Spark修炼之道(进阶篇)——Spark入门到精通:第十四节 Spark Streaming 缓存、Checkpoint机制
2015-11-30 23:42
435 查看
作者:周志湖
微信号:zhouzhihubeyond
Spark Stream 缓存
Checkpoint
案例
从上面的方法来看,它最返回的是一个ReducedWindowedDStream对象,跳到该类的源码中可以看到在其主构造函数中包含下面两段代码:
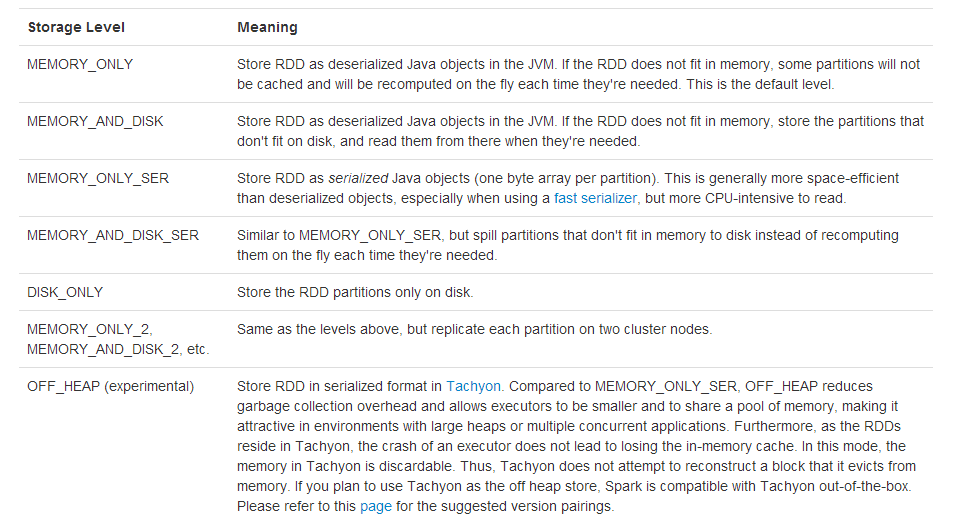
通过上面的代码我们可以看到,通过窗口操作产生的DStream不需要开发人员手动去调用persist方法,Spark会自动帮我们将数据缓存当内存当中。同一般的RDD类似,DStream支持的persisit级别为:
(1)Metadata checkpointing
将流式计算的信息保存到具备容错性的存储上如HDFS,Metadata Checkpointing适用于当streaming应用程序Driver所在的节点出错时能够恢复,元数据包括:
Configuration(配置信息) - 创建streaming应用程序的配置信息
DStream operations - 在streaming应用程序中定义的DStreaming操作
Incomplete batches - 在列队中没有处理完的作业
(2)Data checkpointing
将生成的RDD保存到外部可靠的存储当中,对于一些数据跨度为多个bactch的有状态tranformation操作来说,checkpoint非常有必要,因为在这些transformation操作生成的RDD对前一RDD有依赖,随着时间的增加,依赖链可能会非常长,checkpoint机制能够切断依赖链,将中间的RDD周期性地checkpoint到可靠存储当中,从而在出错时可以直接从checkpoint点恢复。
具体来说,metadata checkpointing主要还是从drvier失败中恢复,而Data Checkpoing用于对有状态的transformation操作进行checkpointing
Checkpointing具体的使用方式时通过下列方法:
进行了适量修改
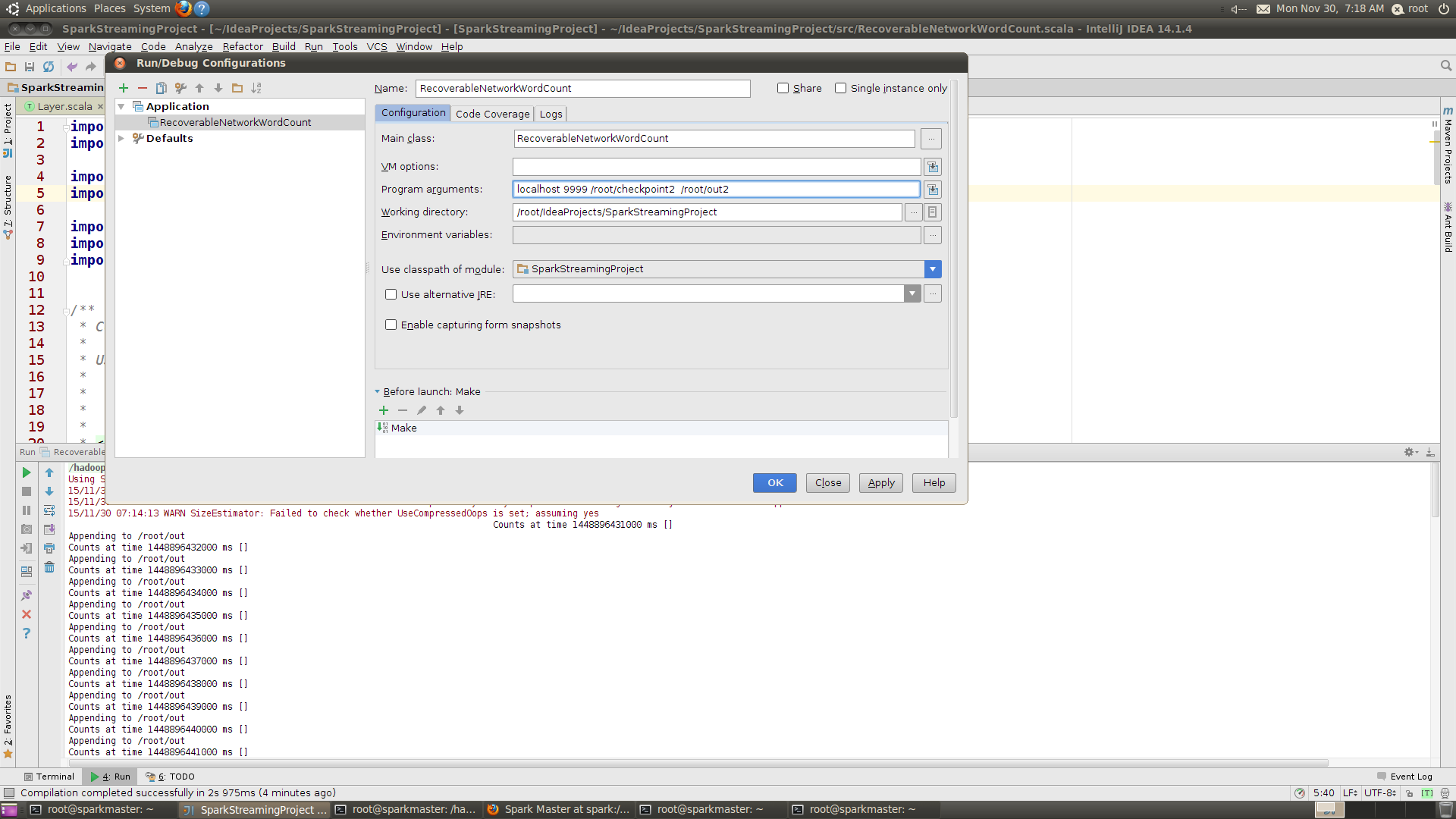
输入参数配置如下:
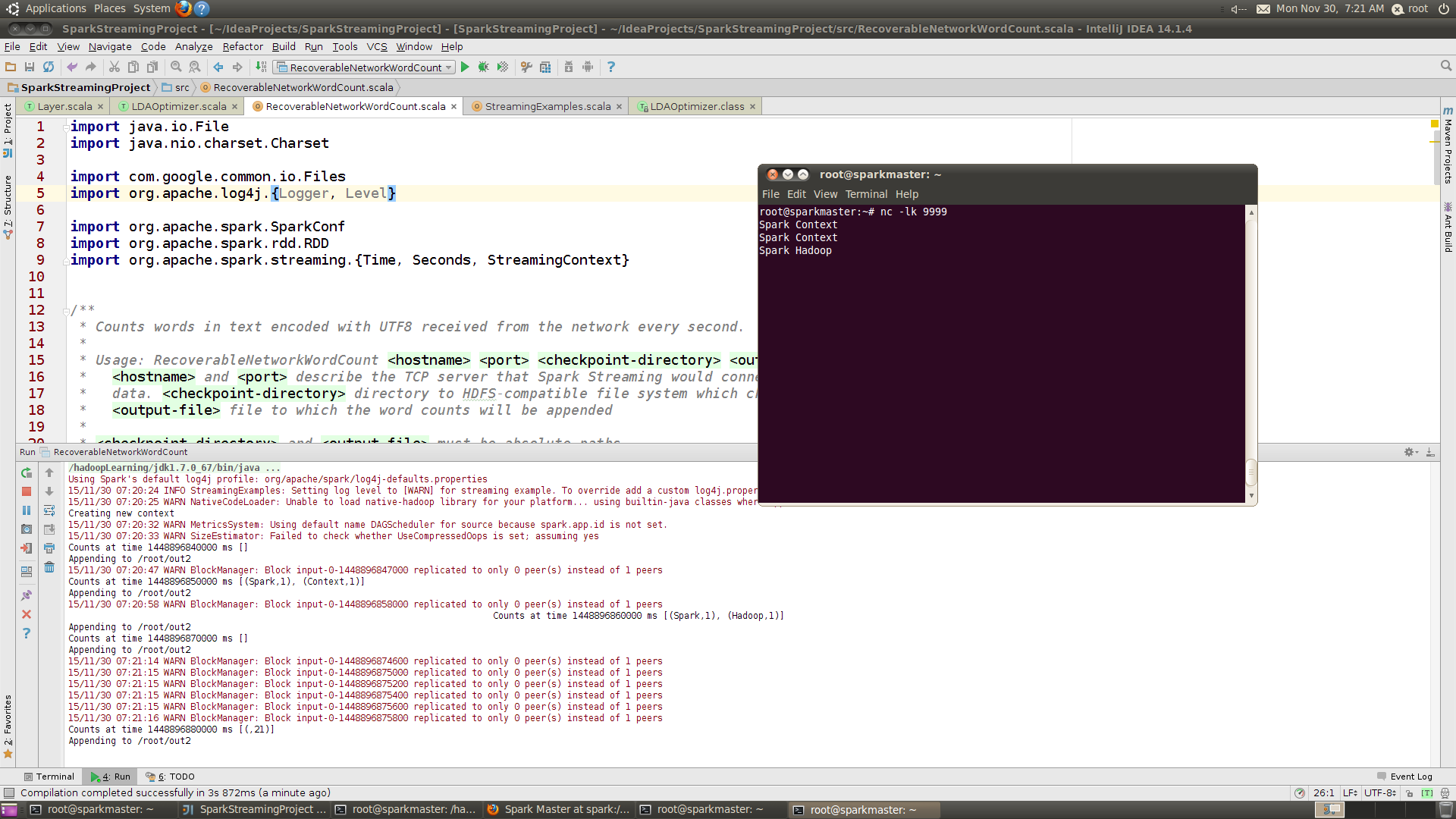
运行状态图如下:
首次运行时:
手动将程序停止,然后重新运行
微信号:zhouzhihubeyond
主要内容
本节内容基于官方文档:http://spark.apache.org/docs/latest/streaming-programming-guide.htmlSpark Stream 缓存
Checkpoint
案例
1. Spark Stream 缓存
通过前面一系列的课程介绍,我们知道DStream是由一系列的RDD构成的,它同一般的RDD一样,也可以将流式数据持久化到内容当中,采用的同样是persisit方法,调用该方法后DStream将持久化所有的RDD数据。这对于一些需要重复计算多次或数据需要反复被使用的DStream特别有效。像reduceByWindow、reduceByKeyAndWindow等基于窗口操作的方法,它们默认都是有persisit操作的。reduceByKeyAndWindow方法源码具体如下:def reduceByKeyAndWindow(
reduceFunc: (V, V) => V,
invReduceFunc: (V, V) => V,
windowDuration: Duration,
slideDuration: Duration,
partitioner: Partitioner,
filterFunc: ((K, V)) => Boolean
): DStream[(K, V)] = ssc.withScope {
val cleanedReduceFunc = ssc.sc.clean(reduceFunc)
val cleanedInvReduceFunc = ssc.sc.clean(invReduceFunc)
val cleanedFilterFunc = if (filterFunc != null) Some(ssc.sc.clean(filterFunc)) else None
new ReducedWindowedDStream[K, V](
self, cleanedReduceFunc, cleanedInvReduceFunc, cleanedFilterFunc,
windowDuration, slideDuration, partitioner
)
}从上面的方法来看,它最返回的是一个ReducedWindowedDStream对象,跳到该类的源码中可以看到在其主构造函数中包含下面两段代码:
private[streaming]
class ReducedWindowedDStream[K: ClassTag, V: ClassTag](
parent: DStream[(K, V)],
reduceFunc: (V, V) => V,
invReduceFunc: (V, V) => V,
filterFunc: Option[((K, V)) => Boolean],
_windowDuration: Duration,
_slideDuration: Duration,
partitioner: Partitioner
) extends DStream[(K, V)](parent.ssc) {
//省略其它非关键代码
//默认被缓存到内存当中
// Persist RDDs to memory by default as these RDDs are going to be reused.
super.persist(StorageLevel.MEMORY_ONLY_SER)
reducedStream.persist(StorageLevel.MEMORY_ONLY_SER)
}通过上面的代码我们可以看到,通过窗口操作产生的DStream不需要开发人员手动去调用persist方法,Spark会自动帮我们将数据缓存当内存当中。同一般的RDD类似,DStream支持的persisit级别为:
2. Checkpoint机制
通过前期对Spark Streaming的理解,我们知道,Spark Streaming应用程序如果不手动停止,则将一直运行下去,在实际中应用程序一般是24小时*7天不间断运行的,因此Streaming必须对诸如系统错误、JVM出错等与程序逻辑无关的错误(failures )具体很强的弹性,具备一定的非应用程序出错的容错性。Spark Streaming的Checkpoint机制便是为此设计的,它将足够多的信息checkpoint到某些具备容错性的存储系统如HDFS上,以便出错时能够迅速恢复。有两种数据可以chekpoint:(1)Metadata checkpointing
将流式计算的信息保存到具备容错性的存储上如HDFS,Metadata Checkpointing适用于当streaming应用程序Driver所在的节点出错时能够恢复,元数据包括:
Configuration(配置信息) - 创建streaming应用程序的配置信息
DStream operations - 在streaming应用程序中定义的DStreaming操作
Incomplete batches - 在列队中没有处理完的作业
(2)Data checkpointing
将生成的RDD保存到外部可靠的存储当中,对于一些数据跨度为多个bactch的有状态tranformation操作来说,checkpoint非常有必要,因为在这些transformation操作生成的RDD对前一RDD有依赖,随着时间的增加,依赖链可能会非常长,checkpoint机制能够切断依赖链,将中间的RDD周期性地checkpoint到可靠存储当中,从而在出错时可以直接从checkpoint点恢复。
具体来说,metadata checkpointing主要还是从drvier失败中恢复,而Data Checkpoing用于对有状态的transformation操作进行checkpointing
Checkpointing具体的使用方式时通过下列方法:
//checkpointDirectory为checkpoint文件保存目录 streamingContext.checkpoint(checkpointDirectory)
3. 案例
程序来源:https://github.com/apache/spark/blob/master/examples/src/main/scala/org/apache/spark/examples/streaming/RecoverableNetworkWordCount.scala进行了适量修改
import java.io.File
import java.nio.charset.Charset
import com.google.common.io.Files
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.{Time, Seconds, StreamingContext}
import org.apache.spark.util.IntParam
/**
* Counts words in text encoded with UTF8 received from the network every second.
*
* Usage: RecoverableNetworkWordCount <hostname> <port> <checkpoint-directory> <output-file>
* <hostname> and <port> describe the TCP server that Spark Streaming would connect to receive
* data. <checkpoint-directory> directory to HDFS-compatible file system which checkpoint data
* <output-file> file to which the word counts will be appended
*
* <checkpoint-directory> and <output-file> must be absolute paths
*
* To run this on your local machine, you need to first run a Netcat server
*
* `$ nc -lk 9999`
*
* and run the example as
*
* `$ ./bin/run-example org.apache.spark.examples.streaming.RecoverableNetworkWordCount \
* localhost 9999 ~/checkpoint/ ~/out`
*
* If the directory ~/checkpoint/ does not exist (e.g. running for the first time), it will create
* a new StreamingContext (will print "Creating new context" to the console). Otherwise, if
* checkpoint data exists in ~/checkpoint/, then it will create StreamingContext from
* the checkpoint data.
*
* Refer to the online documentation for more details.
*/
object RecoverableNetworkWordCount {
def createContext(ip: String, port: Int, outputPath: String, checkpointDirectory: String)
: StreamingContext = {
//程序第一运行时会创建该条语句,如果应用程序失败,则会从checkpoint中恢复,该条语句不会执行
println("Creating new context")
val outputFile = new File(outputPath)
if (outputFile.exists()) outputFile.delete()
val sparkConf = new SparkConf().setAppName("RecoverableNetworkWordCount").setMaster("local[4]")
// Create the context with a 1 second batch size
val ssc = new StreamingContext(sparkConf, Seconds(1))
ssc.checkpoint(checkpointDirectory)
//将socket作为数据源
val lines = ssc.socketTextStream(ip, port)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.foreachRDD((rdd: RDD[(String, Int)], time: Time) => {
val counts = "Counts at time " + time + " " + rdd.collect().mkString("[", ", ", "]")
println(counts)
println("Appending to " + outputFile.getAbsolutePath)
Files.append(counts + "\n", outputFile, Charset.defaultCharset())
})
ssc
}
//将String转换成Int
private object IntParam {
def unapply(str: String): Option[Int] = {
try {
Some(str.toInt)
} catch {
case e: NumberFormatException => None
}
}
}
def main(args: Array[String]) {
if (args.length != 4) {
System.err.println("You arguments were " + args.mkString("[", ", ", "]"))
System.err.println(
"""
|Usage: RecoverableNetworkWordCount <hostname> <port> <checkpoint-directory>
| <output-file>. <hostname> and <port> describe the TCP server that Spark
| Streaming would connect to receive data. <checkpoint-directory> directory to
| HDFS-compatible file system which checkpoint data <output-file> file to which the
| word counts will be appended
|
|In local mode, <master> should be 'local
' with n > 1
|Both <checkpoint-directory> and <output-file> must be absolute paths
""".stripMargin
)
System.exit(1)
}
val Array(ip, IntParam(port), checkpointDirectory, outputPath) = args
//getOrCreate方法,从checkpoint中重新创建StreamingContext对象或新创建一个StreamingContext对象
val ssc = StreamingContext.getOrCreate(checkpointDirectory,
() => {
createContext(ip, port, outputPath, checkpointDirectory)
})
ssc.start()
ssc.awaitTermination()
}
}输入参数配置如下:
运行状态图如下:
首次运行时:
//创建新的StreamingContext Creating new context 15/11/30 07:20:32 WARN MetricsSystem: Using default name DAGScheduler for source because spark.app.id is not set. 15/11/30 07:20:33 WARN SizeEstimator: Failed to check whether UseCompressedOops is set; assuming yes Counts at time 1448896840000 ms [] Appending to /root/out2 15/11/30 07:20:47 WARN BlockManager: Block input-0-1448896847000 replicated to only 0 peer(s) instead of 1 peers Counts at time 1448896850000 ms [(Spark,1), (Context,1)]
手动将程序停止,然后重新运行
//这时从checkpoint目录中读取元数据信息,进行StreamingContext的恢复 Counts at time 1448897070000 ms [] Appending to /root/out2 Counts at time 1448897080000 ms [] Appending to /root/out2 Counts at time 1448897090000 ms [] Appending to /root/out2 15/11/30 07:24:58 WARN BlockManager: Block input-0-1448897098600 replicated to only 0 peer(s) instead of 1 peers [Stage 8:> (0 + 0) / 4]Counts at time 1448897100000 ms [(Spark,1), (Context,1)] Appending to /root/out2

相关文章推荐
- Spark RDD API详解(一) Map和Reduce
- 使用spark和spark mllib进行股票预测
- Spark随谈——开发指南(译)
- Spark,一种快速数据分析替代方案
- eclipse 开发 spark Streaming wordCount
- Understanding Spark Caching
- Windows 下Spark 快速搭建Spark源码阅读环境
- Spark中将对象序列化存储到hdfs
- Spark初探
- Spark Streaming初探
- 搭建hadoop/spark集群环境
- 整合Kafka到Spark Streaming——代码示例和挑战
- Spark 性能相关参数配置详解-任务调度篇
- 基于spark1.3.1的spark-sql实战-01
- 基于spark1.3.1的spark-sql实战-02
- 在 Databricks 可获得 Spark 1.5 预览版
- spark standalone模式 zeppelin安装
- Apache Spark 1.5.0正式发布
- Tachyon 0.7.1伪分布式集群安装与测试
- spark取得lzo压缩文件报错 java.lang.ClassNotFoundException