MySQL数据库获取多个汉字拼音的首字母函数
2015-11-30 00:16
543 查看
[b]需求简介:最近的一个项目,想实现如下图所示的显示效果。很明显,如果能够获取对应的汉字词组中每个汉字的拼音首字母就可以实现了,如果是固定的几组汉字,人为的拼一下就可以 了,不过项目中有多处功能需要这个效果,并且事先也不知道对应的汉字是什么,所以就需要一个函数来完成这件事情了,根据网上查询的资料自己改进了一个 函数实现的效果,现分享如下。[/b]
[b]

[/b]
[b]1:阅读建议[/b]
[b] 如果你还没有看过我上一篇博文——MySQL数据库获取汉字拼音的首字母函数,强烈建议请先看一下,因为本篇博文是在她的基础之上写的,相关雷同的描述,本文就不再啰嗦了,比如:测试环境、测试数据、函数的编写说明、函数的使用简介等。本篇博文所介绍的函数,无非是针对多个汉字获取其拼音的首字母的,和上一篇博文相比仅多了一层循环处理,其他的基本一致。[/b]
[b]2:测试功能[/b]
[b][b] 测试的函数的功能为,根据汉字词组或者单个汉字,获取其对应的拼音首字母,比如:你爱我吗?获取的是 NAWM? [b],如果是非汉字字符则不做处理。[/b][/b][/b]
[b]3:函数代码[/b]
[b]4:函数的使用效果[/b]
[b]
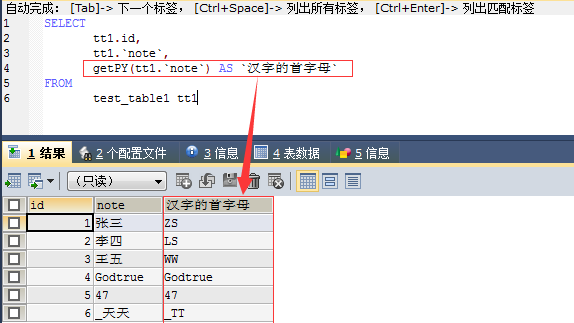
[/b]
[b]5:理解函数思想的参看资料[/b]
[b]http://www.4jhm.com/hzcode/queryg.php?enter=CED2[/b]
[b]http://zd.diyifanwen.com/zidian/py/[/b]
[b]http://www.qqxiuzi.cn/zh/hanzi-gbk-bianma.php[/b]
[b]6:函数说明[/b]
[b]整个函数,如果明白了各个系统函数的使用方式,就没有什么不好理解的了,就有一个函数的使用有些不太好理解,如下所示:[/b]
[b]
[/b]
[b]1:阅读建议[/b]
[b] 如果你还没有看过我上一篇博文——MySQL数据库获取汉字拼音的首字母函数,强烈建议请先看一下,因为本篇博文是在她的基础之上写的,相关雷同的描述,本文就不再啰嗦了,比如:测试环境、测试数据、函数的编写说明、函数的使用简介等。本篇博文所介绍的函数,无非是针对多个汉字获取其拼音的首字母的,和上一篇博文相比仅多了一层循环处理,其他的基本一致。[/b]
[b]2:测试功能[/b]
[b][b] 测试的函数的功能为,根据汉字词组或者单个汉字,获取其对应的拼音首字母,比如:你爱我吗?获取的是 NAWM? [b],如果是非汉字字符则不做处理。[/b][/b][/b]
[b]3:函数代码[/b]
DELIMITER $$ USE `test`$$ DROP FUNCTION IF EXISTS `getPY`$$ CREATE DEFINER=`hjd`@`%` FUNCTION `getPY`(in_string VARCHAR(21845)) RETURNS VARCHAR(21845) CHARSET utf8 BEGIN #截取字符串,每次做截取后的字符串存放在该变量中,初始为函数参数in_string值 DECLARE tmp_str VARCHAR(21845) CHARSET gbk DEFAULT '' ; #tmp_str的长度 DECLARE tmp_len SMALLINT DEFAULT 0; #tmp_str的长度 DECLARE tmp_loc SMALLINT DEFAULT 0; #截取字符,每次 left(tmp_str,1) 返回值存放在该变量中 DECLARE tmp_char VARCHAR(2) CHARSET gbk DEFAULT ''; #结果字符串 DECLARE tmp_rs VARCHAR(21845)CHARSET gbk DEFAULT ''; #拼音字符,存放单个汉字对应的拼音首字符 DECLARE tmp_cc VARCHAR(2) CHARSET gbk DEFAULT ''; #初始化,将in_string赋给tmp_str SET tmp_str = in_string; #初始化长度 SET tmp_len = LENGTH(tmp_str); #如果被计算的tmp_str长度大于0则进入该while WHILE tmp_len > 0 DO #获取tmp_str最左端的首个字符,注意这里是获取首个字符,该字符可能是汉字,也可能不是。 SET tmp_char = LEFT(tmp_str,1); #左端首个字符赋值给拼音字符 SET tmp_cc = tmp_char; #获取字符的编码范围的位置,为了确认汉字拼音首字母是那一个 SET tmp_loc=INTERVAL(CONV(HEX(tmp_char),16,10),0xB0A1,0xB0C5,0xB2C1,0xB4EE,0xB6EA,0xB7A2,0xB8C1,0xB9FE,0xBBF7,0xBFA6,0xC0AC ,0xC2E8,0xC4C3,0xC5B6,0xC5BE,0xC6DA,0xC8BB,0xC8F6,0xCBFA,0xCDDA ,0xCEF4,0xD1B9,0xD4D1); #判断左端首个字符是多字节还是单字节字符,要是多字节则认为是汉字且作以下拼音获取,要是单字节则不处理。如果是多字节字符但是不在对应的编码范围之内,即对应的不是大写字母则也不做处理,这样数字或者特殊字符就保持原样了 IF (LENGTH(tmp_char)>1 AND tmp_loc>0 AND tmp_loc<24) THEN #获得汉字拼音首字符 SELECT ELT(tmp_loc,'A','B','C','D','E','F','G','H','J','K','L','M','N','O','P','Q','R','S','T','W','X','Y','Z') INTO tmp_cc; END IF; #将当前tmp_str左端首个字符拼音首字符与返回字符串拼接 SET tmp_rs = CONCAT(tmp_rs,tmp_cc); #将tmp_str左端首字符去除 SET tmp_str = SUBSTRING(tmp_str,2); #计算当前字符串长度 SET tmp_len = LENGTH(tmp_str); END WHILE; #返回结果字符串 RETURN tmp_rs; END$$ DELIMITER ;
[b]4:函数的使用效果[/b]
[b]
[/b]
[b]5:理解函数思想的参看资料[/b]
[b]http://www.4jhm.com/hzcode/queryg.php?enter=CED2[/b]
[b]http://zd.diyifanwen.com/zidian/py/[/b]
[b]http://www.qqxiuzi.cn/zh/hanzi-gbk-bianma.php[/b]
[b]6:函数说明[/b]
[b]整个函数,如果明白了各个系统函数的使用方式,就没有什么不好理解的了,就有一个函数的使用有些不太好理解,如下所示:[/b]
SET tmp_loc=INTERVAL(CONV(HEX(tmp_char),16,10), 0xB0A1,0xB0C5,0xB2C1,0xB4EE,0xB6EA,0xB7A2,0xB8C1,0xB9FE,0xBBF7,0xBFA6,0xC0AC,0xC2E8,0xC4C3,0xC5B6,0xC5BE,0xC6DA,0xC8BB,0xC8F6,0xCBFA,0xCDDA ,0xCEF4,0xD1B9,0xD4D1); 这个函数的功能是比较简单的,就是[b]进行比较列表(N1,N2,N3等等)中的N值。该函数如果N<N1返回0,如果N<N2返回1,如果N<N3返回2 等等。如果N为NULL,它将返回-1。列表值必须是N1<N2<N3的形式才能正常工作。 如下表所示,就是函数中N1/N2/N3等等所表示的含义,如何通过 GBK编码表 就能比较好的理解了,这些GBK编码表示的汉字都是对应的字母开头的拼音中的第一个汉字,通过这种方式就能判断出一个汉字的拼音首字母是那个字母了。[/b]
| 序号 | GBK内码 | Uni码 | 汉字 | 字符集 |
| 1 | B0A1 | 554A | 啊 | GBK |
| 2 | B0C5 | 82AD | 芭 | GBK |
| 3 | B2C1 | 64E6 | 擦 | GBK |
| 4 | B4EE | 642D | 搭 | GBK |
| 5 | B6EA | 86FE | 蛾 | GBK |
| 6 | B7A2 | 53D1 | 发 | GBK |
| 7 | B8C1 | 5676 | 噶 | GBK |
| 8 | B9FE | 54C8 | 哈 | GBK |
| 9 | BBF7 | 51FB | 击 | GBK |
| 10 | BFA6 | 5580 | 喀 | GBK |
| 11 | C0AC | 5783 | 垃 | GBK |
| 12 | C2E8 | 5988 | 妈 | GBK |
| 13 | C4C3 | 62FF | 拿 | GBK |
| 14 | C5B6 | 54E6 | 哦 | GBK |
| 15 | C5BE | 556A | 啪 | GBK |
| 16 | C6DA | 671F | 期 | GBK |
| 17 | C8BB | 7136 | 然 | GBK |
| 18 | C8F6 | 6492 | 撒 | GBK |
| 19 | CBFA | 584C | 塌 | GBK |
| 20 | CDDA | 6316 | 挖 | GBK |
| 21 | CEF4 | 6614 | 昔 | GBK |
| 22 | D1B9 | 538B | 压 | GBK |
| 23 | D4D1 | 531D | 匝 | GBK |

相关文章推荐
- MySQL的集群配置的基本命令使用及一次操作过程实录
- mysql 表大小写
- mysql 5.7忘记root密码
- mysql 5.7使用ssl连接
- 安装MySQL配置时报错的处理方法
- MySQL是否在扫描额外的记录
- MySQL常用的操作整理
- 21分钟 MySQL 入门教程
- 如何增mysql innodb_data 文件的空间
- mac osx install mysql
- solr5.3.1从mysql导入索引
- mysql innodb ibdata 数据文件误删除恢复过程
- 10款最好用的MySQL数据库客户端图形界面管理工具
- 数据库使用总结 Sql sever ,mysql,sqlite
- 记一次MySQL手工注入案例
- mysql-5.7新版本尝鲜
- 命令行登录远程Mysql
- Mysql查询缓存碎片、缓存命中率及Nagios监控
- mysql数据库常用命令学习
- mysql中文乱码