysql5.5主从服务器(转)
- mysql的root密码重置
- live555源代码分析
- BFC
- 第十三周学习笔记
- 鸟瞰数据结构
- iOS:GitHub上值得关注的iOS开源项目
- 3、Hibernate的Annotation
- CSAPP之一:程序生命周期漫谈
- spring框架学习(六)AOP
- 2、Hibernate的映射
- github和bitbucket
- C-051.static和extern在局部变量中的作用
- [生物工程与基因]安徒生童话-海的女儿
- 关于接口的理解