使用伪hash降低索引长度
2015-12-02 14:11
253 查看
理想的索引
1:查询频繁 2:区分度高 3:长度小 4: 尽量能覆盖常用查询字段.
1: 索引长度直接影响索引文件的大小,影响增删改的速度,并间接影响查询速度(占用内存多).
针对列中的值,从左往右截取部分,来建索引
1: 截的越短, 重复度越高,区分度越小, 索引效果越不好
2: 截的越长, 重复度越低,区分度越高, 索引效果越好,但带来的影响也越大--增删改变慢,并间影响查询速度.
所以, 我们要在 区分度 + 长度 两者上,取得一个平衡.
惯用手法: 截取不同长度,并测试其区分度,
mysql> select count(distinct left(word,6))/count(*) from dict;
+---------------------------------------+
| count(distinct left(word,6))/count(*) |
+---------------------------------------+
| 0.9992 |
+---------------------------------------+
1 row in set (0.30 sec)
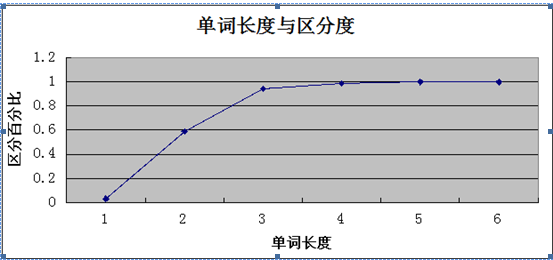
对于一般的系统应用: 区别度能达到0.1,索引的性能就可以接受.
2:对于左前缀不易区分的列 ,建立索引的技巧
如 url列
http://www.baidu.com
http://www.zixue.it
列的前11个字符都是一样的,不易区分, 可以用如下2个办法来解决
1: 把列内容倒过来存储,并建立索引
Moc.udiab.www//:ptth
Ti.euxiz.www//://ptth
这样左前缀区分度大,
2: 伪hash索引效果
同时存 url_hash列
3:多列索引
3.1 多列索引的考虑因素---
列的查询频率 , 列的区分度,
以ecshop商城为例, goods表中的cat_id,brand_id,做多列索引
从区分度看,Brand_id区分度更高,
mysql> select count(distinct cat_id) / count(*)
from goods;
+-----------------------------------+
| count(distinct cat_id) / count(*) |
+-----------------------------------+
| 0.2903 |
+-----------------------------------+
1 row in set (0.00 sec)
mysql> select count(distinct brand_id) /
count(*) from goods;
+-------------------------------------+
| count(distinct brand_id) / count(*) |
+-------------------------------------+
| 0.3871 |
+-------------------------------------+
1 row in set (0.00 sec)
但从 商城的实际业务业务看, 顾客一般先选大分类->小分类->品牌,
最终选择 index(cat_id,brand_id)来建立索引
1:查询频繁 2:区分度高 3:长度小 4: 尽量能覆盖常用查询字段.
1: 索引长度直接影响索引文件的大小,影响增删改的速度,并间接影响查询速度(占用内存多).
针对列中的值,从左往右截取部分,来建索引
1: 截的越短, 重复度越高,区分度越小, 索引效果越不好
2: 截的越长, 重复度越低,区分度越高, 索引效果越好,但带来的影响也越大--增删改变慢,并间影响查询速度.
所以, 我们要在 区分度 + 长度 两者上,取得一个平衡.
惯用手法: 截取不同长度,并测试其区分度,
mysql> select count(distinct left(word,6))/count(*) from dict;
+---------------------------------------+
| count(distinct left(word,6))/count(*) |
+---------------------------------------+
| 0.9992 |
+---------------------------------------+
1 row in set (0.30 sec)
对于一般的系统应用: 区别度能达到0.1,索引的性能就可以接受.
2:对于左前缀不易区分的列 ,建立索引的技巧
如 url列
http://www.baidu.com
http://www.zixue.it
列的前11个字符都是一样的,不易区分, 可以用如下2个办法来解决
1: 把列内容倒过来存储,并建立索引
Moc.udiab.www//:ptth
Ti.euxiz.www//://ptth
这样左前缀区分度大,
2: 伪hash索引效果
同时存 url_hash列
3:多列索引
3.1 多列索引的考虑因素---
列的查询频率 , 列的区分度,
以ecshop商城为例, goods表中的cat_id,brand_id,做多列索引
从区分度看,Brand_id区分度更高,
mysql> select count(distinct cat_id) / count(*)
from goods;
+-----------------------------------+
| count(distinct cat_id) / count(*) |
+-----------------------------------+
| 0.2903 |
+-----------------------------------+
1 row in set (0.00 sec)
mysql> select count(distinct brand_id) /
count(*) from goods;
+-------------------------------------+
| count(distinct brand_id) / count(*) |
+-------------------------------------+
| 0.3871 |
+-------------------------------------+
1 row in set (0.00 sec)
但从 商城的实际业务业务看, 顾客一般先选大分类->小分类->品牌,
最终选择 index(cat_id,brand_id)来建立索引

相关文章推荐
- 搭建本地base、extra、epel、openstack源
- UISwitch控件的常用属性
- linux 信号
- android URI 和 UIL 图片加载问题
- 自动清理归档
- 使用AsyncTask实现图片加载
- 虚拟机环境linux网络配置
- VMware Horizon虚拟桌面工具箱2.0-审计,远程协助,控制台,电源
- DOM、JDOM、DOM4J的区别
- asp.net DataTable 进行表内排序
- 查看锁信息
- spring源码解析-Ioc1
- jquery+java选中批量删除
- 4.7编写一个函数,从一个字符串中去除多余的空格。
- SCF架构开发:Maven+weblogic+eclipse开发总结
- tar 解压缩命令详解
- UITextView使用总结
- Fork/Join实例
- 编程基础知识之变量赋值
- js的input框限制输入内容